Just today it has published a status update of the Vulkan effort for the Raspberry Pi 4, including that we are moving the development of the driver to an open repository. As it is really likely that some people would be interested on testing it, even if it is not complete at all, here you can find a quick guide to compile it, and get some demos running.
Dependencies
So let’s start installing some dependencies. My personal recipe, that I use every time I configure a new machine to work on mesa is the following one (sorry if some extra unneeded dependencies slipped):
sudo apt-get install libxcb-randr0-dev libxrandr-dev \
libxcb-xinerama0-dev libxinerama-dev libxcursor-dev \
libxcb-cursor-dev libxkbcommon-dev xutils-dev \
xutils-dev libpthread-stubs0-dev libpciaccess-dev \
libffi-dev x11proto-xext-dev libxcb1-dev libxcb-*dev \
bison flex libssl-dev libgnutls28-dev x11proto-dri2-dev \
x11proto-dri3-dev libx11-dev libxcb-glx0-dev \
libx11-xcb-dev libxext-dev libxdamage-dev libxfixes-dev \
libva-dev x11proto-randr-dev x11proto-present-dev \
libclc-dev libelf-dev git build-essential mesa-utils \
libvulkan-dev ninja-build libvulkan1 python-mako \
libdrm-dev libxshmfence-dev libxxf86vm-dev \
python3-mako
Most Raspian libraries are recent enough, but they have been updating some of then during the past months, so just in case, don’t forget to update:
$ sudo apt-get update
$ sudo apt-get upgrade
Additionally, you woud need to install meson. Mesa has just recently bumped up the version needed for meson, so Raspbian version is not enough. There is the option to build meson from the tarball (meson-0.52.0 here), but by far, the easier way to get a recent meson version is using pip3:
$ pip3 install meson
2020-07-04 update
It seems that some people had problems if they have installed meson with apt-get on their system, as when building it would try the older meson version first. For those people, they were able to fix that doing this:
$ sudo apt-get remove meson
$ pip3 install --user meson
Download and build v3dv
This is the simpler recipe to build v3dv:
$ git clone https://gitlab.freedesktop.org/apinheiro/mesa.git mesa
$ cd mesa
$ git checkout wip/igalia/v3dv
$ meson --prefix /home/pi/local-install --libdir lib -Dplatforms=x11,drm -Dvulkan-drivers=broadcom -Ddri-drivers= -Dgallium-drivers=v3d,kmsro,vc4 -Dbuildtype=debug _build
$ ninja -C _build
$ ninja -C _build install
2020-11-25 update
Now v3dv is merged on Mesa upstream, so in order to clone the repository now you just need to do this:
$ git clone https://gitlab.freedesktop.org/mesa/mesa.git
This builds and install a debug version of v3dv on a local directory. You could set a release build, or any other directory. The recipe is also building the OpenGL driver, just in case anyone want to compare, but if you are only interested on the vulkan driver, that is not mandatory.
Run some Vulkan demos
Now, the easiest way to ensure that a vulkan program founds the drivers is setting the following envvar:
export VK_ICD_FILENAMES=/home/pi/local-install/share/vulkan/icd.d/broadcom_icd.armv7l.json
That envvar is used by the Vulkan loader (installed as one of the dependencies listed before) to know which library load. This also means that you don’t need to use LD_PRELOAD, LD_LIBRARY_PATH or similar
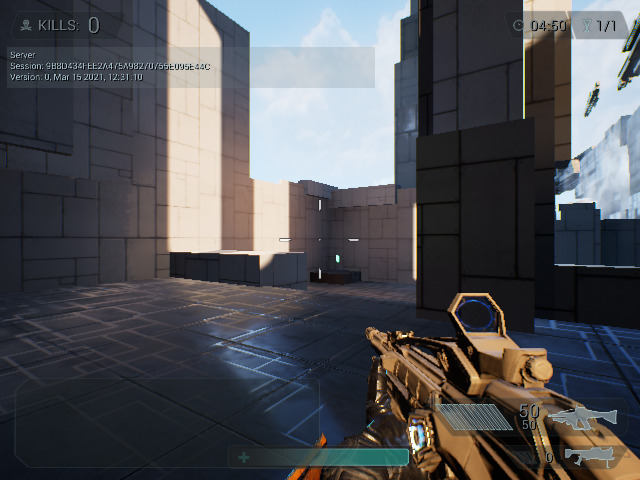
So what Vulkan programs are working? For example several of the Sascha Willem Vulkan demos. To make things easier to everybody, here another quick recipe of how to get them build:
$ sudo apt-get install libassimp-dev
$ git clone --recursive https://github.com/SaschaWillems/Vulkan.git sascha-willems
$ cd sascha-willems
$ mkdir build; cd build
$ cmake -DCMAKE_BUILD_TYPE=Debug ..
$ make
Update 2020-08-03: When the post was originally written, some demos didn’t need to ask for extra assets. Recently the fonts were moved there, so you would need to gather the assests always:
$ cd ..
$ python3 download_assets.py
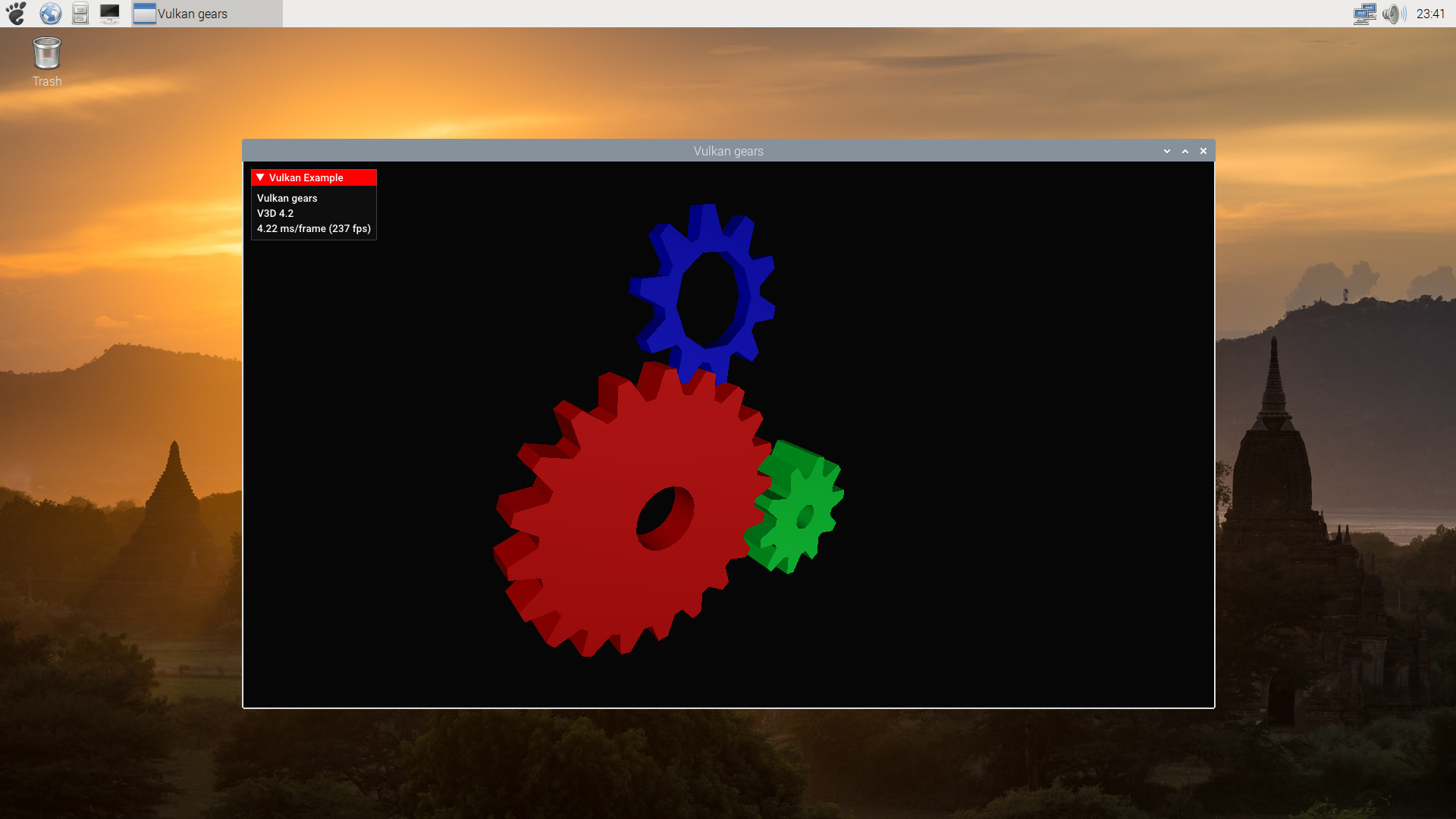
So in order to see a really familiar demo:
$ cd build/bin
$ ./gears
And one slightly more complex:
$./scenerendering
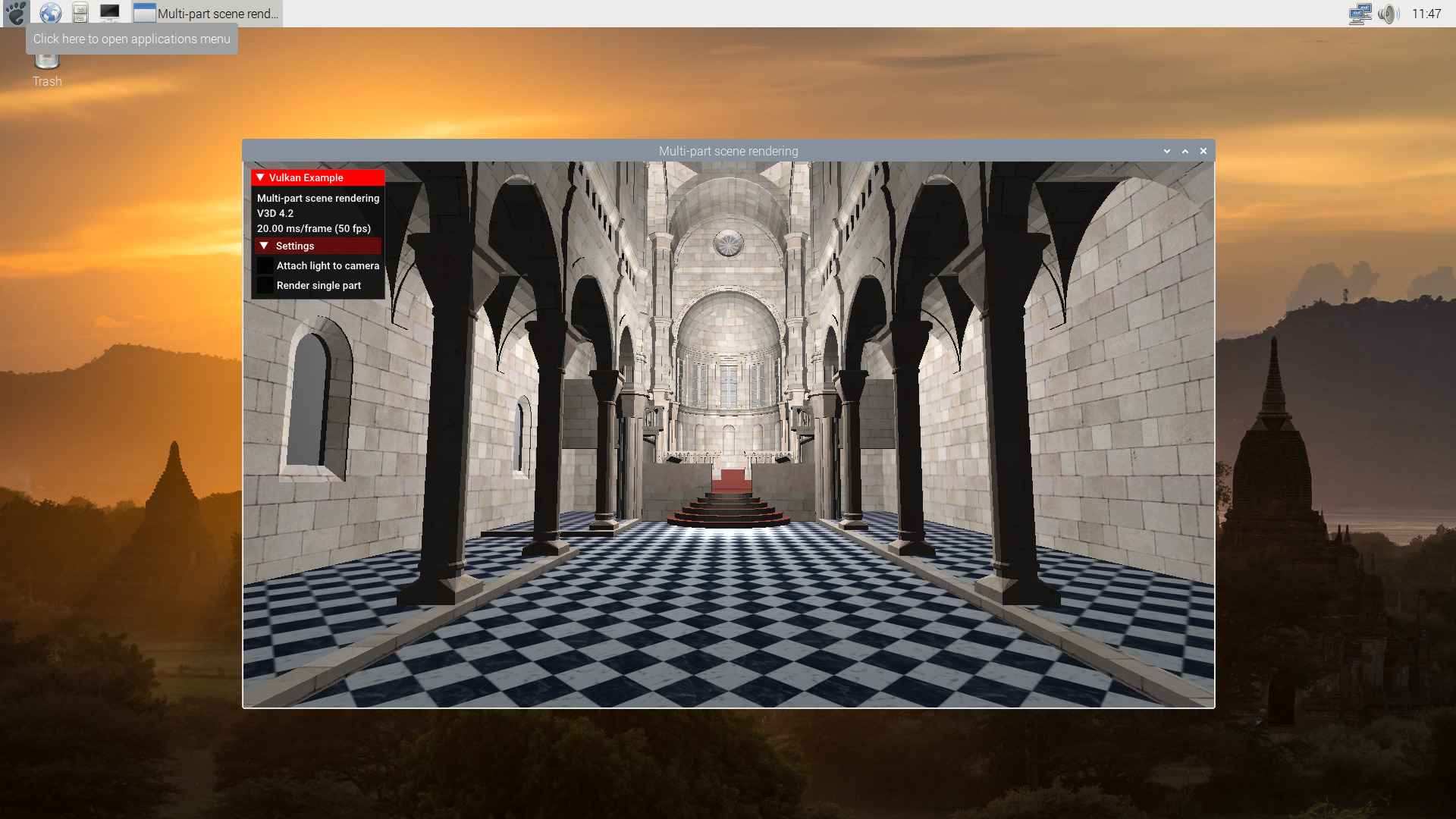
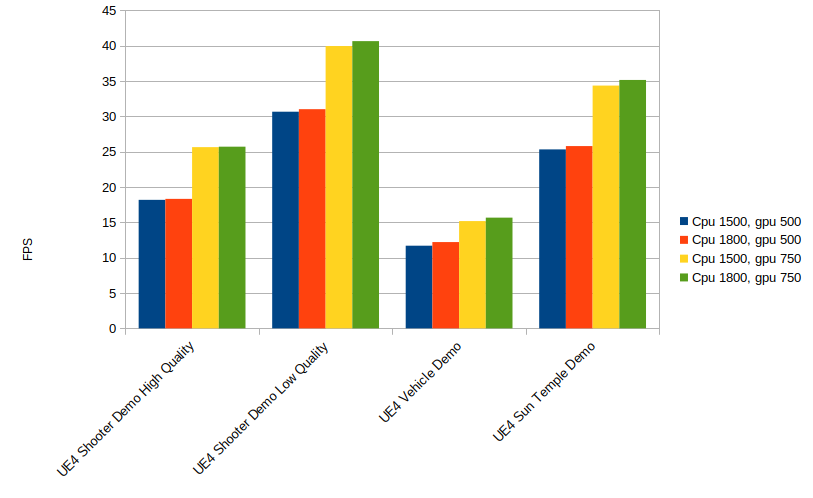
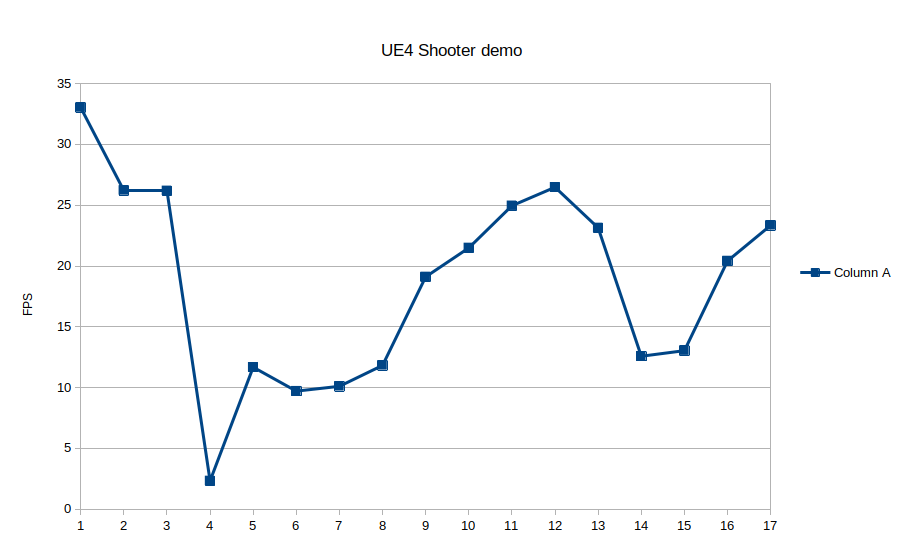
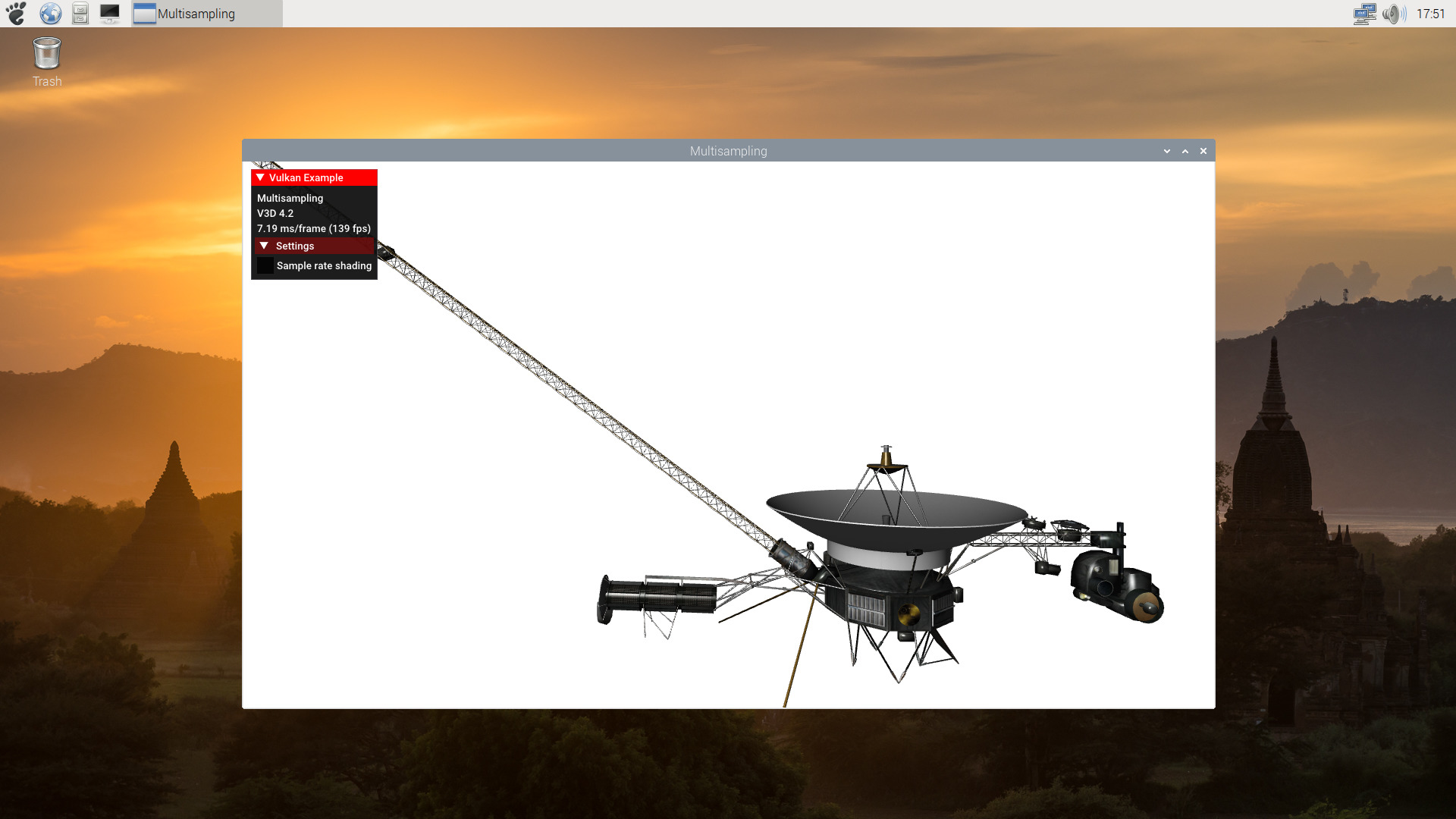
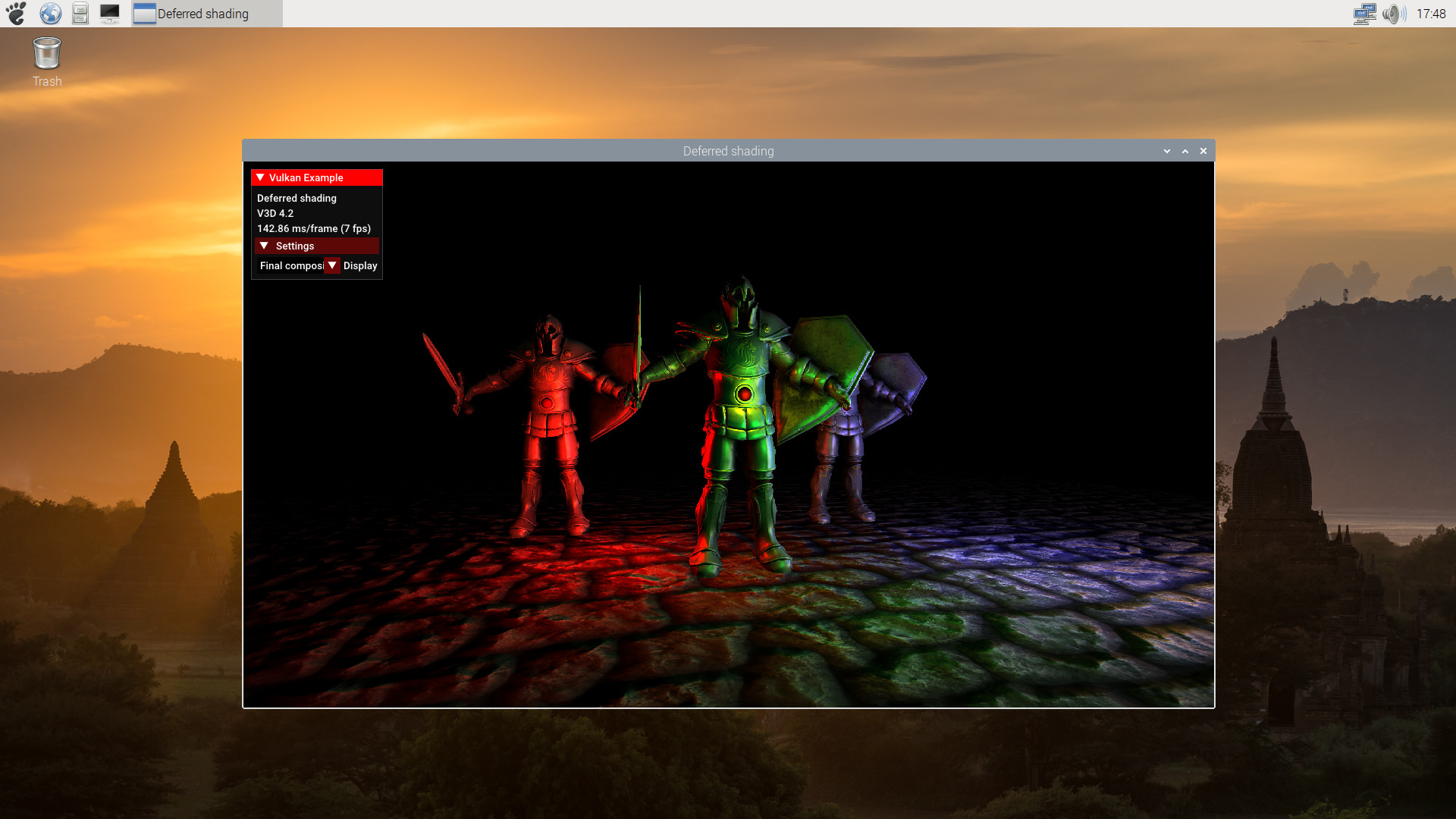
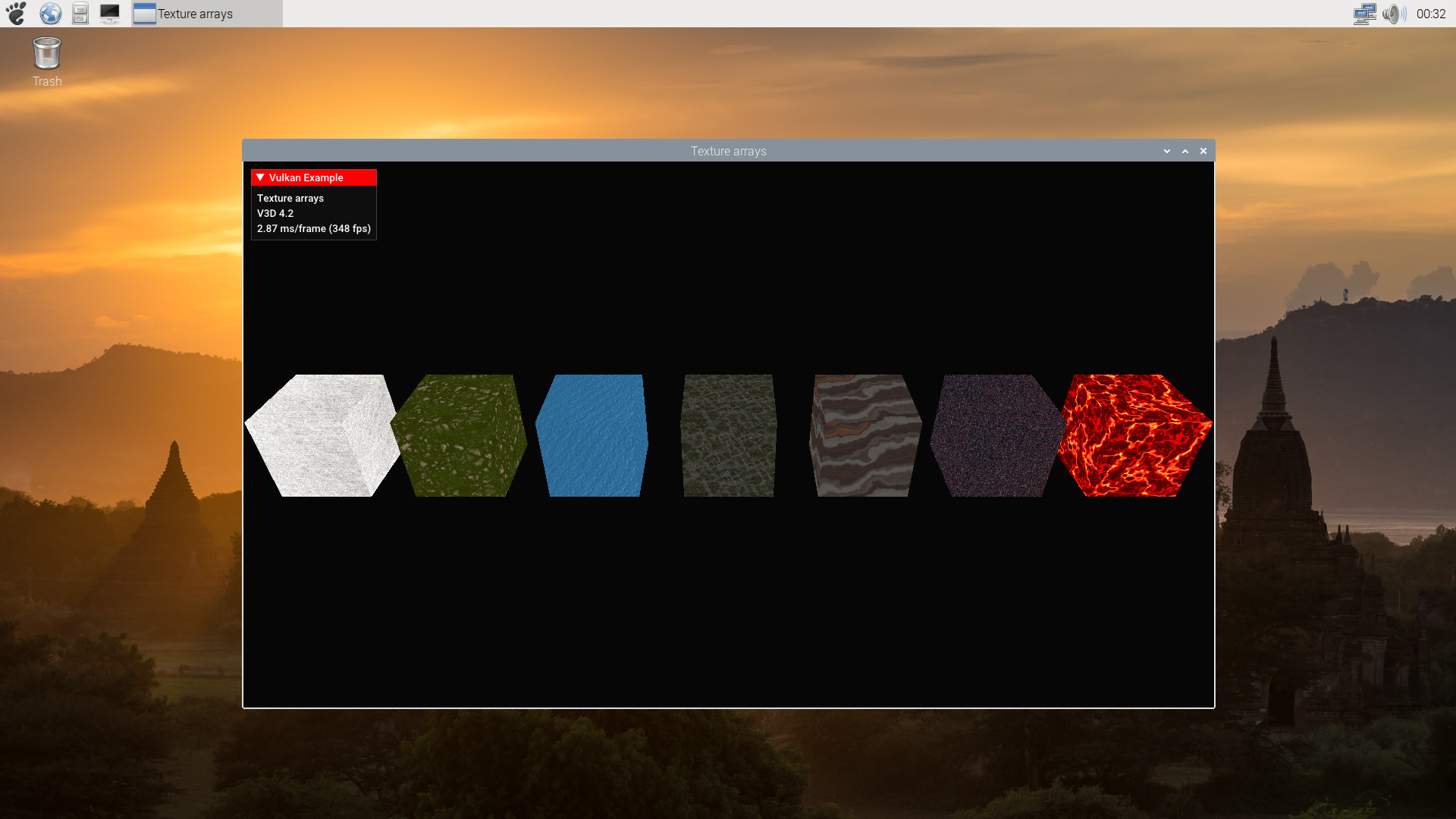
As mentioned, not all the demos works. But a list of some that we tested and seem to work:
* distancefieldfonts
* descriptorsets
* dynamicuniformbuffer
* gears
* gltfscene
* imgui
* indirectdraw
* occlusionquery
* parallaxmapping
* pbrbasic
* pbribl
* pbrtexture
* pushconstants
* scenerendering
* shadowmapping
* shadowmappingcascade
* specializationconstants
* sphericalenvmapping
* stencilbuffer
* textoverlay
* texture
* texture3d
* texturecubemap
* triangle
* vulkanscene
Update : rpiMike on the comments, and some people privately, have pointed some errors on the post. Thanks! And sorry for the inconvenience.
Update 2 : Mike Hooper pointed more issues on gitlab