We haven’t posted updates to the work done on the V3DV driver since
we announced the driver becoming Vulkan 1.1 Conformant.
But after reaching that milestone, we’ve been very busy working on more improvements, so let’s summarize the work done since then.
Multisync support
As mentioned on past posts, for the Vulkan driver we tried to focus as much as possible on the userspace part. So we tried to re-use the already existing kernel interface that we had for V3D, used by the OpenGL driver, without modifying/extending it.
This worked fine in general, except for synchronization. The V3D kernel interface only supported one synchronization object per submission. This didn’t properly map with Vulkan synchronization, which is more detailed and complex, and allowed defining several semaphores/fences. We initially handled the situation with workarounds, and left some optional features as unsupported.
After our 1.1 conformance work, our colleage Melissa Wen started to work on adding support for multiple semaphores on the V3D kernel side. Then she also implemented the changes on V3DV to use this new feature. If you want more technical info, she wrote a very detailed explanation on her blog (part1 and part2).
For now the driver has two codepaths that are used depending on if the kernel supports this new feature or not. That also means that, depending on the kernel, the V3DV driver could expose a slightly different set of supported features.
More common code – Migration to the common synchronization framework
For a while, Mesa developers have been doing a great effort to refactor and move common functionality to a single place, so it can be used by all drivers, reducing the amount of code each driver needs to maintain.
During these months we have been porting V3DV to some of that infrastructure, from small bits (common VkShaderModule to NIR code), to a really big one: common synchronization framework.
As mentioned, the Vulkan synchronization model is really detailed and powerful. But that also means it is complex. V3DV support for Vulkan synchronization included heavy use of threads. For example, V3DV needed to rely on a CPU wait (polling with threads) to implement vkCmdWaitEvents, as the GPU lacked a mechanism for this.
This was common to several drivers. So at some point there were multiple versions of complex synchronization code, one per driver. But, some months ago, Jason Ekstrand refactored Anvil support and collaborated with other driver developers to create a common framework. Obviously each driver would have their own needs, but the framework provides enough hooks for that.
After some gitlab and IRC chats, Jason provided a Merge Request with the port of V3DV to this new common framework, that we iterated and tested through the review process.
Also, with this port we got timelime semaphore support for free. Thanks to this change, we got ~1.2k less total lines of code (and have more features!).
Again, we want to thank Jason Ekstrand for all his help.
Support for more extensions:
Since 1.1 got announced the following extension got implemented and exposed:
- VK_EXT_debug_utils
- VK_KHR_timeline_semaphore
- VK_KHR_create_renderpass2
- VK_EXT_4444_formats
- VK_KHR_driver_properties
- VK_KHR_16_bit_storage and VK_KHR_8bit_storage
- VK_KHR_imageless_framebuffer
- VK_KHR_depth_stencil_resolve
- VK_EXT_image_drm_format_modifier
- VK_EXT_line_rasterization
- VK_EXT_inline_uniform_block
- VK_EXT_separate_stencil_usage
- VK_KHR_separate_depth_stencil_layouts
- VK_KHR_pipeline_executable_properties
- VK_KHR_shader_float_controls
- VK_KHR_spirv_1_4
If you want more details about VK_KHR_pipeline_executable_properties, Iago wrote recently a blog post about it (here)
Android support
Android support for V3DV was added thanks to the work of Roman Stratiienko, who implemented this and submitted Mesa patches. We also want to thank the Android RPi team, and the Lineage RPi maintainer (Konsta) who also created and tested an initial version of that support, which was used as the baseline for the code that Roman submitted. I didn’t test it myself (it’s in my personal TO-DO list), but LineageOS images for the RPi4 are already available.
Performance
In addition to new functionality, we also have been working on improving performance. Most of the focus was done on the V3D shader compiler, as improvements to it would be shared among the OpenGL and Vulkan drivers.
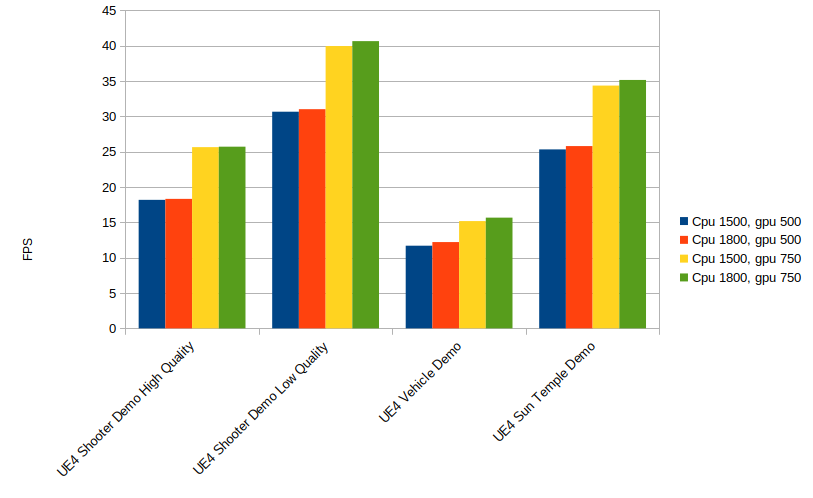
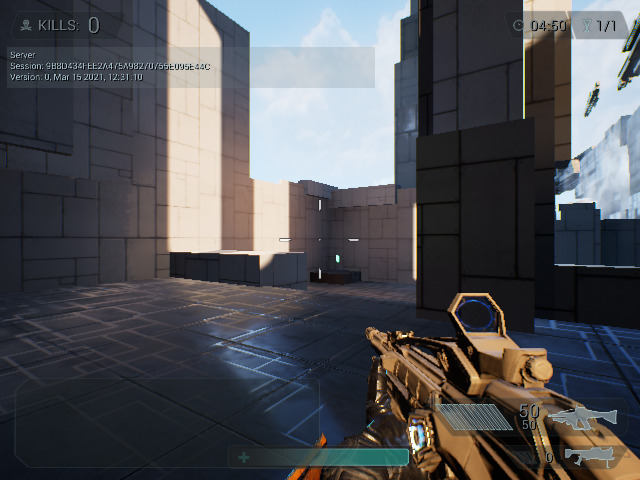
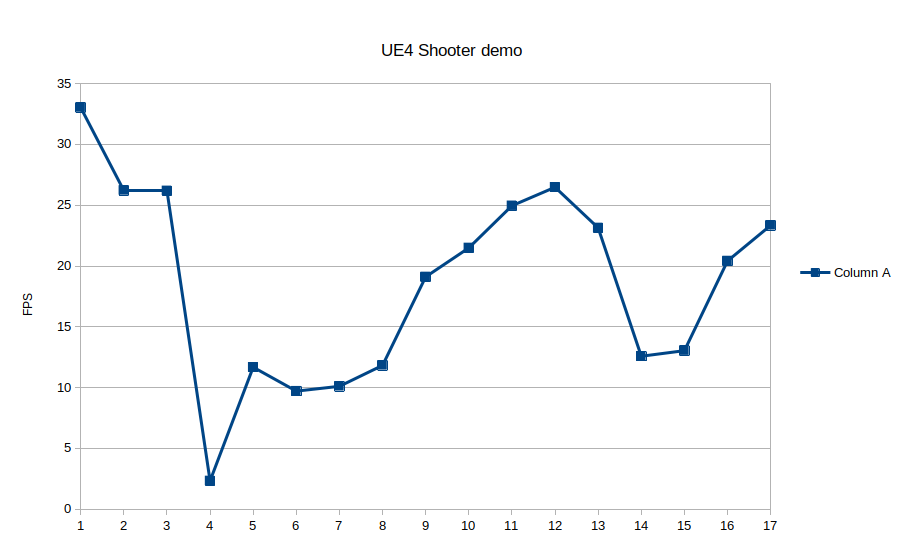
But one of the features specific to the Vulkan driver (pending to be ported to OpenGL), is that we have implemented double buffer mode, only available if MSAA is not enabled. This mode would split the tile buffer size in half, so the driver could start processing the next tile while the current one is being stored in memory.
In theory this could improve performance by reducing tile store overhead, so it would be more benefitial when vertex/geometry shaders aren’t too expensive. However, it comes at the cost of reducing tile size, which also causes some overhead on its own.
Testing shows that this helps in some cases (i.e the Vulkan Quake ports) but hurts in others (i.e. Unreal Engine 4), so for the time being we don’t enable this by default. It can be enabled selectively by adding V3D_DEBUG=db to the environment variables. The idea for the future would be to implement a heuristic that would decide when to activate this mode.
FOSDEM 2022
If you are interested in watching an overview of the improvements and changes to the driver during the last year, we made a presention in FOSDEM 2022:
“v3dv: Status Update for Open Source Vulkan Driver for Raspberry Pi
4”