I was at XDC 2023 in A Coruña a few days ago where I had the opportunity to talk about some of the work we have been doing on the Raspberry Pi driver stack together with my colleagues Juan Suárez and Maíra Canal. We talked about Raspberry Pi 5, CPU job handling in the Vulkan driver, OpenGL 3.1 support and how we are exposing GPU stats to user space. If you missed it here is the link to Youtube.
Big thanks to Igalia for organizing it and to all the sponsors and specially to Samuel and Chema for all the work they put into making this happen.
The latest SuperTuxKart release comes with an experimental Vulkan renderer and I was eager to check it out on my Raspbery Pi 4 and see how well it worked.
The short story is that while I have only tested a few tracks it seems to perform really well overall. In my tests, even with a debug build of Mesa I saw the FPS ranging from 60 to 110 depending on the track. I think the game might be able to produce more than 110 fps actually, since various tracks were able to reach exactly 110 fps I think the limiting factor here was the display.
I was then naturally interested in comparing this to the GL renderer and I was a bit surprised to see that, with the same settings, the GL renderer would be somewhere in the 8-20 fps range for the same tracks. The game was clearly hitting a very bad path in the GL driver so I had to fix that before I could make a fair comparison between both.
A perf session quickly pointed me to the issue: Mesa has code to transparently translate vertex attribute formats that are not natively supported to a supported format. While this is great for compatibility it is obviously going to be very slow. In particular, SuperTuxKart uses rgba16f and rg16f with some vertex buffers and Mesa was silently translating these to 32-bit counterparts because the GL driver was not advertising support for the 16-bit variants. The hardware does support 16-bit floating point vertex attributes though, so this was very easy to fix.
The Vulkan driver was exposing support for this already, which explains the dramatic difference in performance between both drivers. Indeed, with that change SuperTuxKart now plays smooth on OpenGL too, with framerates always above 30 fps and up to 110 fps depending on the track. We should probably have an option in Mesa to make this kind of under-the-hood compatibility translations more obvious to users so we can catch silly issues like this more easily.
With that said, even if GL is now a lot better, Vulkan is still ahead by quite a lot, producing 35-50% better framerate than OpenGL depending on the track, at least for the tracks that don’t hit the 110 fps mark, which as I said above, looks like it is a display maximum, at least with my setup.
Zink
During my presentation at XDC last year I mentioned Zink wasn’t supported on Raspberry Pi 4 any more due to feature requirements we could not fulfill.
In the past, Zink used to abort when it detected unsupported features, but it seems this policy has been changed and now it simply drops a warning and points to the possibility of incorrect rendering as a result.
Also, I have been talking to zmike about one of the features we could not support natively: scalarBlockLayout. Particularly, the issue with this is that we can’t make it work with vectors in all cases and the only alternative for us would be to scalarize everything through a lowering, which would probably have a performance impact. However, zmike confirmed that Zink is already doing this, so in practice we would not see vector load/stores from Zink, in which case it should work fine .
So with all that in mind, I did give Zink a go and indeed, I get the warning that we don’t support scalar block layouts (and some other feature I don’t remember now) but otherwise it mostly works. It is not as stable as the native driver and some things that work with the native driver don’t work with Zink at present, some examples I saw include the WebGL Aquarium demo in Chromium or SuperTuxKart.
As far as performance goes, it has been a huge leap from when I tested it maybe 2 years ago. With VkQuake3‘s OpenGL renderer performance with Zink used to be ~40% of the native OpenGL driver, but is now on par with it, even if not a tiny bit better, so kudos to zmike and all the other contributors to Zink for all the work they put into this over the last 2 years, it really shows.
With all that said, I didn’t do too much testing with Zink myself so if anyone here decides to give it a more thorough go, please let me know how it went in the comments.
A quick update on my latest activities around V3DV: I’ve been focusing on getting the driver ready for Vulkan 1.2 conformance, which mostly involved fixing a few CTS tests of the kind that would only fail occasionally, these are always fun :). I think we have fixed all the issues now and we are ready to submit conformance to Khronos, my colleague Alejandro Piñeiro is now working on that.
Lately I have been exposing a bit more functionality in V3DV and was wondering how far we are from Vulkan 1.2. Turns out that a lot of the new Vulkan 1.2 features are actually optional and what we have right now (missing a few trivial patches to expose a few things) seems to be sufficient for a minimal implementation.
We actually did a test run with CTS enabling Vulkan 1.2 to verify this and it went surprisingly well, with just a few test failures that I am currently looking into, so I think we should be able to submit conformance soon.
For those who may be interested, here is a list of what we are not supporting (all of these are optional features in Vulkan 1.2):
VK_EXT_descriptor_indexing
I think we should be able to support this in the future.
VK_KHR_shader_float16_int8
This we can support in theory, since the hardware has support for half-float, however, the way this is designed in hardware comes with significant caveats that I think would make it really difficult to take advantage of it in practice. It would also require significant work, so it is not something we are planning at present.
VK_KHR_buffer_device_address
We can’t implement this without hacks because the Vulkan spec explicitly defined these addresses to be 64-bit values and the V3D GPU only deals with 32-bit addresses and is not capable of doing any kind of native 64-bit operation. At first I thought we could just lower these to 32-bit (since we know they will be 32-bit), but because the spec makes these explicit 64-bit values, it allows shaders to cast a device address from/to uvec2, which generates 64-bit bitcast instructions and those require both the destination and source to be 64-bit values.
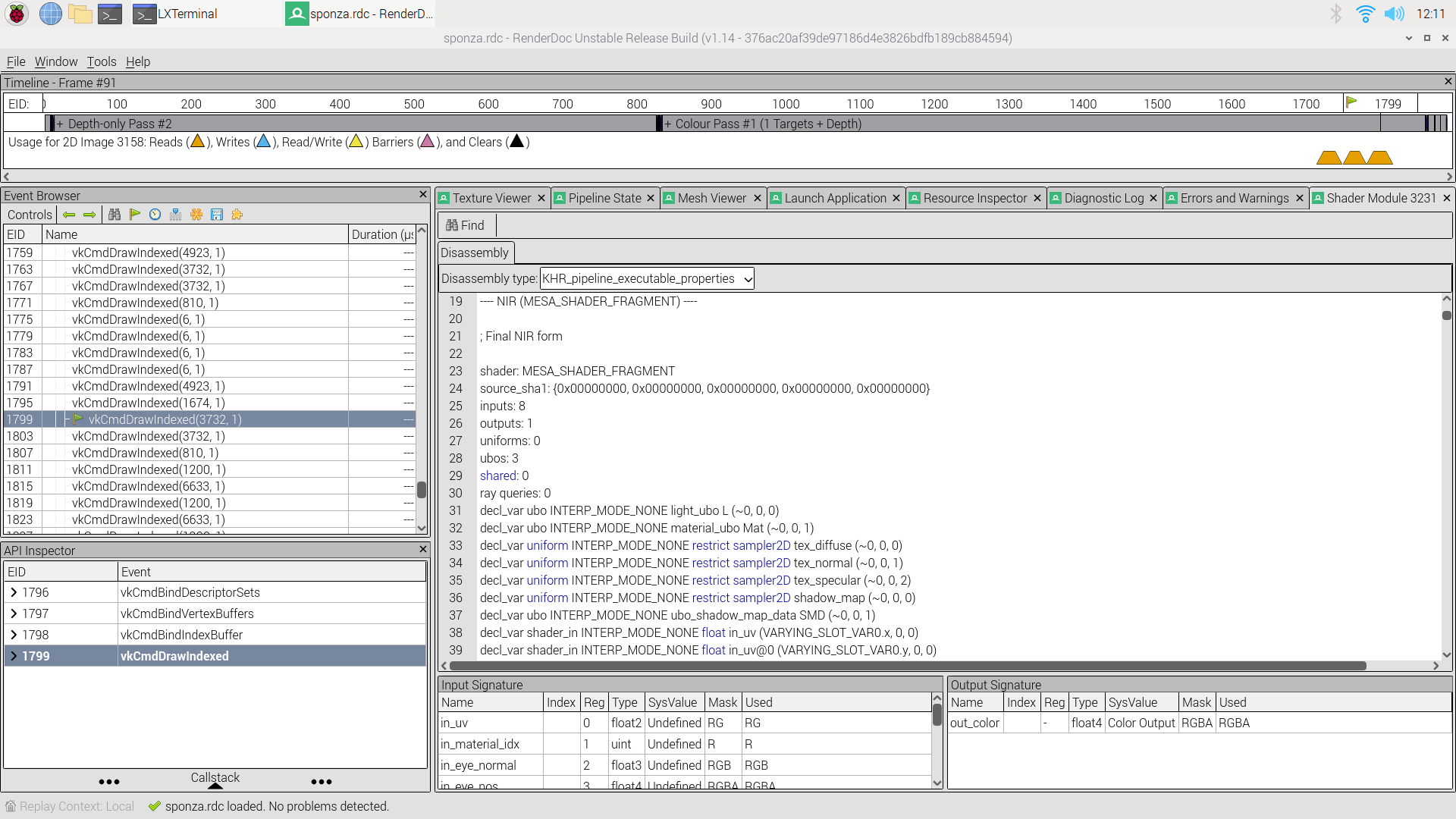
Sometimes you want to go and inspect details of the shaders that are used with specific draw calls in a frame. With RenderDoc this is really easy if the driver implements VK_KHR_pipeline_executable_properties. This extension allows applications to query the driver about various aspects of the executable code generated for a Vulkan pipeline.
I implemented this extension for V3DV, the Vulkan driver for Raspberry Pi 4, last week (it is currently in review process) because I was tired of jumping through loops to get the info I needed when looking at traces. For V3DV we expose the NIR and QPU assembly code as well as various others stats, some of which are quite relevant to performance, such as spill or thread counts.
I’ve been silent here for quite some time, so here is a quick summary of some of the new functionality we have been exposing in V3DV, the Vulkan driver for Raspberry PI 4, over the last few months:
VK_KHR_bind_memory2
VK_KHR_copy_commands2
VK_KHR_dedicated_allocation
VK_KHR_descriptor_update_template
VK_KHR_device_group
VK_KHR_device_group_creation
VK_KHR_external_fence
VK_KHR_external_fence_capabilities
VK_KHR_external_fence_fd
VK_KHR_external_semaphore
VK_KHR_external_semaphore_capabilities
VK_KHR_external_semaphore_fd
VK_KHR_get_display_properties2
VK_KHR_get_memory_requirements2
VK_KHR_get_surface_capabilities2
VK_KHR_image_format_list
VK_KHR_incremental_present
VK_KHR_maintenance2
VK_KHR_maintenance3
VK_KHR_multiview
VK_KHR_relaxed_block_layout
VK_KHR_sampler_mirror_clamp_to_edge
VK_KHR_storage_buffer_storage_class
VK_KHR_uniform_buffer_standard_layout
VK_KHR_variable_pointers
VK_EXT_custom_border_color
VK_EXT_external_memory_dma_buf
VK_EXT_index_type_uint8
VK_EXT_physical_device_drm
Besides that list of extensions, we have also added basic support for Vulkan subgroups (this is a Vulkan 1.1 feature) and Geometry Shaders (we use this to implement multiview).
I think we now meet most (if not all) of the Vulkan 1.1 mandatory feature requirements, but we still need to check this properly and we also need to start doing Vulkan 1.1 CTS runs and fix test failures. In any case, the bottom line is that Vulkan 1.1 should be fairly close now.
Lately, I have been looking at improving performance of the V3DV Vulkan driver for the Raspberry Pi 4. So far we had been toying a lot with some Vulkan ports of the Quake trilogy but we wanted to have a look at more modern games as well, and for that we started to look at some Unreal Engine 4 samples, particularly the Shooter demo.
Unreal Engine 4 Shooter Demo
In our initial tests with “High” settings, even at 480p we were running the sample at 8-15 fps, with 720p being mostly in the 5-10 fps range. Not great, obviously, but a good opportunity to guide and focus our performance efforts.
One aspect of the UE4 sample that was immediately obvious compared to the Quake games is that the shading is a lot more expensive in general, and more specifically, it involves more texture lookups and UBO loads, which require expensive accesses to memory from the shader cores, so this was the first area we targeted. The good thing about this is that because our Vulkan and OpenGL drivers share the compiler stack, any optimizations we do here benefit both drivers.
What follows is a brief discussion of some of the optimizations we did recently to our backend compiler and the results we have observed from this work.
Optimizing the backend compiler
So the first thing we tackled was better managing the latency of texture lookups. Interestingly, the NIR scheduler was setting this up so that we would try to put instructions that consumed the result of a texture lookup as far away as possible from the instruction that triggered the lookup, but then the backend compiler was not fully taking advantage of this and would still end up waiting on lookup results sooner than it should.
Fixing this helped performance by 1%-3%, although it could go a bit above that in some cases. It has a caveat though: doing this extends the liveness of our lookup sequences, and that makes spilling more difficult (we can’t emit spills/unspills in the middle of an outstanding memory lookup), so when register pressure is high enough that we need to inject register spills to compile the shader, we would typically be a lot more constrained and end up producing significantly worse code, or even worse, failing to register allocate for the shader completely. To avoid this, we recompile the shader without the optimization if we detect that we need to do any spilling. One can use V3D_DEBUG=perf to detect if this is happening for any shaders, looking for messages like this:
Falling back to strategy 'disable TMU pipelining' for MESA_SHADER_FRAGMENT.
While the above optimization was useful, I was expecting that it would make a larger impact for this particular demo so I kept looking for ways to do our memory lookups more efficient. One thing that is relevant to this analysis is that we were using the same hardware unit for both texture and UBO lookups, but for the latter, we could really use a different strategy by handling our UBOs as uniform streams. This has some caveats, but making a long story short, the fact that many UBO loads use uniform addresses, that we usually read a bunch of consecutive scalars from a UBO load (such as a full vec4) and that applications usually emit UBO loads for nearby addresses together, we can emit fairly optimal code for many of these, leading to more efficient memory access in general.
Eventually, this turned out to be a big win, yielding 20%-30% improvements for the Shooter demo even with the initial basic implementation, which we would then tune and optimize further.
Again related to memory accesses, I have also been improving how we schedule instructions involved with setting up memory lookups. Our scheduler was more restrictive here than it needed, and the extra flexibility can help reduce instruction counts, which will affect these more modern games most, as they are more likely to emit a larger number of texture/image operations in their shaders.
Another thing we did was to improve instruction packing. The V3D GPU is able to emit multiple instructions in the same cycle so long as the instructions meet some requirements. Turns out our assembly scheduler was being too restrictive with this and we could do better. Going by shader-db results, this led to ~5% less instructions on our programs and added another modest 1%-2% performance improvement for the Shooter demo.
Another issue we noticed is that a lot of the shaders were passing a lot of varyings from the vertex to fragment shaders, and our setup for fragment shader inputs was not optimal. The issue here was that there is a specific instruction involved in this process that writes two registers, one of then with an instruction of delay, and our dependency tracking was not able to handle this properly, effectively assuming that both registers are written in the same instruction which then had an impact in how we scheduled instructions. Fixing this required to handle this case specially in our scheduler so we could be more effective at scheduling these instructions in a way that would enable optimal pipelining of the instructions involved with varying setups for fragment shaders.
Another aspect we improved was related to our uniform handling. Generally, there many instances in which we need to emit duplicate uniforms. There are reasons for that related to how the GPU works, but in some cases, for example with consecutive UBO loads, we would emit the uniform with the base address of the UBO multiple times very close to each other. We can obviously do better by trying to track previous uses of a uniform/constant value and reusing them in nearby instructions. Of course, this comes at the expense of increasing register pressure (for reasons beyond the scope of this post our shaders typically require a lot of uniforms), so there is a balancing game to play here too. Reducing the size of our uniform streams this way also plays an important role in lowering some of the CPU overhead of the driver, since these streams need to be rebuilt often when certain pipeline states change.
Finally, an optimization that was more targeted at reducing register pressure rather than improving performance: we noticed that we would sometimes put some instructions far away from their consumers with no obvious benefit to it. This was bad enough some times that it would even cause us to be unable to compile some shaders. Mesa has a handy NIR pass for this called nir_opt_sink, which also proved to be helpful for this. This allowed us to get a few more shaders from shader-db to compile and reduce spilling for a bunch of shaders. For the Shooter demo, this changed a large compute shader involved with histogram post-processing, which had 48 spills and 50 fills to only have 8 spills and 15 fills. While the impact in performance of this is probably very small since the game only runs this pass once per frame, it made a notable difference in loading time, since compiling a shader with this much spilling is very slow at present. I have a mental note to improve this some day, I know Intel managed to fix this for their compiler, but for the time being, this alone managed to make the loading time much more reasonable.
Results
First, here are some shader-db stats, which describe how these optimizations change various statistics for a large collections of real world shaders:
total instructions in shared programs: 14992758 -> 13731927 (-8.41%)
instructions in affected programs: 14003658 -> 12742827 (-9.00%)
helped: 80448
HURT: 4297
total threads in shared programs: 407932 -> 412242 (1.06%)
threads in affected programs: 4514 -> 8824 (95.48%)
helped: 2189
HURT: 34
total uniforms in shared programs: 4069524 -> 3790401 (-6.86%)
uniforms in affected programs: 2267834 -> 1988711 (-12.31%)
helped: 40588
HURT: 1186
total max-temps in shared programs: 2388462 -> 2322009 (-2.78%)
max-temps in affected programs: 897803 -> 831350 (-7.40%)
helped: 30598
HURT: 2464
total spills in shared programs: 6241 -> 5940 (-4.82%)
spills in affected programs: 3963 -> 3662 (-7.60%)
helped: 75
HURT: 24
total fills in shared programs: 14587 -> 13372 (-8.33%)
fills in affected programs: 11192 -> 9977 (-10.86%)
helped: 90
HURT: 14
total sfu-stalls in shared programs: 28106 -> 31489 (12.04%)
sfu-stalls in affected programs: 16039 -> 19422 (21.09%)
helped: 4382
HURT: 6429
total inst-and-stalls in shared programs: 15020864 -> 13763416 (-8.37%)
inst-and-stalls in affected programs: 14028723 -> 12771275 (-8.96%)
helped: 80396
HURT: 4305
Less is better for all stats, except threads. We can see significant improvements across the board: we generally produce shaders with less instructions that have less maximum register pressure, we reduce spills and uniform counts and can run with more threads. We only are worse at stalls, but that is generally because we now produce more compact code with less instructions, so more stalls are expected.
Another good thing in these stats is the large number of helped shaders compared to hurt shaders, meaning that it is very likely that these optimizations will help most applications to some extent.
But enough of boring compiler statistics, most people won’t care about that and what they want to know is how this impacts performance on actual games and applications, which is what the following graphs shows (these were obtained by replaying specific traces with gfx-reconstruct). Keep in mind that while I am using a collection of Vulkan samples/games here it is expected that these optimizations apply to OpenGL too.
Before vs After
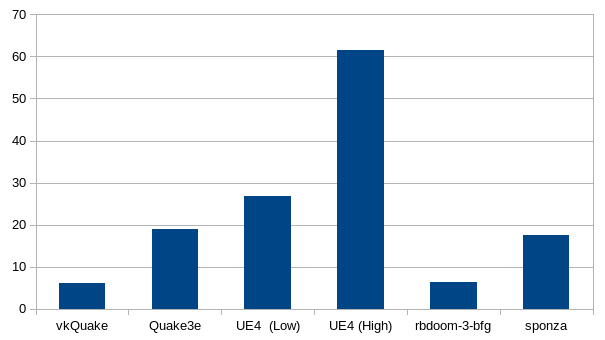
Framerate improvement after optimization (in %)
As it can be observed from the graph above, this optimization work made a significant impact in the observed framerate in all the cases. It is not surprising that the UE4 demo is the one that sees the most improvement, considering this the one we used to guide most of the optimization work.
Other optimizations and future work
In this post I have been focusing exclusively on compiler optimizations, but we have also been improving other parts of the Vulkan driver. While I won’t go into details to avoid making this post too long, we have also been improving aspects of the driver involved with buffer to image copies, depth buffer clears, dirty descriptor state management, usage of the TFU unit for transfer operations and more.
Finally, there is one other aspect of this UE4 demo that is pretty obvious as soon as you start a game: it can compile a lot of shaders in the middle of the gameplay loop which can lead to significant stutter. While there is not much we can do about this on the driver side, but adding support for a shader cache on disk should eliminate the problem on sessions after the first, so this is something that we may work on in the future.
We will certainly continue to look at improving the driver performance in the future so stay tuned for further updates on our progress or maybe join us at #videocore on Freenode.
During my presentation at the X Developers Conference I stated that we had been mostly using the Khronos Vulkan Conformance Test suite (aka Vulkan CTS) to validate our Vulkan driver for Raspberry Pi 4 (aka V3DV). While the CTS is an invaluable resource for driver testing and validation, it doesn’t exactly compare to actual real world applications, and so, I made the point that we should try to do more real world testing for the driver after completing initial Vulkan 1.0 support.
To be fair, we had been doing a little bit of this already when I worked on getting the Vulkan ports of all 3 Quake game classics to work with V3DV, which allowed us to identify and fix a few driver bugs during development. The good thing about these games is that we could get the source code and compile them natively for ARM platforms, so testing and debugging was very convenient.
Unfortunately, there are not a plethora of Vulkan applications and games like these that we can easily test and debug on a Raspberry Pi as of today, which posed a problem. One way to work around this limitation that was suggested after my presentation at XDC was to use Zink, the OpenGL to Vulkan layer in Mesa. Using Zink, we can take existing OpenGL applications that are currently available for Raspberry Pi and use them to test our Vulkan implementation a bit more thoroughly, expanding our options for testing while we wait for the Vulkan ecosystem on Raspberry Pi 4 to grow.
So last week I decided to get hands on with that. Zink requires a few things from the underlying Vulkan implementation depending on the OpenGL version targeted. Currently, Zink only targets desktop OpenGL versions, so that limits us to OpenGL 2.1, which is the maximum version of desktop OpenGL that Raspbery Pi 4 can support (we support up to OpenGL ES 3.1 though). For that desktop OpenGL version, Zink required a few optional Vulkan 1.0 features that we were missing in V3DV, namely:
Logic operations.
Alpha to one.
VK_KHR_maintenance1.
The first two were trivial: they were already implemented and we only had to expose them in the driver. Notably, when I was testing these features with the relevant CTS tests I found a bug in the alpha to one tests, so I proposed a fix to Khronos which is currently in review.
I also noticed that Zink was also implicitly requiring support for timestamp queries, so I also implemented that in V3DV and then also wrote a patch for Zink to handle this requirement better.
Finally, Zink doesn’t use Vulkan swapchains, instead it creates presentable images directly, which was problematic for us because our platform needs to handle allocations for presentable images specially, so a patch for Zink was also required to address this.
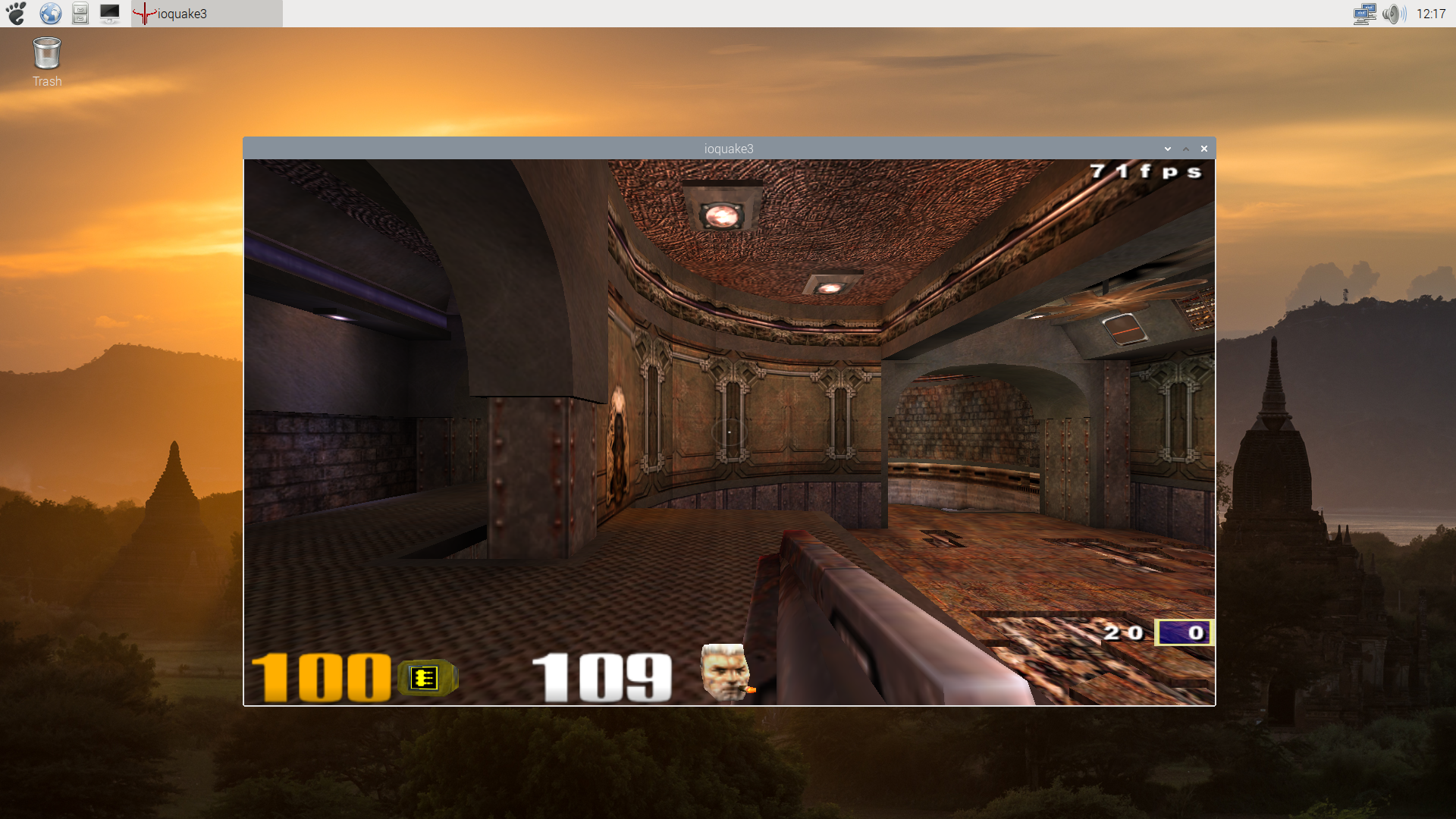
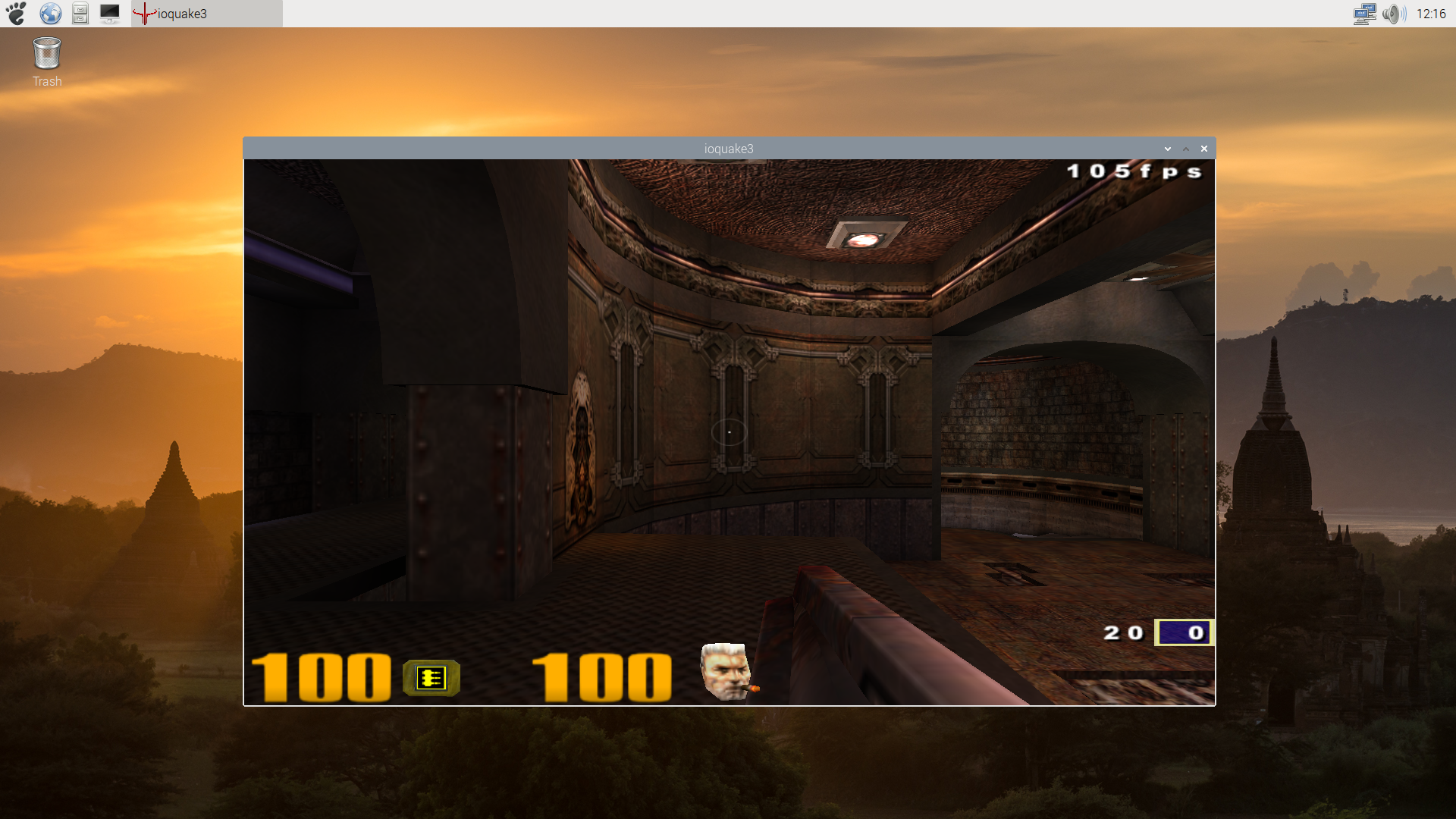
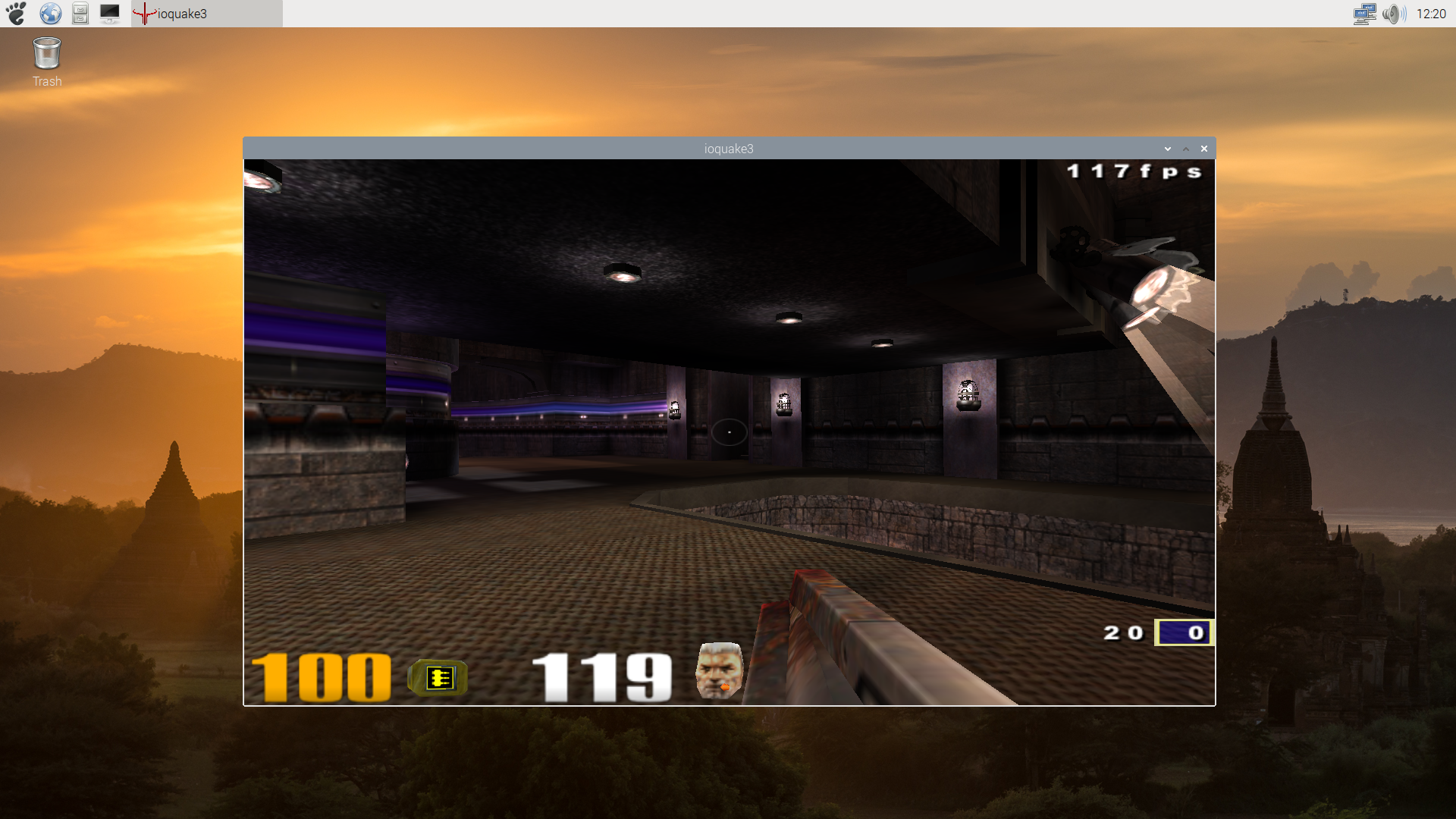
As of the writing of this post, all this work has been merged in Mesa and it enables Zink to run OpenGL 2.1 applications over V3DV on Raspberry Pi 4. Here are a few screenshots of Quake3 taken with the native OpenGL driver (V3D), with the native Vulkan driver (V3DV) and with Zink (over V3DV). There is a significant performance hit with Zink at present, although that is probably not too unexpected at this stage, but otherwise it seems to be rendering correctly, which is what we were really interested to see:
Quake3 Vulkan renderer (V3DV)
Quake3 OpenGL renderer (V3D)
Quake3 OpenGL renderer (Zink + V3DV)
Note: you’ll notice that the Vulkan screenshot is darker than the OpenGL versions. As I reported in another post, that is a feature of the Vulkan port of Quake3 and is unrelated to the driver.
Going forward, we expect to use Zink to test more applications and hopefully identify driver bugs that help us make V3DV better.
We have been making good progress so far and at this point we are getting close to having a complete Vulkan 1.0 implementation. I believe the main pending features for that are pipeline caches, which Alejandro is currently working on, texel buffers, multisampling support and robust buffer access, so in the last few weeks I decided to take a break from feature development and try to get some Vulkan games running with our driver and use them to guide some inital performance work.
I decided to work with all 3 VkQuake games since they run on Linux, the source code is available (which makes things a lot easier to debug) and seemed to be using a subset of the Vulkan API we already supported. For vkQuake we needed compute shaders and input attachments that we implemented recently, and for vkQuake3 we needed a couple of optional Vulkan features which I implemented recently to get it running without having to modify the game code. So all these games are now running on the Raspberry Pi4 with the V3DV driver. At the same time, our friend Salva from Pi Labs has also been testing the PPSSPP emulator using Vulkan and reporting that some games seem to be working already, which has been great to hear.
I was particularly interested in getting vkQuake3 to work because the project includes both the Vulkan and the original OpenGL renderers, which was great to compare performance between both APIs. VkQuake3 comes with a GL1 and a GL2 renderer, with the GL1 render being the fastest of the two by a large margin (apparently the GL2 renderer has additional rendering features that make it much slower). I think the Vulkan renderer is based on the GL1 renderer (although I have not actually checked) so I figured it would make the most reasonable comparison, and in our tests we found the Vulkan version to be up to 60% faster. Of course, it could be argued that GL1 is a pretty old API and that the difference with a more modern GL or GLES renderer might be less significant, but it is still a good sign.
To finish the post, here are some pics of the games:
vkQuake
vkQuake2
vkQuake3 OpenGL 1 renderer
vkQuake3 OpenGL 1 renderer
vkQuake3 Vulkan renderer
vkQuake3 Vulkan renderer
A couple of final notes:
* Note that the Vulkan renderer for vkQuake3 is much darker, but that is just how the renderer operates and not a driver issue, we observed the same behavior on Intel GPUs.
* A note for those interested in trying vkQuake3, we noticed that exterior levels have broken sky rendering, I hope we will get to fix that soon.
So continuing with the news, here is a fairly recent one: as the tile states, I am happy to announce that the Raspberry Pi 4 is now an OpenGL ES 3.1 conformant product!. This means that the Mesa V3D driver has successfully passed a whole lot of tests designed to validate the OpenGL ES 3.1 feature set, which should be a good sign of driver quality and correctness.
It should be noted that the Raspberry Pi 4 shipped with a V3D driver exposing OpenGL ES 3.0, so this also means that on top of all the bugfixes that we implemented for conformance, the driver has also gained new functionality! Particularly, we merged Eric’s previous work to enable Compute Shaders.
All this work has been in Mesa master since December (I believe there is only one fix missing waiting for us to address review feedback), and will hopefully make it to Raspberry Pi 4 users soon.