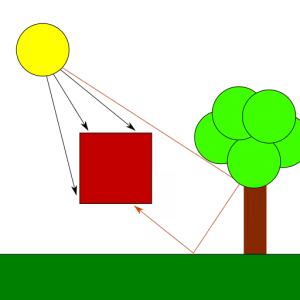
In the previous post we talked about the Phong lighting model as a means to represent light in a scene. Once we have light, we can think about implementing shadows, which are the parts of the scene that are not directly exposed to light sources. Shadow mapping is a well known technique used to render shadows in a scene from one or multiple light sources. In this post we will start discussing how to implement this, specifically, how to render the shadow map image, and the next post will cover how to use the shadow map to render shadows in the scene.
Note: although the code samples in this post are for Vulkan, it should be easy for the reader to replicate the implementation in OpenGL. Also, my OpenGL terrain renderer demo implements shadow mapping and can also be used as a source code reference for OpenGL.
Algorithm overview
Shadow mapping involves two passes, the first pass renders the scene from te point of view of the light with depth testing enabled and records depth information for each fragment. The resulting depth image (the shadow map) contains depth information for the fragments that are visible from the light source, and therefore, are occluders for any other fragment behind them from the point of view of the light. In other words, these represent the only fragments in the scene that receive direct light, every other fragment is in the shade. In the second pass we render the scene normally to the render target from the point of view of the camera, then for each fragment we need to compute the distance to the light source and compare it against the depth information recorded in the previous pass to decice if the fragment is behind a light occluder or not. If it is, then we remove the diffuse and specular components for the fragment, making it look shadowed.
In this post I will cover the first pass: generation of the shadow map.
Producing the shadow map image
Note: those looking for OpenGL code can have a look at this file ter-shadow-renderer.cpp from my OpenGL terrain renderer demo, which contains the shadow map renderer that generates the shadow map for the sun light in that demo.
Creating a depth image suitable for shadow mapping
The shadow map is a regular depth image were we will record depth information for fragments in light space. This image will be rendered into and sampled from. In Vulkan we can create it like this:
...
VkImageCreateInfo image_info = {};
image_info.sType = VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO;
image_info.pNext = NULL;
image_info.imageType = VK_IMAGE_TYPE_2D;
image_info.format = VK_FORMAT_D32_SFLOAT;
image_info.extent.width = SHADOW_MAP_WIDTH;
image_info.extent.height = SHADOW_MAP_HEIGHT;
image_info.extent.depth = 1;
image_info.mipLevels = 1;
image_info.arrayLayers = 1;
image_info.samples = VK_SAMPLE_COUNT_1_BIT;
image_info.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
image_info.usage = VK_IMAGE_USAGE_DEPTH_STENCIL_ATTACHMENT_BIT |
VK_IMAGE_USAGE_SAMPLED_BIT;
image_info.queueFamilyIndexCount = 0;
image_info.pQueueFamilyIndices = NULL;
image_info.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
image_info.flags = 0;
VkImage image;
vkCreateImage(device, &image_info, NULL, &image);
...
The code above creates a 2D image with a 32-bit float depth format. The shadow map’s width and height determine the resolution of the depth image: larger sizes produce higher quality shadows but of course this comes with an additional computing cost, so you will probably need to balance quality and performance for your particular target. In the first pass of the algorithm we need to render to this depth image, so we include the VK_IMAGE_USAGE_DEPTH_STENCIL_ATTACHMENT_BIT usage flag, while in the second pass we will sample the shadow map from the fragment shader to decide if each fragment is in the shade or not, so we also include the VK_IMAGE_USAGE_SAMPLED_BIT.
One more tip: when we allocate and bind memory for the image, we probably want to request device local memory too (VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT) for optimal performance, since we won’t need to map the shadow map memory in the host for anything.
Since we are going to render to this image in the first pass of the process we also need to create a suitable image view that we can use to create a framebuffer. There are no special requirements here, we just create a view with the same format as the image and with a depth aspect:
...
VkImageViewCreateInfo view_info = {};
view_info.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO;
view_info.pNext = NULL;
view_info.image = image;
view_info.format = VK_FORMAT_D32_SFLOAT;
view_info.components.r = VK_COMPONENT_SWIZZLE_R;
view_info.components.g = VK_COMPONENT_SWIZZLE_G;
view_info.components.b = VK_COMPONENT_SWIZZLE_B;
view_info.components.a = VK_COMPONENT_SWIZZLE_A;
view_info.subresourceRange.aspectMask = VK_IMAGE_ASPECT_DEPTH_BIT;
view_info.subresourceRange.baseMipLevel = 0;
view_info.subresourceRange.levelCount = 1;
view_info.subresourceRange.baseArrayLayer = 0;
view_info.subresourceRange.layerCount = 1;
view_info.viewType = VK_IMAGE_VIEW_TYPE_2D;
view_info.flags = 0;
VkImageView shadow_map_view;
vkCreateImageView(device, &view_info, NULL, &view);
...
Rendering the shadow map
In order to generate the shadow map image we need to render the scene from the point of view of the light, so first, we need to compute the corresponding View and Projection matrices. How we calculate these matrices depends on the type of light we are using. As described in the previous post, we can consider 3 types of lights: spotlights, positional lights and directional lights.
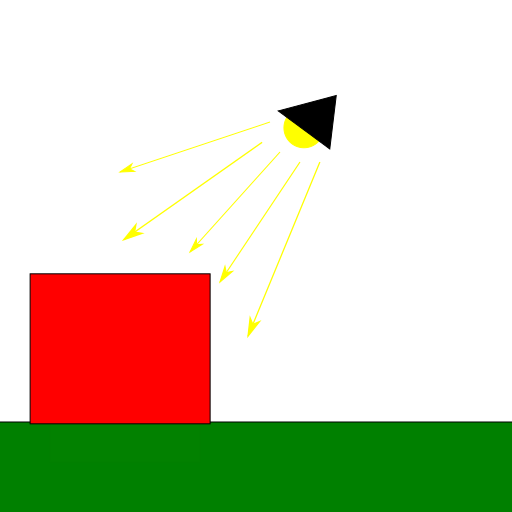
Spotlights are the easiest for shadow mapping, since with these we use regular perspective projection.
Positional lights work similar to spotlights in the sense that they also use perspective projection, however, because these are omnidirectional, they see the entire scene around them. This means that we need to render a shadow map that contains scene objects in all directions around the light. We can do this by using a cube texture for the shadow map instead of a regular 2D texture and render the scene 6 times adjusting the View matrix to capture scene objects in front of the light, behind it, to its left, to its right, above and below. In this case we want to use a field of view of 45º with the projection matrix so that the set of 6 images captures the full scene around the light source with no image overlaps.
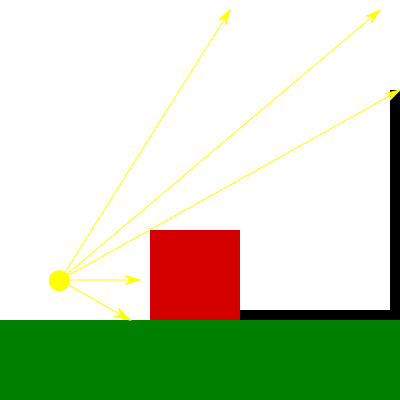
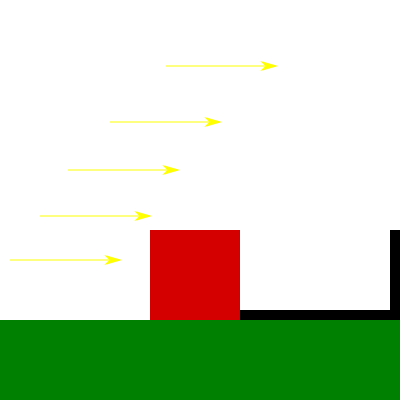
Finally, we have directional lights. In the previous post I mentioned that these lights model light sources which rays are parallel and because of this feature they cast regular shadows (that is, shadows that are not perspective projected). Thus, to render shadow maps for directional lights we want to use orthographic projection instead of perspective projection.
 |
 |
In this post I will focus on creating a shadow map for a spotlight source only. I might write follow up posts in the future covering other light sources, but for the time being, you can have a look at my OpenGL terrain renderer demo if you are interested in directional lights.
So, for a spotlight source, we just define a regular perspective projection, like this:
glm::mat4 clip = glm::mat4(1.0f, 0.0f, 0.0f, 0.0f,
0.0f,-1.0f, 0.0f, 0.0f,
0.0f, 0.0f, 0.5f, 0.0f,
0.0f, 0.0f, 0.5f, 1.0f);
glm::mat4 light_projection = clip *
glm::perspective(glm::radians(45.0f),
(float) SHADOW_MAP_WIDTH / SHADOW_MAP_HEIGHT,
LIGHT_NEAR, LIGHT_FAR);
The code above generates a regular perspective projection with a field of view of 45º. We should adjust the light’s near and far planes to make them as tight as possible to reduce artifacts when we use the shadow map to render the shadows in the scene (I will go deeper into this in a later post). In order to do this we should consider that the near plane can be increased to reflect the closest that an object can be to the light (that might depend on the scene, of course) and the far plane can be decreased to match the light’s area of influence (determined by its attenuation factors, as explained in the previous post).
The clip matrix is not specific to shadow mapping, it just makes it so that the resulting projection considers the particularities of how the Vulkan coordinate system is defined (Y axis is inversed, Z range is halved).
As usual, the projection matrix provides us with a projection frustrum, but we still need to point that frustum in the direction in which our spotlight is facing, so we also need to compute the view matrix transform of our spotlight. One way to define the direction in which our spotlight is facing is by having the rotation angles of spotlight on each axis, similarly to what we would do to compute the view matrix of our camera:
glm::mat4
compute_view_matrix_for_rotation(glm::vec3 origin, glm::vec3 rot)
{
glm::mat4 mat(1.0);
float rx = DEG_TO_RAD(rot.x);
float ry = DEG_TO_RAD(rot.y);
float rz = DEG_TO_RAD(rot.z);
mat = glm::rotate(mat, -rx, glm::vec3(1, 0, 0));
mat = glm::rotate(mat, -ry, glm::vec3(0, 1, 0));
mat = glm::rotate(mat, -rz, glm::vec3(0, 0, 1));
mat = glm::translate(mat, -origin);
return mat;
}
Here, origin is the position of the light source in world space, and rot represents the rotation angles of the light source on each axis, representing the direction in which the spotlight is facing.
Now that we have the View and Projection matrices that define our light space we can go on and render the shadow map. For this we need to render scene as we normally would but instead of using our camera’s View and Projection matrices, we use the light’s. Let’s have a look at the shadow map rendering code:
Render pass
static VkRenderPass
create_shadow_map_render_pass(VkDevice device)
{
VkAttachmentDescription attachments[2];
// Depth attachment (shadow map)
attachments[0].format = VK_FORMAT_D32_SFLOAT;
attachments[0].samples = VK_SAMPLE_COUNT_1_BIT;
attachments[0].loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
attachments[0].storeOp = VK_ATTACHMENT_STORE_OP_STORE;
attachments[0].stencilLoadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
attachments[0].stencilStoreOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;
attachments[0].initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
attachments[0].finalLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
attachments[0].flags = 0;
// Attachment references from subpasses
VkAttachmentReference depth_ref;
depth_ref.attachment = 0;
depth_ref.layout = VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL;
// Subpass 0: shadow map rendering
VkSubpassDescription subpass[1];
subpass[0].pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;
subpass[0].flags = 0;
subpass[0].inputAttachmentCount = 0;
subpass[0].pInputAttachments = NULL;
subpass[0].colorAttachmentCount = 0;
subpass[0].pColorAttachments = NULL;
subpass[0].pResolveAttachments = NULL;
subpass[0].pDepthStencilAttachment = &depth_ref;
subpass[0].preserveAttachmentCount = 0;
subpass[0].pPreserveAttachments = NULL;
// Create render pass
VkRenderPassCreateInfo rp_info;
rp_info.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
rp_info.pNext = NULL;
rp_info.attachmentCount = 1;
rp_info.pAttachments = attachments;
rp_info.subpassCount = 1;
rp_info.pSubpasses = subpass;
rp_info.dependencyCount = 0;
rp_info.pDependencies = NULL;
rp_info.flags = 0;
VkRenderPass render_pass;
VK_CHECK(vkCreateRenderPass(device, &rp_info, NULL, &render_pass));
return render_pass;
}
The render pass is simple enough: we only have one attachment with the depth image and one subpass that renders to the shadow map target. We will start the render pass by clearing the shadow map and by the time we are done we want to store it and transition it to layout VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL so we can sample from it later when we render the scene with shadows. Notice that because we only care about depth information, the render pass doesn’t include any color attachments.
Framebuffer
Every rendering job needs a target framebuffer, so we need to create one for our shadow map. For this we will use the image view we created from the shadow map image. We link this framebuffer target to the shadow map render pass description we have just defined:
VkFramebufferCreateInfo fb_info; fb_info.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO; fb_info.pNext = NULL; fb_info.renderPass = shadow_map_render_pass; fb_info.attachmentCount = 1; fb_info.pAttachments = &shadow_map_view; fb_info.width = SHADOW_MAP_WIDTH; fb_info.height = SHADOW_MAP_HEIGHT; fb_info.layers = 1; fb_info.flags = 0; VkFramebuffer shadow_map_fb; vkCreateFramebuffer(device, &fb_info, NULL, &shadow_map_fb);
Pipeline description
The pipeline we use to render the shadow map also has some particularities:
Because we only care about recording depth information, we can typically skip any vertex attributes other than the positions of the vertices in the scene:
... VkVertexInputBindingDescription vi_binding[1]; VkVertexInputAttributeDescription vi_attribs[1]; // Vertex attribute binding 0, location 0: position vi_binding[0].binding = 0; vi_binding[0].inputRate = VK_VERTEX_INPUT_RATE_VERTEX; vi_binding[0].stride = 2 * sizeof(glm::vec3); vi_attribs[0].binding = 0; vi_attribs[0].location = 0; vi_attribs[0].format = VK_FORMAT_R32G32B32_SFLOAT; vi_attribs[0].offset = 0; VkPipelineVertexInputStateCreateInfo vi; vi.sType = VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO; vi.pNext = NULL; vi.flags = 0; vi.vertexBindingDescriptionCount = 1; vi.pVertexBindingDescriptions = vi_binding; vi.vertexAttributeDescriptionCount = 1; vi.pVertexAttributeDescriptions = vi_attribs; ... pipeline_info.pVertexInputState = &vi; ...
The code above defines a single vertex attribute for the position, but assumes that we read this from a vertex buffer that packs interleaved positions and normals for each vertex (each being a vec3) so we use the binding’s stride to jump over the normal values in the buffer. This is because in this particular example, we have a single vertex buffer that we reuse for both shadow map rendering and normal scene rendering (which requires vertex normals for lighting computations).
Again, because we do not produce color data, we can skip the fragment shader and our vertex shader is a simple passthough instead of the normal vertex shader we use with the scene:
....
VkPipelineShaderStageCreateInfo shader_stages[1];
shader_stages[0].sType =
VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
shader_stages[0].pNext = NULL;
shader_stages[0].pSpecializationInfo = NULL;
shader_stages[0].flags = 0;
shader_stages[0].stage = VK_SHADER_STAGE_VERTEX_BIT;
shader_stages[0].pName = "main";
shader_stages[0].module = create_shader_module("shadowmap.vert.spv", ...);
...
pipeline_info.pStages = shader_stages;
pipeline_info.stageCount = 1;
...
This is how the shadow map vertex shader (shadowmap.vert) looks like in GLSL:
#version 400
#extension GL_ARB_separate_shader_objects : enable
#extension GL_ARB_shading_language_420pack : enable
layout(std140, set = 0, binding = 0) uniform vp_ubo {
mat4 ViewProjection;
} VP;
layout(std140, set = 0, binding = 1) uniform m_ubo {
mat4 Model[16];
} M;
layout(location = 0) in vec3 in_position;
void main()
{
vec4 pos = vec4(in_position.x, in_position.y, in_position.z, 1.0);
vec4 world_pos = M.Model[gl_InstanceIndex] * pos;
gl_Position = VP.ViewProjection * world_pos;
}
The shader takes the ViewProjection matrix of the light (we have already multiplied both together in the host) and a UBO with the Model matrices of each object in the scene as external resources (we use instanced rendering in this particular example) as well as a single vec3 input attribute with the vertex position. The only job of the vertex shader is to compute the position of the vertex in the transformed space (the light space, since we are passing the ViewProjection matrix of the light), nothing else is done here.
Command buffer
The command buffer is pretty similar to the one we use with the scene, only that we render to the shadow map image instead of the usual render target. In the shadow map render pass description we have indicated that we will clear it, so we need to include a depth clear value. We also need to make sure that we set the viewport and sccissor to match the shadow map dimensions:
...
VkClearValue clear_values[1];
clear_values[0].depthStencil.depth = 1.0f;
clear_values[0].depthStencil.stencil = 0;
VkRenderPassBeginInfo rp_begin;
rp_begin.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
rp_begin.pNext = NULL;
rp_begin.renderPass = shadow_map_render_pass;
rp_begin.framebuffer = shadow_map_framebuffer;
rp_begin.renderArea.offset.x = 0;
rp_begin.renderArea.offset.y = 0;
rp_begin.renderArea.extent.width = SHADOW_MAP_WIDTH;
rp_begin.renderArea.extent.height = SHADOW_MAP_HEIGHT;
rp_begin.clearValueCount = 1;
rp_begin.pClearValues = clear_values;
vkCmdBeginRenderPass(shadow_map_cmd_buf,
&rp_begin,
VK_SUBPASS_CONTENTS_INLINE);
VkViewport viewport;
viewport.height = SHADOW_MAP_HEIGHT;
viewport.width = SHADOW_MAP_WIDTH;
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;
viewport.x = 0;
viewport.y = 0;
vkCmdSetViewport(shadow_map_cmd_buf, 0, 1, &viewport);
VkRect2D scissor;
scissor.extent.width = SHADOW_MAP_WIDTH;
scissor.extent.height = SHADOW_MAP_HEIGHT;
scissor.offset.x = 0;
scissor.offset.y = 0;
vkCmdSetScissor(shadow_map_cmd_buf, 0, 1, &scissor);
...
Next, we bind the shadow map pipeline we created above, bind the vertex buffer and descriptor sets as usual and draw the scene geometry.
...
vkCmdBindPipeline(shadow_map_cmd_buf,
VK_PIPELINE_BIND_POINT_GRAPHICS,
shadow_map_pipeline);
const VkDeviceSize offsets[1] = { 0 };
vkCmdBindVertexBuffers(shadow_cmd_buf, 0, 1, vertex_buf, offsets);
vkCmdBindDescriptorSets(shadow_map_cmd_buf,
VK_PIPELINE_BIND_POINT_GRAPHICS,
shadow_map_pipeline_layout,
0, 1,
shadow_map_descriptor_set,
0, NULL);
vkCmdDraw(shadow_map_cmd_buf, ...);
vkCmdEndRenderPass(shadow_map_cmd_buf);
...
Notice that the shadow map pipeline layout will be different from the one used with the scene too. Specifically, during scene rendering we will at least need to bind the shadow map for sampling and we will probably also bind additional resources to access light information, surface materials, etc that we don’t need to render the shadow map, where we only need the View and Projection matrices of the light plus the UBO with the model matrices of the objects in the scene.
We are almost there, now we only need to submit the command buffer for execution to render the shadow map:
...
VkPipelineStageFlags shadow_map_wait_stages = 0;
VkSubmitInfo submit_info = { };
submit_info.pNext = NULL;
submit_info.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submit_info.waitSemaphoreCount = 0;
submit_info.pWaitSemaphores = NULL;
submit_info.signalSemaphoreCount = 1;
submit_info.pSignalSemaphores = &signal_sem;
submit_info.pWaitDstStageMask = 0;
submit_info.commandBufferCount = 1;
submit_info.pCommandBuffers = &shadow_map_cmd_buf;
vkQueueSubmit(queue, 1, &submit_info, NULL);
...
Because the next pass of the algorithm will need to sample the shadow map during the final scene rendering,we use a semaphore to ensure that we complete this work before we start using it in the next pass of the algorithm.
In most scenarios, we will want to render the shadow map on every frame to account for dynamic objects that move in the area of effect of the light or even moving lights, however, if we can ensure that no objects have altered their positions inside the area of effect of the light and that the light’s description (position/direction) hasn’t changed, we may not need need to regenerate the shadow map and save some precious rendering time.
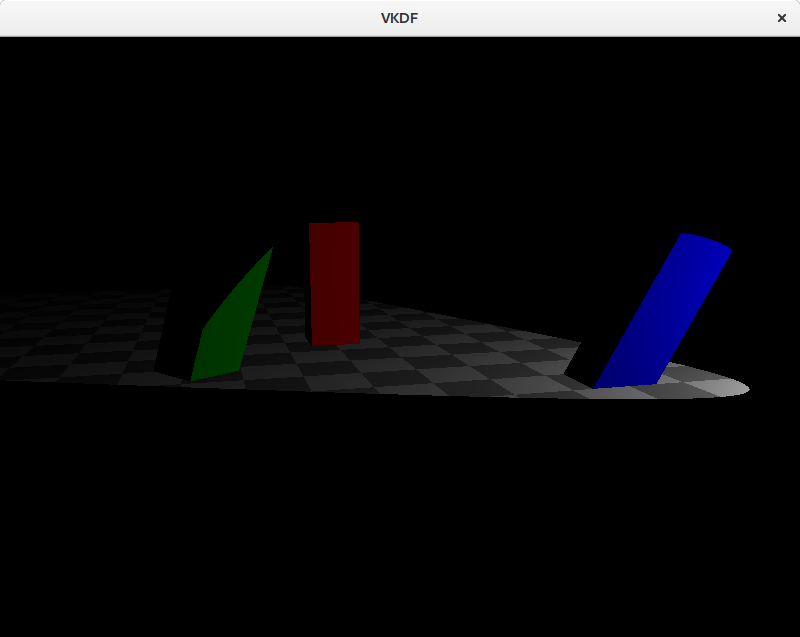
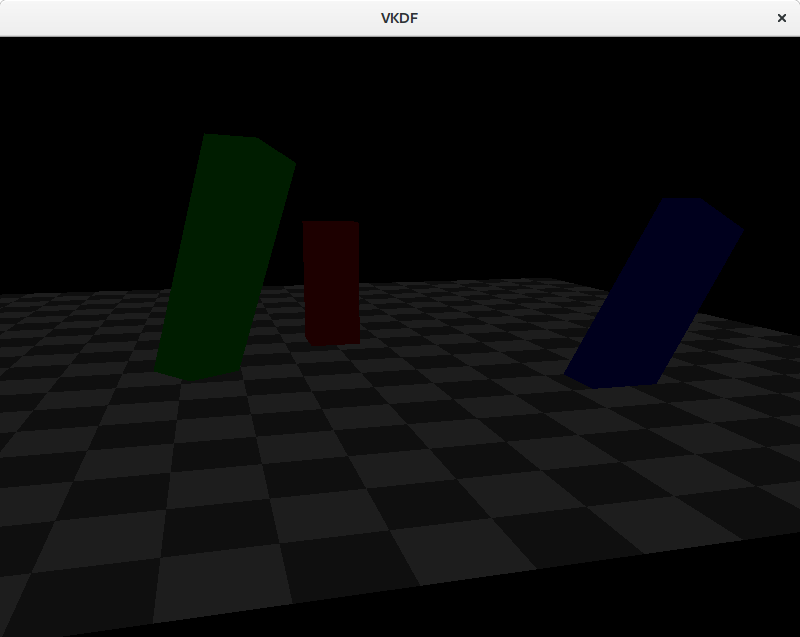
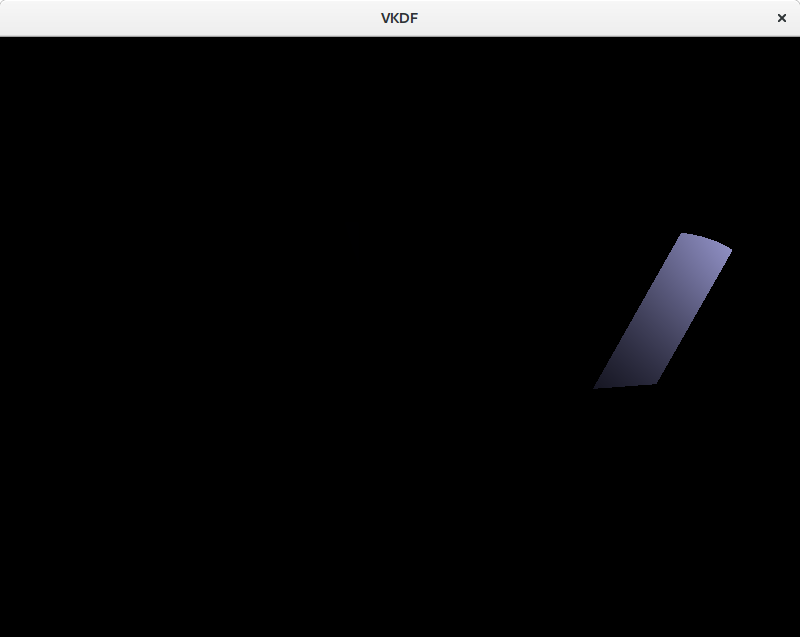
Visualizing the shadow map
After executing the shadow map rendering job our shadow map image contains the depth information of the scene from the point of view of the light. Before we go on and start using this as input to produce shadows in our scene, we should probably try to visualize the shadow map to verify that it is correct. For this we just need to submit a follow-up job that takes the shadow map image as a texture input and renders it to a quad on the screen. There is one caveat though: when we use perspective projection, Z values in the depth buffer are not linear, instead precission is larger at distances closer to the near plane and drops as we get closer to the far place in order to improve accuracy in areas closer to the observer and avoid Z-fighting artifacts. This means that we probably want to linearize our shadow map values when we sample from the texture so that we can actually see things, otherwise most things that are not close enough to the light source will be barely visible:
#version 400
#extension GL_ARB_separate_shader_objects : enable
#extension GL_ARB_shading_language_420pack : enable
layout(std140, set = 0, binding = 0) uniform mvp_ubo {
mat4 mvp;
} MVP;
layout(location = 0) in vec2 in_pos;
layout(location = 1) in vec2 in_uv;
layout(location = 0) out vec2 out_uv;
void main()
{
gl_Position = MVP.mvp * vec4(in_pos.x, in_pos.y, 0.0, 1.0);
out_uv = in_uv;
}
#version 400
#extension GL_ARB_separate_shader_objects : enable
#extension GL_ARB_shading_language_420pack : enable
layout (set = 1, binding = 0) uniform sampler2D image;
layout(location = 0) in vec2 in_uv;
layout(location = 0) out vec4 out_color;
void main()
{
float depth = texture(image, in_uv).r;
out_color = vec4(1.0 - (1.0 - depth) * 100.0);
}
We can use the vertex and fragment shaders above to render the contents of the shadow map image on to a quad. The vertex shader takes the quad’s vertex positions and texture coordinates as attributes and passes them to the fragment shader, while the fragment shader samples the shadow map at the provided texture coordinates and then “linearizes” the depth value so that we can see better. The code in the shader doesn’t properly linearize the depth values we read from the shadow map (that requires to pass the Z-near and Z-far values used in the projection), but for debugging purposes this works well enough for me, if you use different Z clipping planes you may need to alter the ‘100.0’ value to get good results (or you might as well do a proper conversion considering your actual Z-near and Z-far values).
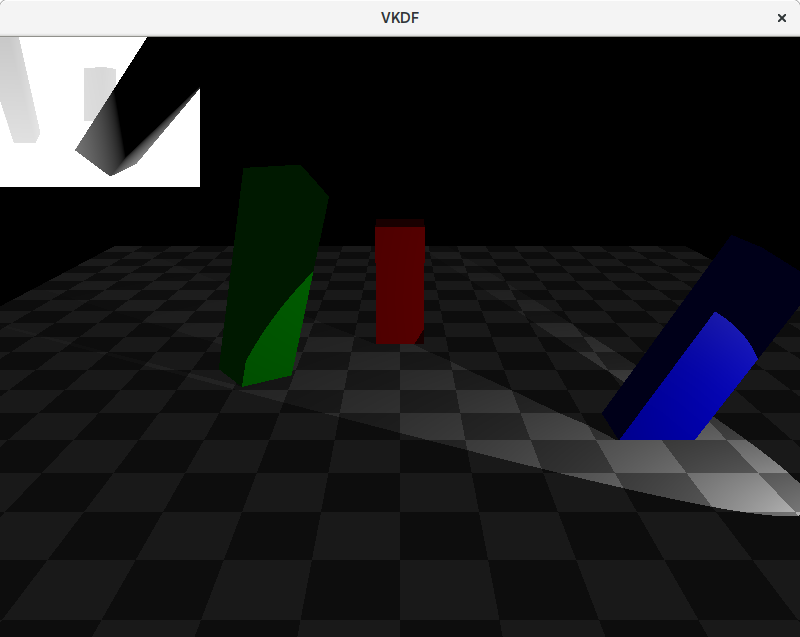
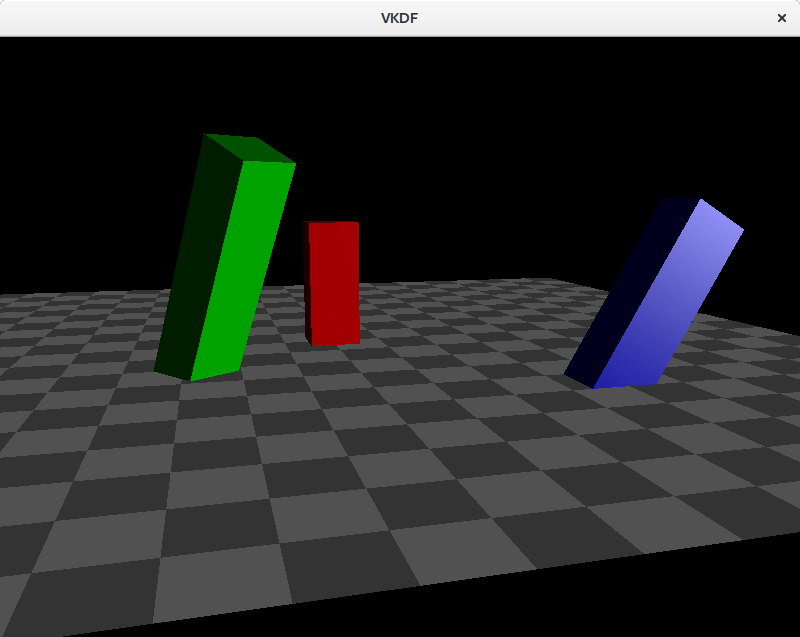
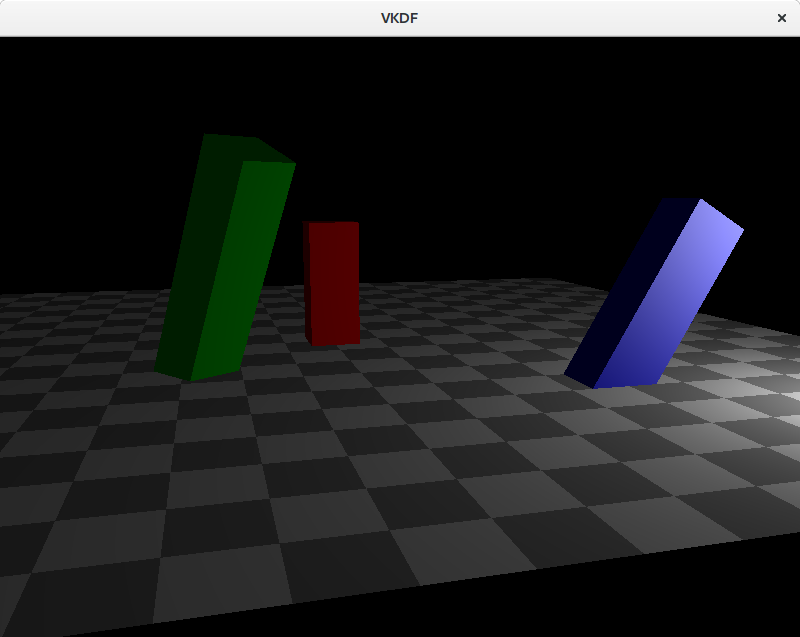
The image shows the shadow map on top of the scene. Darker colors represent smaller depth values, so these are fragments closer to the light source. Notice that we are not rendering the floor geometry to the shadow map since it can’t cast shadows on any other objects in the scene.
Conclusions
In this post we have described the shadow mapping technique as a combination of two passes: the first pass renders a depth image (the shadow map) with the scene geometry from the point of view of the light source. To achieve this, we need a passthrough vertex shader that only transforms the scene vertex positions (using the view and projection transforms from the light) and we can skip the fragment shader completely since we do not care for color output. The second pass, which we will cover in the next post, takes the shadow map as input and uses it to render shadows in the final scene.