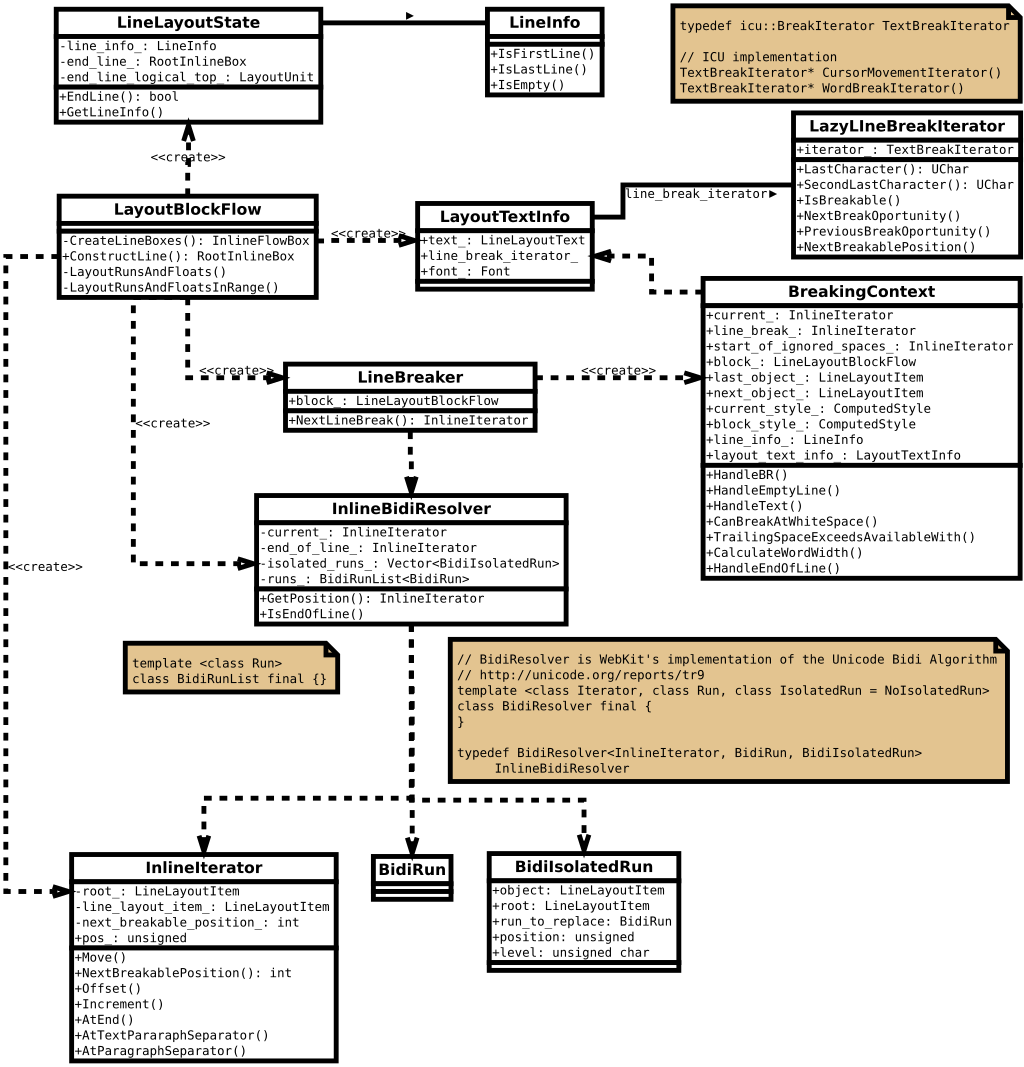
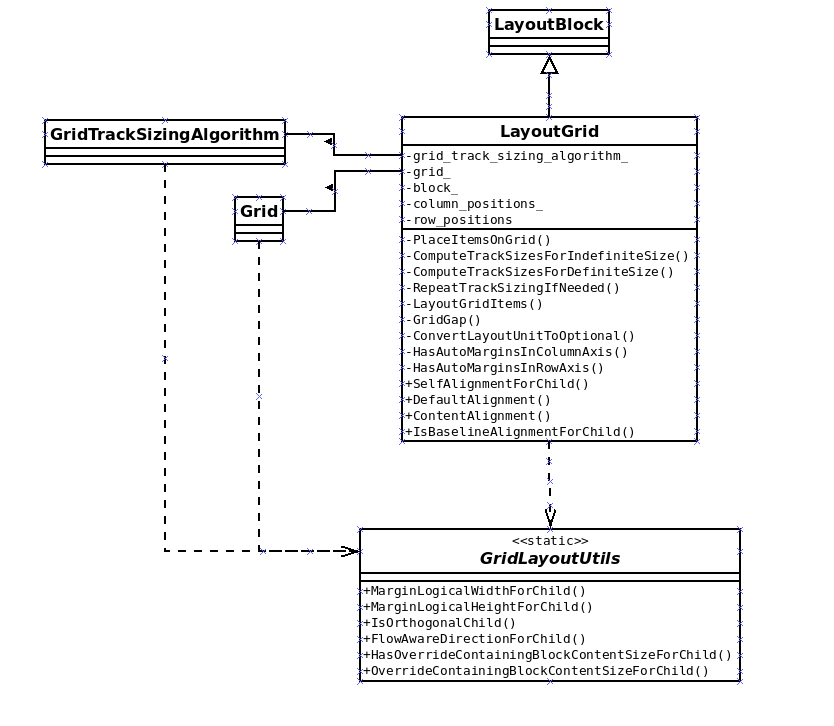
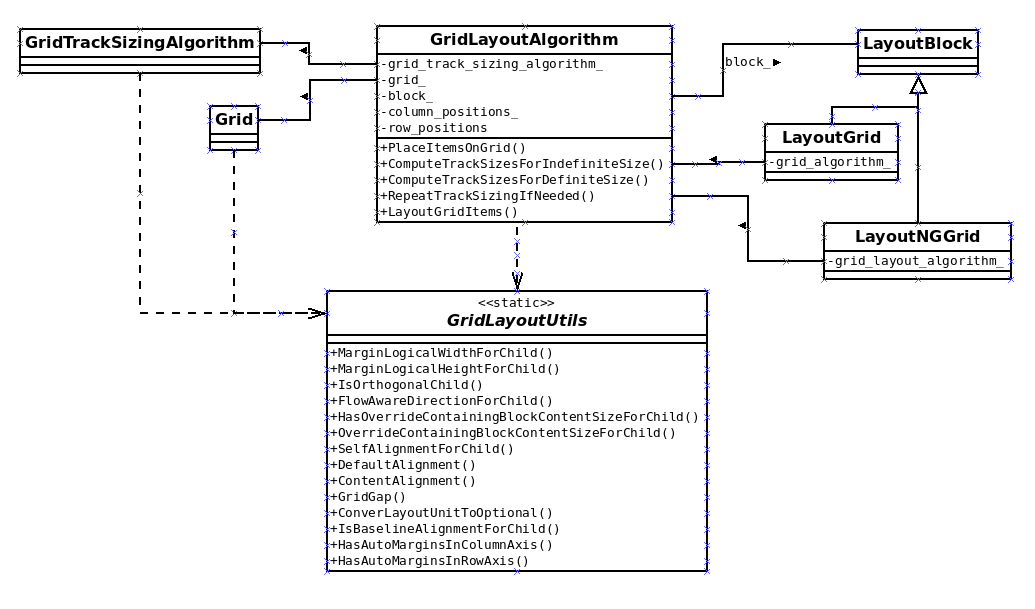
Introduction
Developers are exceptionally creative with the tools they are given. For a long time now they’ve had the ability to apply the Web Cryptography API to many uses. Getting random values from this API is, for example, an exceptionally popular use case being used on over 60% of page loads in the HTTP Archive dataset. Of course, it’s intended use is about actual cryptography and it offers numerous algorithms.
However, if developers feel the algorithm they need isn’t available from this API, they’ll write it (or compile to WASM) themselves. That’s the case today when it comes to “secure curve” algorithms, like X25519 [RFC7748] or Ed25519 [RFC8032] . These are desirable because they offer strong security guaranties while operating at much better performance levels than others. This is a shame because your browser already has internal support for these as part of TLS 1.3, it’s just not exposed to developers. Those userland solutions come with added costs of complexity, bandwidth, overall performance and has security implications.
Adding some Secure Curves to the Web Cryptography API would provide many advantages to web authors, but this has been a multi-year challenge that thanks to the collaboration between Igalia and Protocol Labs is close to give some results.
Context
Secure elliptic curves play a very important role in the area of cryptography, providing robust and efficient algorithms. Among the available algorithms of this kind, two curves that have gained significant attention in recent years are Ed25519 and X25519. These curves are based on the Edwards and Montgomery forms respectively, and offer strong security guaranties while still operating at excellent performance levels.
I think adding these curves to the API has been always an obvious step, but if we want to have the whole picture, we may need to step back and talk a bit about the history of the Web Cryptography API specification and why it’s has been so difficult to incorporate new and more modern algorithms in the last years.
The Web Cryptography API specification
In an effort of ensuring secure communication and data protection in the web, the W3C created the Web Cryptography Working Group which among its goals had the definition of an API that lets developers implement secure application protocols on the level of Web applications. Out of this effort the WG published the Web Cryptography API, becoming a W3C Recommendation in January 2017.
This specification defines a comprehensive set of interfaces and algorithms for performing various cryptographic tasks, such as encryption, decryption, digital signatures, key generation, and key management. As usual, one of the main goals of the W3C specs is to encourage an interoperable cryptographic API across different web browsers and platforms. This simplifies the development process and ensures compatibility and portability of web-based cryptographic applications.
There are several cryptographic algorithms defined in the Web Cryptography API, including symmetric encryption algorithms like AES, asymmetric encryption like RSA and Elliptic Curve Cryptography algorithms (ECC), hash functions like SHA-256 or digital signature algorithms like RSA-PSS. These API allows web authors to implement strong cryptographic mechanism without requiring a deep knowledge of the underlying cryptographic primitives.
It’s also important to note that the spec not only defines the cryptographic algorithms available for web applications, but also some security considerations, such as key storage and management, handling of sensitive data and protection against common security attacks. These considerations ensure that the apps implement their cryptographic logic in secure and robust way.
The adoption of the Web Cryptography API specification by major web browsers has been a key factor in enabling secure web applications and ensuring trust in only transactions.
Why it took so long to add Secure Curves
The lack of safe curves in the Web Cryptography specification has been a long-term issue for web developers that were forced to rely on third-party or native implementation for their applications. Even more when their use has been widely spread along non-web software components.
All these claims become an actual proposal when Qingsi Wang (Google) filed an issue for the TAG in the beginning of 2020. he proposal got quite positive feedback from Firefox engineers as it was clearly stated in the standard position request driven by David Baron (Mozillian back then) and Tantek Çelik, and endorsed by Martin Thomson.
So, despite the lack of a clear position from Safari, the proposal was accepted by the TAG with the support of 2 major browsers and the only concern of a proper standarization venue, given that the former Web Cryptography WG was closed a few years before. The solution to address these concerns was to develop this new specification in the Web Incubators Working Group.
The last Web Cryptography candidate recommendation was published in 2017, when it was still under the umbrella of the mentioned Web Cryptography WG. Since then, the spec drafts have been reviewed and published by the Web Application Security Working Group and with Daniel Huigens (Proton AG) as the only spec editor.
Even with this unstable situation, but with the support of 2 (Firefox and Chrome) main browsers, an intent to prototype request for Chrome was announced and the implementation started in Feb 2020. Unfortunately the work was not completed and even the partial implementation was removed from the Chromium source code repository.
After some time of maturing, the initial explainer written by Qingsi Wang was used to create the Secure Curves in the Web Cryptography API document, a potential W3C spec under the umbrella of the WIWG thanks to the work of its editor Daniel Huigens. The long-term plan is that the spec will be eventually integrated into the Web Cryptography API specification; and this is where Protocol Labs enters in the scene.
Protocol Labs contribution to the Web Crypto spec
Last year Protocol Labs defined a new goal in our long-term collaboration to get some progress on the effort to make the secure curves spec part of the Web Cryptography API. This kind of cryptography algorithm is a fundamental tool for several uses cases of the IPFS ecosystem they are trying to build during the last years.
The Ed25519 key pairs have become the standard in many web applications and the IPFS protocol has adopted them as default some time ago. Additionally, Ed25519 public keys had been primary identifiers across dat/hypercore and SSB from the beginning and most of the projects in this technology ecosystem prefer them due to the smaller key sizes and the possibility of implementing faster operations, in comparison to the use of RSA keys.
Since the adoption of UCANs by many teams inside Protocol Labs, it’s been frequent the hard choice between natively supported RSA keys in browsers versus the preferred Ed25519 keys, with the only option of relying on external libraries. The use of this external software components (eg many js / wasm ) implies a security risk of them been compromised. In most cases it is desired to have private keys non-extractable to prevent attacks from malicious scripts and/or web extensions, which can not be accomplished with js/wasm implementations; supply chain attacks is another vector that user space implementations are exposed to.
The alternatives to the lack of support of secure curves in the Web Platform has been bundling user space implementation of Ed25519 for signature verification (which increases complexity and amount of code of the programs) or the use of built-in RSA for signing (to prevent possible attacks as the ones described above).
In summary, Protocol Labs and Igalia consider that providing implementations of secure curves like Ed25519 and X25519 in the Web Cryptography API will provide to the Web Platform a very important feature that fills the gap respect to other native implementations. It will become a more competitive development platform for many projects, addressing the previously described attack vectors and in many cases simplifying applications and their implementation effort, as they will no longer require joggling Ed25519 and RSA keys.
Working plan
As I commented about, the long term goal is to get the full standardization status of the Secure Curves document and make the algorithms it defines part of the general Web Cryptography API specification. In order to achieve this goal it’s needed that most of the main browser implement the algorithms, ensuring a good level of interoperability. There are quite many Web Platform Tests for these new algorithms in the WebCryptoAPI test suite, so it’s a good start.
The nature of this goal, which I want to remark that is part of a long term and more general collaboration between Igalia and Protocol Labs, is a multi-browser task. Our plan is to implement, or collaborate with patches, spec work and tests, the Ed25519 and X25519 algorithms in Chromium, Firefox and Safari. Hence, one of the first steps has been to issue a standard position request for WebKit, which received positive feedback. This was useful to send a new intent to prototype request in Chrome, reactivating the one abandoned a few years ago.
Regarding Firefox, despite the positive feedback on the standard position request filed back in 2020, the implementation has not started yet and it’s pending on some blocking issues; I’ll elaborate on this issue in the next section.
Current status
Chrome
Our first target for this task has been the Chromium browser. Perhaps the best way to follow the progress of this work is through the Chrome Platform Status site, where there is a specific entry for this feature. If you are interested on the implementation details you can check the tracking bug.
It’s important to notice that the feature is being implemented behind the WebCryptoCurve25519 runtime flag, so if you are interested on trying it out you should enable the Experimental Web Platform Features. I’m going to talk later about what’s missing to propose the intent to ship request so that the feature could be enabled by default.
The Implementation of the Ed25519 algorithm landed Chromium in Nov 2022 and shipped in Chrome 110.0.5424.0. The X25519 key sharing algorithm took more time due to the review process, but it finally landed in March 2023 and has been shipped in Chrome since 113.0.5657.0. I can’t be more grateful to the patient and awesome work that David Benjamin (Google) did with all the reviews; contributing to the Chromium project has been always a pleasure and the review process extremely useful and agile, and this time it was not an exception.
Safari
Soon after getting positive feedback on the standard position request I filed, and in parallel to work on the implementation for Chrome, Safari engineers started the implementation of the Ed25519 algorithm for the WebKit engine. The main developer of this work has been Angela Izquierdo with reviews from Youenn Fablet mainly. Safari shipped the Ed25519 algorithm implementation in STP 163 and enabled by default for the COCOA WebKit port. I have in my TODO to enable it for the WebKitGtk+ port as well.
The implementation of the X25519 key sharing algorithm has not started yet, but I’ve been in conversation with some WebKit engineers to see how we can collaborate on this effort. Anyone interested could follow bug 258279 to track the progress of the implementation. I hope to have some time for this task during H2 this year.
Firefox
This is the browser that is more delayed regarding the implementation of the secure curves. I filed the bug 1804788 to track the implementation work and started already a preliminary analysis of the Gecko’s and NSS codebase. Unfortunately, it seems there is still some pending work (see bug 1325335 for details) to add the curve25519 cryptography primitives in the NSS library and this is blocking the Web Crypto API implementation.
We are already in conversations with some Firefox engineers and it seems there may be some progress by H2 this year as well.
Summary
The following table provides a high-level overview of the support of the secure curves25519 in some of the main browsers:
| Browser | Ed25519 | X25519 |
|---|---|---|
| Chrome | ✅ | ✅ |
| Safari | 🚀 | 🚧 |
| Firefox | 🚧 | 🚧 |
The following graphs show the current interoperability from wpt.fyi:
Test results for the generateKey method:

Test results for the deriveBits and deriveKey methods:
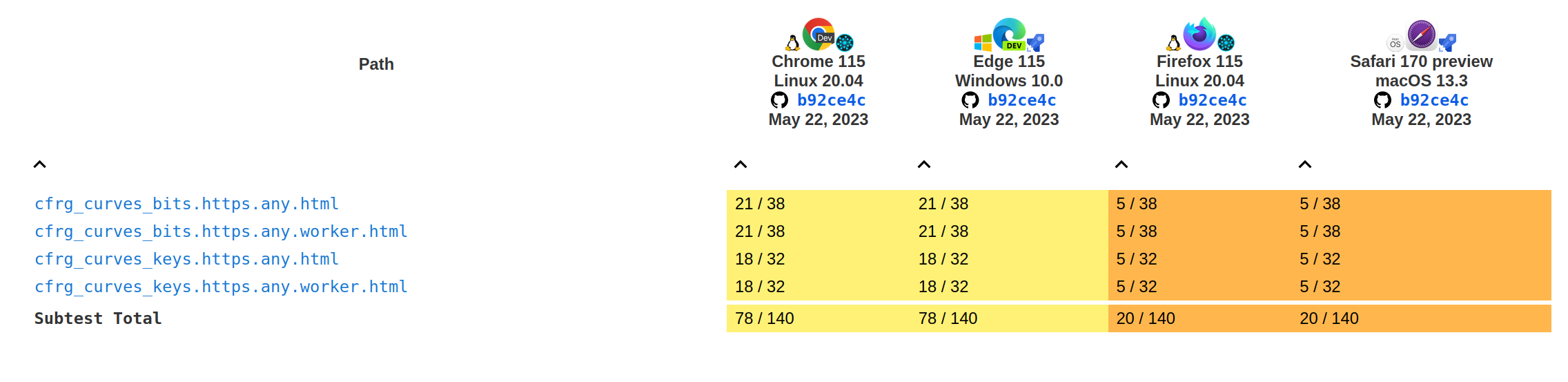
Tests results for the importKey and exportKey methods:
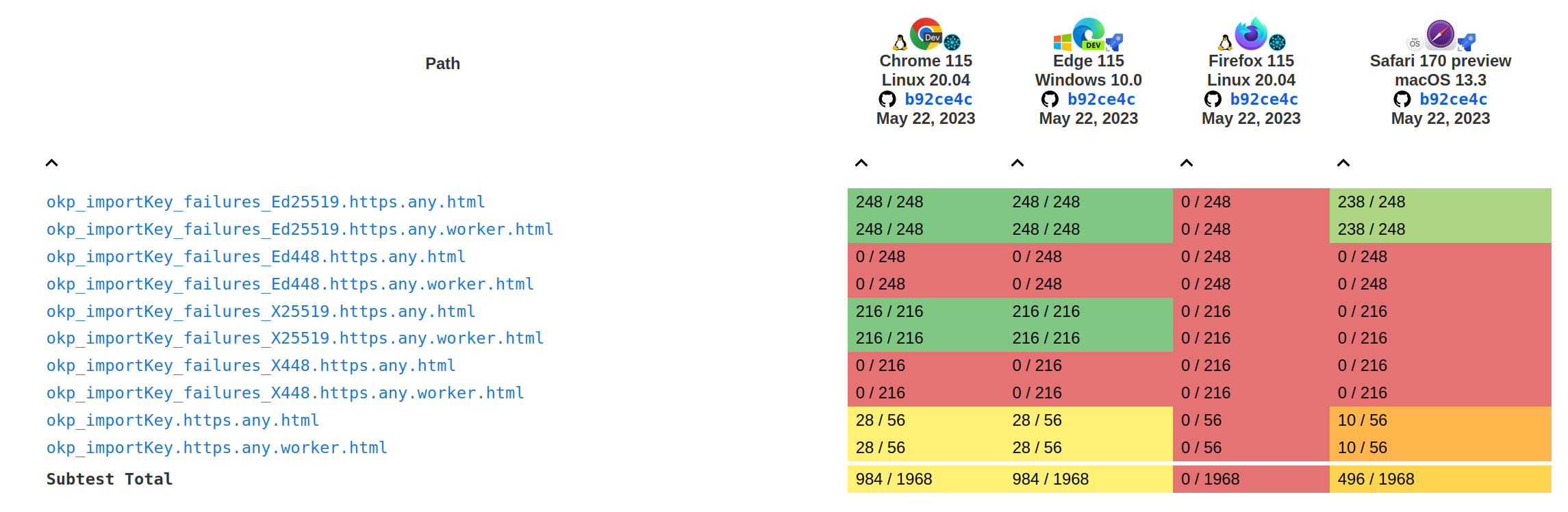
Tests results for the sign and verify methods:
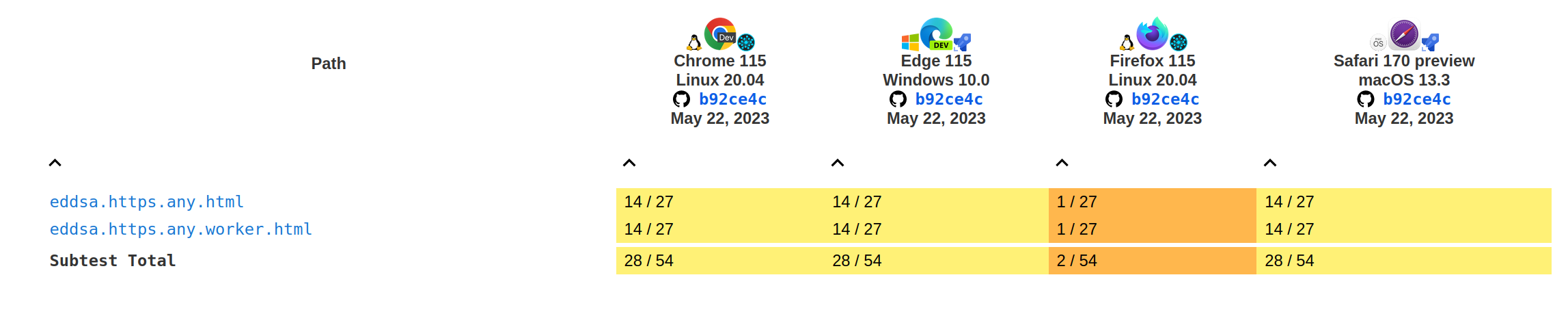
Tests results for the wrap and unwrap methods:

Next steps
Shipping by default in Chrome
On of the top priorities for H2 is to send the intent to ship request for Chrome. There are currently 2 issues that are blocking this task:
- bug 1402835 – Ensure Ed25519 and X25519 implementations matches the spec regarding small-order keys
- bug 1433707 – Handling optional length in X25519 does not match spec
Regarding the the first issue, in the last draft of the Secure Curves in the Web Cryptography specification states that there must be checks for the all-zero values to ensure small-order keys are rejected (as per RFC7748 Section 6.1).
If secret is the all-zero value, then throw a OperationError. This check must be performed in constant-time, as per [RFC7748] Section 6.1″
However, there is an ongoing discussion in the PR#13 to introduce a change so that the small-order keys are rejected during the import operation instead of when they are used. It’s worth mentioning the strong opposition from Chrome to this spec change, under the argument of following the RFC 7748 where it’s stated to do the checks when the keys are used and considers this PR a regression. There is also an ongoing discussion about this in WebKit in the form of a new standard-position request, but still no feedback on this side.
There are WPT to ensure that the X25519 algorithm works as expected with small-order keys, but since they assume that the all-zero checks are performed at the derivation phase, there are asserts to ensure the initial keys are valid. If the spec changes, these tests must be adapted.
Regarding the second issue, there is an active discussion in the issue#322 where despite the different positions about the best approach to address it, there is a clear consensus that the Web Cryptography API spec has several inconsistencies on how the deriveBit function’s ‘length’ parameter is defined. These inconsistencies have lead to wrong WPT definitions and possibly some browser’s implementations that would beed to be changed. Although there is a clear lack of interoperability here, the most concerning issue is the correctness of the implementations and how any potential change may affect to the deriveKey operations of ECDH, HFDF and PBKDF2 algorithms.
WebKit’s implementation of X25519
As I said before, we are currently analyzing the WebKit’s codebase to see if we could have some resources to start the implementation early in H2.
Firefox’s implementation of both Ed25519 and X25519
Until there is support in Firefox’s NSS component for the Curve25519 cryptographic primitives we are not able to start with the implementation of the Web Cryptography API for these algorithms.
Conclusions
The work that Igalia and Protocol Labs are doing in the Web Cryptography API specification will have a big impact on how web developers use the platform these days, reducing security risks and allowing lighter and simpler applications.
We are working very hard to offer web authors native support for the Ed255129 and X25519 in the main browsers (Safari, Firefox, Chrome) by the end of 2033, including all the Chromium based browsers (eg, Edge, Brave, Opera).
This work is another example of the Protocol Labs’s commitment with an open Web Platform and open source browsers, investing their resources on a great variety of features with wide impact on web authors.