The use of javascript for implementing server-side logic is not breaking news these days, but definitively Node.js is gaining relevance as one of the hottest technologies in this area. There are multiple reasons that explain this trend, but clearly one of those is the asynchronous event-driven model and it’s advantages for dealing with BigData problems.
When dealing with real-time requirements, Socket.io can play an important role on the web application architecture, providing an abstraction layer for the communication between the browser and the server. The Node.js event-driven model combined with the Socket.io real-time capabilities offer a good solution to face BigData challenges on domains where real-time capability is important
I’ll try to show some examples of the combination of these two technologies for implementing real-time web operations.
Socket.io based client-server communication
Lets consider the basic and default configuration of socket.io, described as follows:
- Client side javascript
"use strict"; jQuery(document).ready(function() { var socket = io.connect(); socket.on('connect', function() { console.log('connected'); }); socket.on('disconnect', function() { console.log('disconnected'); }); socket.on('error', function(err) { if(err === 'handshake error') { console.log('handshake error', err); } else { console.log('io error', err); } }); socket.on('updates', function(newUpdates) { }); $("#target").click(function() { socket.emit('myEvent'); }); }); |
The script uses JQuery to provide support for UI operations manipulating the DOM by the ‘updates’ event handler. This event is emitted by the server’s StreamAssembler, which I’ll describe later. Obviously, Socket.io does not require at all JQuery and it could be even defined inside a Javascript tag in the html page.
The client script can also emit events though the socket, which will be handled by server Node.js event loop. It’s a bidirectional communication channel.
- Server side javascript
'use strict'; var express = require('express'); var fs = require('fs'); var indexBuffer = fs.readFileSync('index.html').toString(); var app = express(); var io = require('socket.io'); var http = require('http'); var server = http.createServer(app); app.use(express.bodyParser()); app.use('/scripts', express.static(__dirname + '/scripts')); app.get('/', function(req, res) { console.log('Request to "/" ...'); res.contentType('text/html'); res.send(indexBuffer); }); server.listen(8080); io = io.listen(server); io.configure(function (){ io.set('log level', 1); }); io.sockets.on('connection', function (socket) { console.log('got socket.io connection - id: %s', socket.id); var assembler = new StreamAssembler(keys, socket, redisClient); socket.on('myEvent', function() { console.log('"myEvent" event received'); }); socket.on('disconnect', function() { // needs to be stopped explicitly or it will continue // listening to redis for updates. if(assembler) assembler.stop(); }); }); |
This code represents a minimalistic http server with Socket.io support. It just creates the server using the express module and makes the Socket.io process listening the http server. The Socket.io configuration just sets the log level, but it might be used for other purposes, like authentication.
The sever also sets up the StreamAssembler, which is the responsible of collecting, aggregating and assembling the raw data retrieved from the database and emitting events for the client (Browsers) through the Socket.io communication channel.
Stateful processing and data handy in-memory
The Node.js even-driven model eases the development of client/server stateful logic, which is very important when implementing distributed systems devoted to online processing of stream data and for assembling in one place all the context required for servicing a web request. It also helps to define async states-machine patterns thanks to the single-threaded approach, so the implementation results simpler and easier to debug than the typical multi-thread based solutions.
Also, perhaps even more important when dealing with real-time requirements, the in-memory data processing is mandatory to really provide a real-time user experience. Node.js provides a programming model fully aligned with this real-time approach in mind.
So, lets consider we have access to a large storage where huge data streams are stored and manipulated. Lets consider Redis as a cache system for such large storage, to be used for real-time purposes.
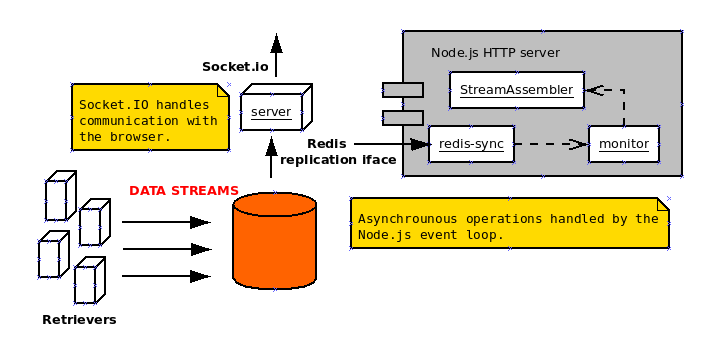
The StreamAssembler component receives a constant raw data stream and produces structured data, aggregating data from different sources, always under the limit of the window size in order to ensuring all the operations are executed in memory, taking into account the server’s HW specifications.
It uses the redis-sync module for exploiting the Redis Replication interface and monitoring the Redis storage, looking for commands that alter the database status on specific keys. It might also use the redis-sync module for replicating specific keys from the Redis (cache) database to the main storage (sediment), larger and usually offering better performance on write operations (Cassandra or HBase, for instance).
function StreamAssembler(keys, socket, redisClient) { var that = this; var updates = {}; var monitor = null; function moveServerWindow() { console.info('Moving server Window'); serverList = []; var k; for (k in updates) { serverList.push([k, updates[k].t]);} serverList.sort(function(a, b) { return a[1] < b[1] ? -1 : 0; }); while (serverList.length > serverWindowLimit) { var toDelete = serverList.pop(); delete updates[toDelete[0]]; } } function addUpdates(results) { var idList = []; var i, update, t, uk, u; for(i = 0; i < results.length; i += 2) { update = JSON.parse(results[i]); t = results[i + 1]; uk = update.id; idList.push(uk); u = updates[uk]; if(u === undefined) { //console.info(uk, 'not seen yet'); u = {t:t, data:update}; updates[uk] = u; } } return idList; } function getRawData(key, cb) { console.log('Getting raw data from: ' + key); redisClient.zrange(key, '-100', '-1', 'withscores', function(err, results) { if(err) return cb(err); addUpdates(results); cb(null); }); } function initialUpdate() { console.log('initial update'); moveServerWindow(); socket.emit('updates', updates); } that.addRawDataKeys = function addRawDataKeys(keys) { var rem = 0; var tlId; for(key in keys) { ++rem; getRawData(keys[key], function(err) { if(err) console.error(err); --rem; if(rem === 0) { initialUpdate(); that.addMonitorKeys(keys); } }); } if(rem === 0) { console.log('No update keys'); // no updates to retrieve initialUpdate(); that.addMonitorKeys(keys); } } that.addRawDataKeys(keys); that.addMonitorKeys = function addMonitorKeys(keys) { if (monitor) { monitor.addKeys(keys); } else { console.log('Creating new monitor'); monitor = new m.Monitor(keys); monitor.on('changed', handleCommand); monitor.connect(); } } that.stop = function() { if (monitor) { console.log('Stopping monitor'); monitor.disconnect(handleCommand); } } function handleCommand(key, command, args) { var i, t, u; var tlId, id, values; var key, suId, prop, v, enc, eng; var newUpdates = []; if(command === 'zadd') { var values = []; for(i = 0; i < args.length; i += 2) { t = Buffer.concat(args[i]).toString(); u = Buffer.concat(args[i + 1]).toString(); values.push(u); values.push(t); newUpdates.push(JSON.parse(u)); } addUpdates(values); moveServerWindow(); socket.emit('dUpdates', newUpdates); } } } |
The StreamAssembler uses the specific socket, passed as argument and created by the Node.js server through the socket.io module, to emit two different events: “updates”, for the initial updates retrieved from the Redis database, and “dUpdates”, for incremental updates detected by the redis-sync monitor.
Some examples: system performance monitoring
With the diagram described above in mind, I’ve been playing with Node.js, and Socket.io to implement some illustrative examples of how such architecture works and how to implement real-time communication with Browsers.
We could define a simple retriever of system performance data (e.g, top, netstat, …) and feed a Redis database with raw data from several hosts.
The StreamAssembler will transform the raw data into structured data, to be displayed by the Browser using the d3.js library.
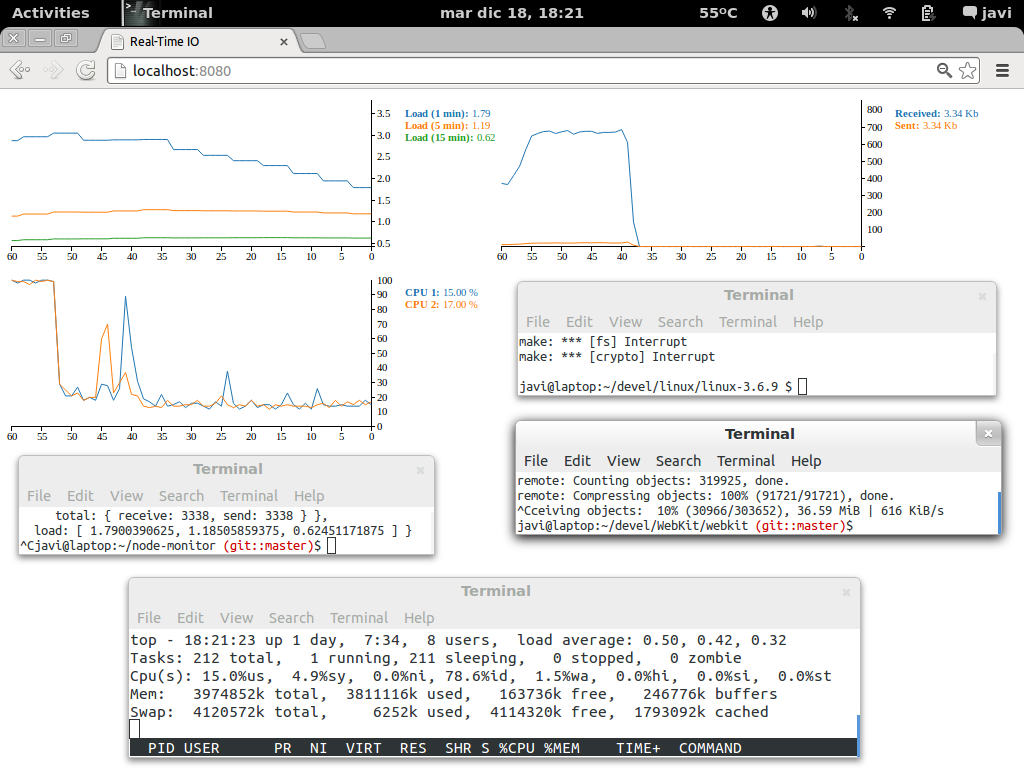
There is a video of the code running available here; check also the source code here. It’s just a small example of the use of Node.js + Socket.io and the StreamAssembler pattern.