In my previous post, when I introduced the switch to Skia for 2D rendering, I explained that we replaced Cairo with Skia keeping mostly the same architecture. This alone was an important improvement in performance, but still the graphics implementation was designed for Cairo and CPU rendering. Once we considered the switch to Skia as stable, we started to work on changes to take more advantage of Skia and GPU rendering to improve the performance even more. In this post I’m going to present some of those improvements and other not directly related to Skia and GPU rendering.
Explicit fence support
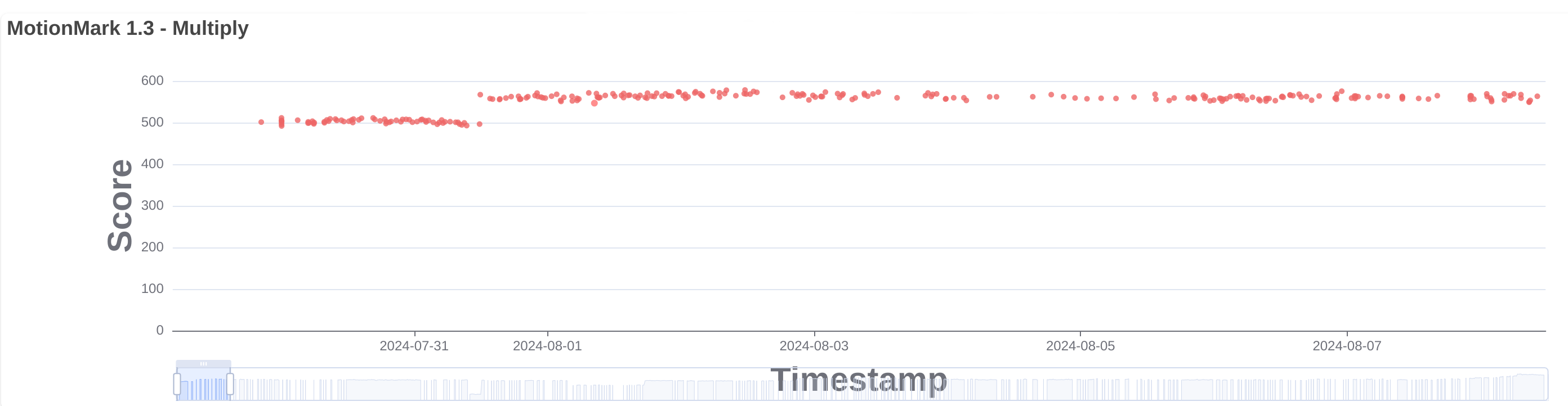
This is related to the DMA-BUF renderer used by the GTK port and WPE when using the new API. The composited buffer is shared as a DMA-BUF between the web and UI processes. Once the web process finished the composition we created a fence and waited for it, to make sure that when the UI process was notified that the composition was done the buffer was actually ready. This approach was safe, but slow. In 281640@main we introduced support for explicit fencing to the WPE port. When possible, an exportable fence is created, so that instead of waiting for it immediately, we export it as a file descriptor that is sent to the UI process as part of the message that notifies that a new frame has been composited. This unblocks the web process as soon as composition is done. When supported by the platform, for example in WPE under Wayland when the zwp_linux_explicit_synchronization_v1 protocol is available, the fence file descriptor is passed to the platform implementation. Otherwise, the UI process asynchronously waits for the fence by polling the file descriptor before passing the buffer to the platform. This is what we always do in the GTK port since 281744@main. This change improved the score of all MotionMark tests, see for example multiply.
Enable MSAA when available
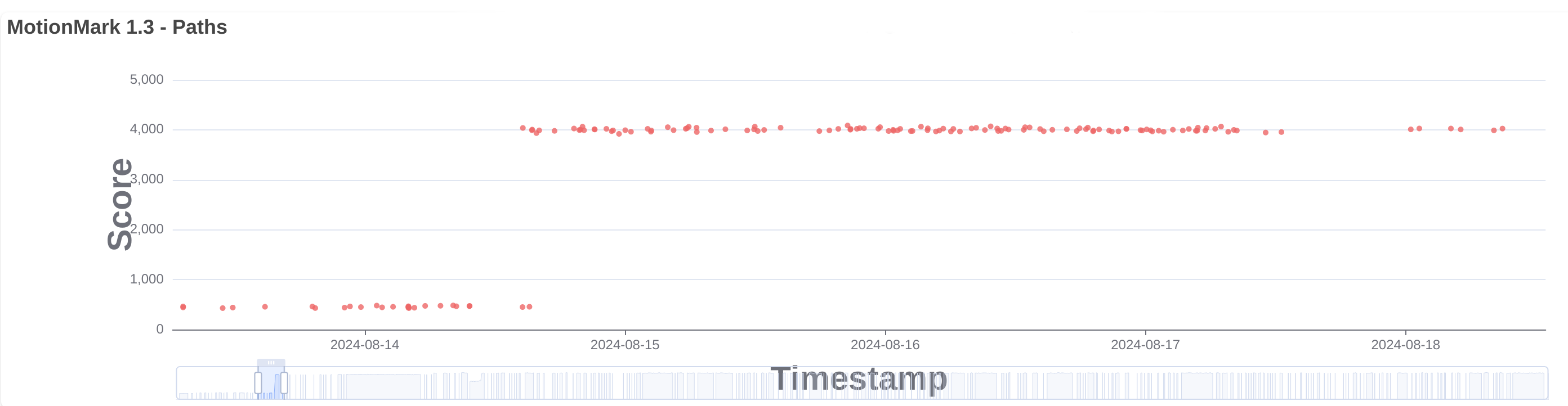
In 282223@main we enabled the support for MSAA when possible in the WPE port only, because this is more important for embedded devices where we use 4 samples providing good enough quality with a better performance. This change improved the Motion Mark tests that use 2D canvas like canvas arcs, paths and canvas lines. You can see here the change in paths when run in a RaspberryPi 4 with WPE 64 bits.
Avoid textures copies in accelerated 2D canvas
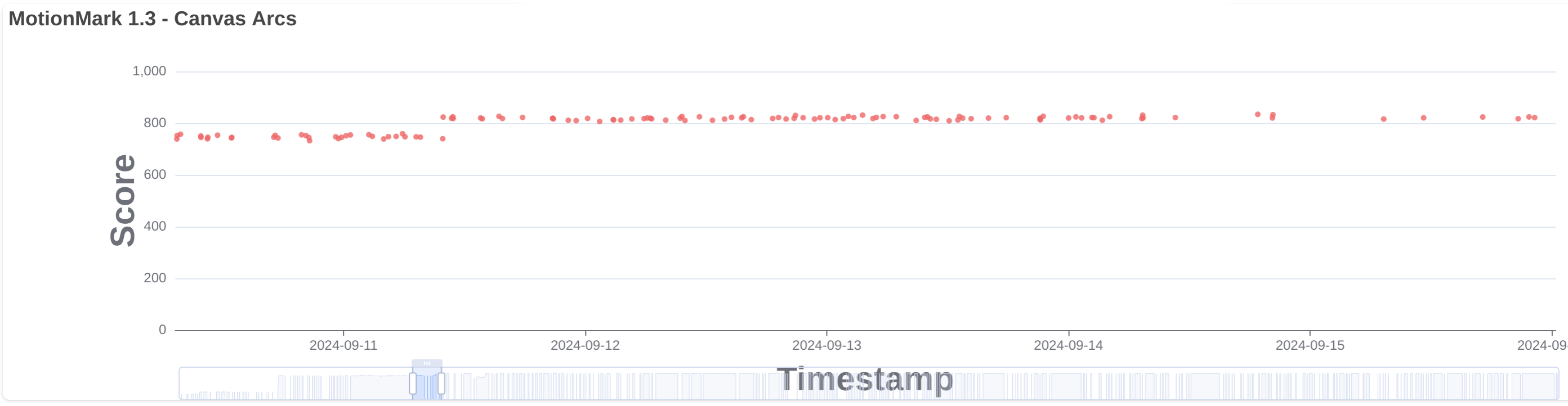
As I also explained in the previous post, when 2D canvas is accelerated we now use a dedicated layer that renders into a texture that is copied to be passed to the compositor. In 283460@main we changed the implementation to use a CoordinatedPlatformLayerBufferNativeImage to handle the canvas texture and avoid the copy, directly passing the texture to the compositor. This improved the MotionMark tests that use 2D canvas. See canvas arcs, for example.
Introduce threaded GPU painting mode
In the initial implementation of the GPU rendering mode, layers were painted in the main thread. In 287060@main we moved the rendering task to a dedicated thread when using the GPU, with the same threaded rendering architecture we have always used for CPU rendering, but limited to 1 worker thread. This improved the performance of several MotionMark tests like images, suits and multiply. See images.
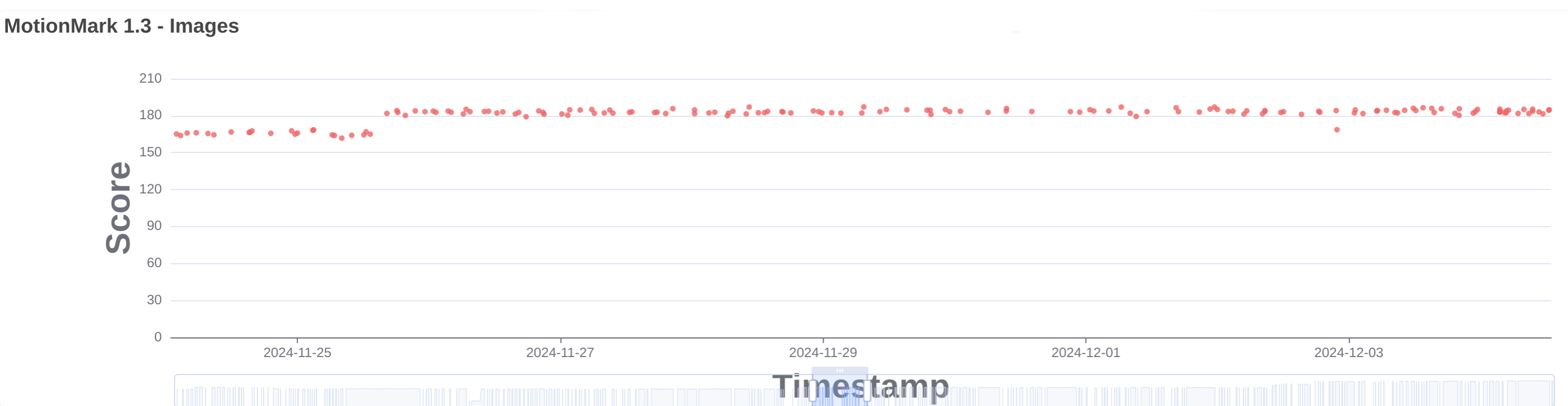
Update default GPU thread settings
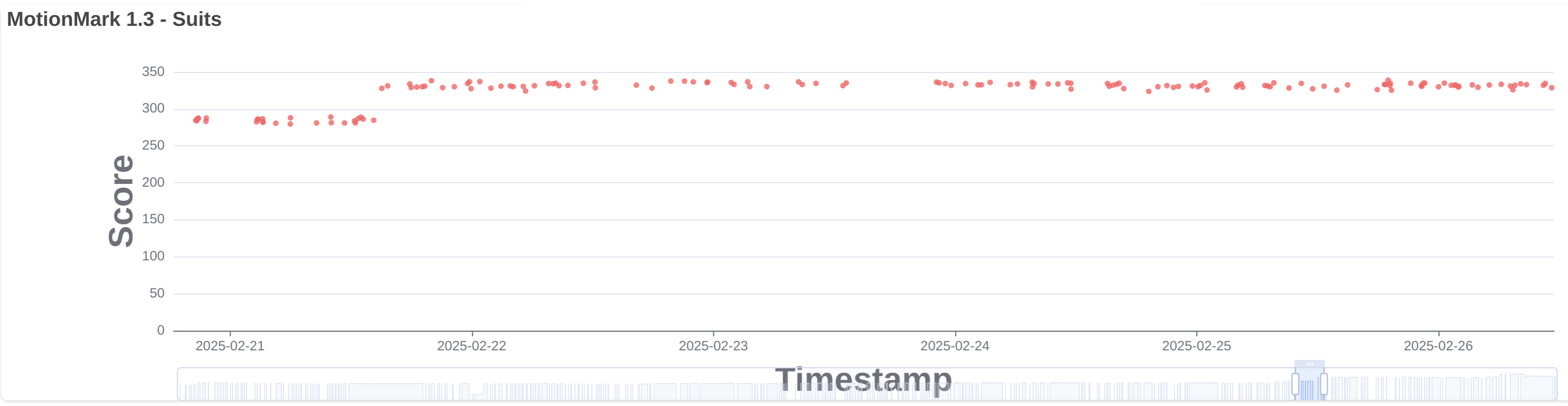
Parallelization is not so important for GPU rendering compared to CPU, but still we realized that we got better results by increasing a bit the amount of worker threads when doing GPU rendering. In 290781@main we increased the limit of GPU worker threads to 2 for systems with at least 4 CPU cores. This improved mainly images and suits in MotionMark. See suits.
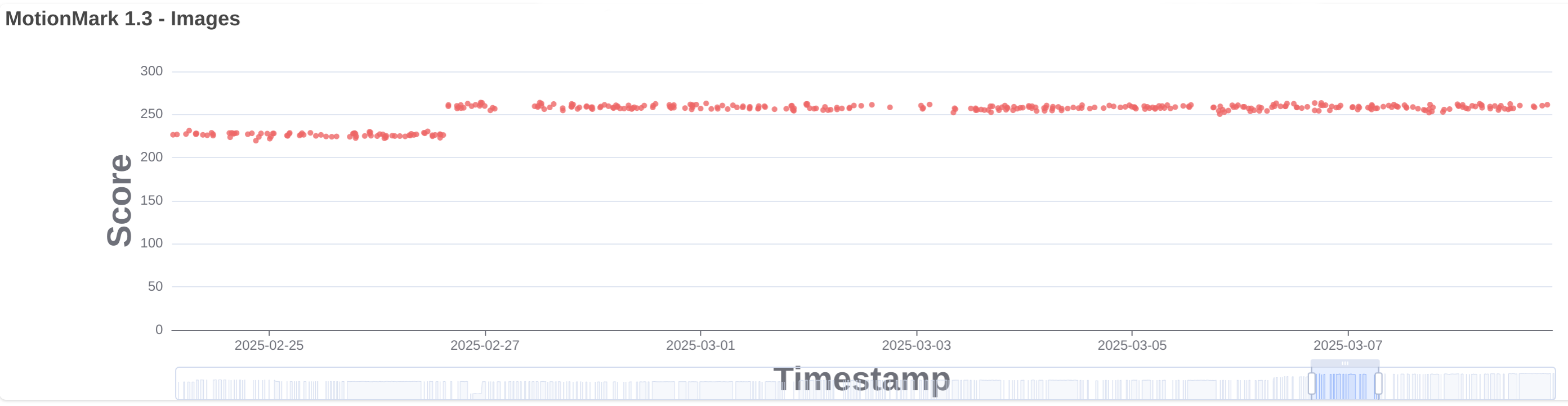
Hybrid threaded CPU+GPU rendering mode
We had either GPU or CPU worker threads for layer rendering. In systems with 4 CPU cores or more we now have 2 GPU worker threads. When those 2 threads are busy rendering, why not using the CPU to render other pending tiles? And the same applies when doing CPU rendering, when all workers are busy, could we use the GPU to render other pending tasks? We tried and turned out to be a good idea, especially in embedded devices. In 291106@main we introduced the hybrid mode, giving priority to GPU or CPU workers depending on the default rendering mode, and also taking into account special cases like on HiDPI, where we are always scaling, and we always prefer the GPU. This improved multiply, images and suits. See images.
Use Skia API for display list implementation
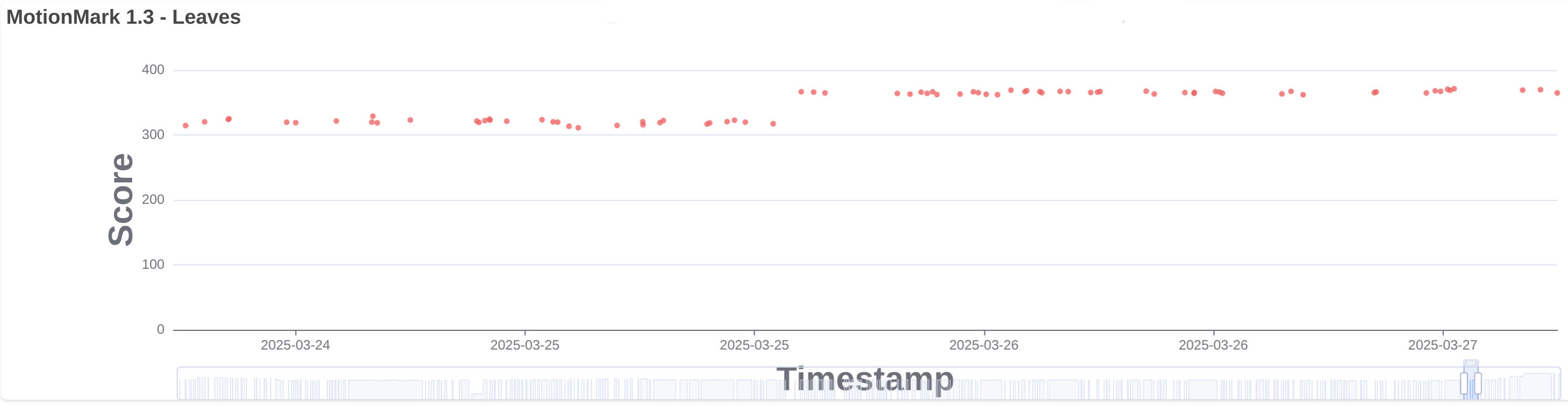
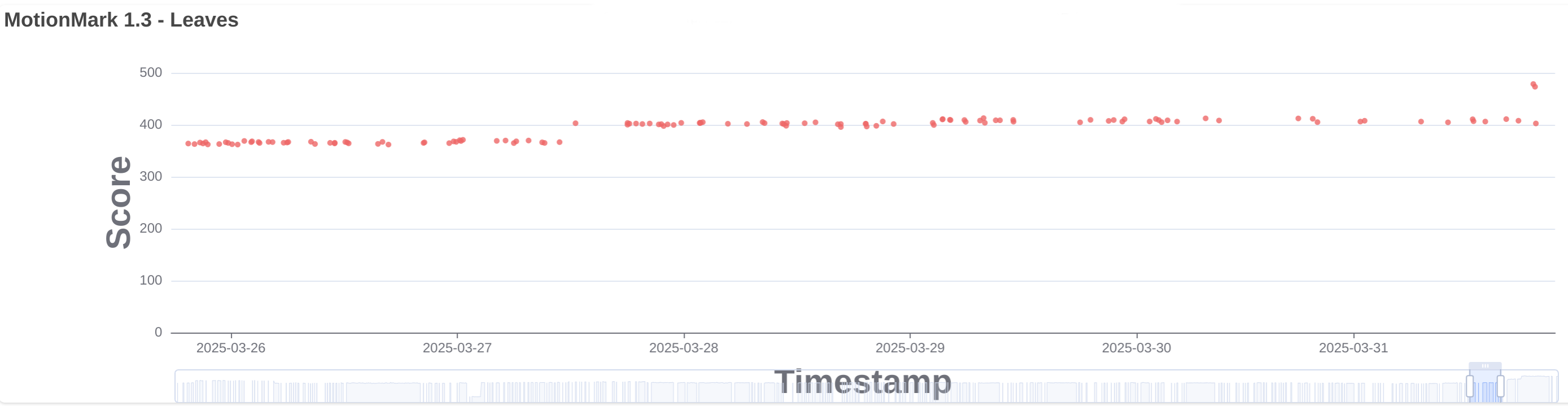
When rendering with Cairo and threaded rendering enabled we use our own implementation of display lists specific to Cairo. When switching to Skia we thought it was a good idea to use the WebCore display list implementation instead, since it’s cross-platform implementation shared with other ports. But we realized this implementation is not yet ready to support multiple threads, because it holds references to WebCore objects that are not thread safe. Main thread might change those objects before they have been processed by painting threads. So, we decided to try to use the Skia API (SkPicture) that supports recording in the main thread and replaying from worker threads. In 292639@main we replaced the WebCore display list usage by SkPicture. This was expected to be a neutral change in terms of performance but it surprisingly improved several MotionMark tests like leaves, multiply and suits. See leaves.
Use Damage to track the dirty region of GraphicsLayer
Every time there’s a change in a GraphicsLayer and it needs to be repainted, it’s notified and the area that changed is included so that we only render the parts of the layer that changed. That’s what we call the layer dirty region. It can happen that when there are many small updates in a layer we end up with lots of dirty regions on every layer flush. We used to have a limit of 32 dirty regions per layer, so that when more than 32 are added we just united them into the first dirty area. This limit was removed because we always unite the dirty areas for the same tiles when processing the updates to prepare the rendering tasks. However, we also tried to avoid handling the same dirty region twice, so every time a new dirty region was added we iterated the existing regions to check if it was already present. Without the 32 regions limit that means we ended up iterating a potentially very long list on every dirty region addition. The damage propagation feature uses a Damage class to efficiently handle dirty regions, so we thought we could reuse it to track the layer dirty region, bringing back the limit but uniting in a more efficient way than using always the first dirty area of the list. It also allowed to remove check for duplicated area in the list. This change was added in 292747@main and improved the performance of MotionMark leaves and multiply tests. See leaves.
Record all dirty tiles of a layer once
After the switch to use SkPicture for the display list implementation, we realized that this API would also allow to record the graphics layer once, using the bounding box of the dirty region, and then replay multiple times on worker threads for every dirty tile. Recording can be a very heavy operation, specially when there are shadows or filters, and it was always done for every tile due to the limitations of the previous display list implementation. In 292929@main we introduced the change with improvements in MotionMark leaves and multiply tests. See multiply.
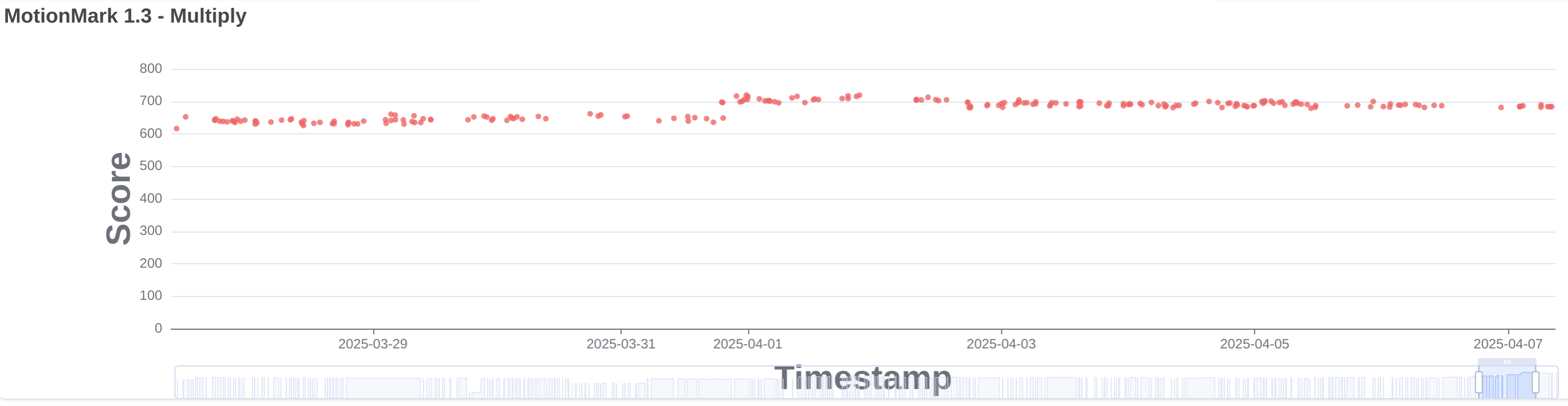
MotionMark results
I’ve shown here the improvements of these changes in some of the MotionMark tests. I have to say that some of those changes also introduced small regressions in other tests, but the global improvement is still noticeable. Here is a table with the scores of all tests before these improvements and current main branch run by WPE MiniBrowser in a RaspberryPi 4 (64bit).
| Test | Score July 2024 | Score April 2025 |
| Multiply | 501.17 | 684.23 |
| Canvas arcs | 140.24 | 828.05 |
| Canvas lines | 1613.93 | 3086.60 |
| Paths | 375.52 | 4255.65 |
| Leaves | 319.31 | 470.78 |
| Images | 162.69 | 267.78 |
| Suits | 232.91 | 445.80 |
| Design | 33.79 | 64.06 |
What’s next?
There’s still quite a lot of room for improvement, so we are already working on other features and exploring ideas to continue improving the performance. Some of those are:
- Damage tracking: this feature is already present, but disabled by default because it’s still work in progress. We currently use the damage information to only paint the areas of every layer that changed. But then we always compose a whole frame inside WebKit that is passed to the UI process to be presented on screen. It’s possible to use the damage information to improve both, the composition inside WebKit and the presentation of the composited frame on the screen. For more details about this feature read Pawel’s awesome blog post about it.
- Use DMA-BUF for tile textures to improve pixel transfer operations: We currently use DMA-BUF buffers to share the composited frame between the web and UI process. We are now exploring the idea of using DMA-BUF also for the textures used by the WebKit compositor to generate the frame. This would allow to improve the performance of pixel transfer operations, for example when doing CPU rendering we need to upload the dirty regions from main memory to a compositor texture on every composition. With DMA-BUF backed textures we can map the buffer into main memory and paint with the CPU directly into the mapped buffer.
- Compositor synchronization: We plan to try to improve the synchronization of the WebKit compositor with the system vblank and the different sources of composition (painted layers, video layers, CSS animations, WebGL, etc.)