In previous blog posts I talked about QEMU’s qcow2 file format and how to make it faster. This post gives an overview of how the data is structured inside the image and how that affects performance, and this presentation at KVM Forum 2017 goes further into the topic.
This time I will talk about a new extension to the qcow2 format that seeks to improve its performance and reduce its memory requirements.
Let’s start by describing the problem.
Limitations of qcow2
One of the most important parameters when creating a new qcow2 image is the cluster size. Much like a filesystem’s block size, the qcow2 cluster size indicates the minimum unit of allocation. One difference however is that while filesystems tend to use small blocks (4 KB is a common size in ext4, ntfs or hfs+) the standard qcow2 cluster size is 64 KB. This adds some overhead because QEMU always needs to write complete clusters so it often ends up doing copy-on-write and writing to the qcow2 image more data than what the virtual machine requested. This gets worse if the image has a backing file because then QEMU needs to copy data from there, so a write request not only becomes larger but it also involves additional read requests from the backing file(s).
Because of that qcow2 images with larger cluster sizes tend to:
- grow faster, wasting more disk space and duplicating data.
- increase the amount of necessary I/O during cluster allocation,
reducing the allocation performance.
Unfortunately, reducing the cluster size is in general not an option because it also has an impact on the amount of metadata used internally by qcow2 (reference counts, guest-to-host cluster mapping). Decreasing the cluster size increases the number of clusters and the amount of necessary metadata. This has direct negative impact on I/O performance, which can be mitigated by caching it in RAM, therefore increasing the memory requirements (the aforementioned post covers this in more detail).
Subcluster allocation
The problems described in the previous section are well-known consequences of the design of the qcow2 format and they have been discussed over the years.
I have been working on a way to improve the situation and the work is now finished and available in QEMU 5.2 as a new extension to the qcow2 format called extended L2 entries.
The so-called L2 tables are used to map guest addresses to data clusters. With extended L2 entries we can store more information about the status of each data cluster, and this allows us to have allocation at the subcluster level.
The basic idea is that data clusters are now divided into 32 subclusters of the same size, and each one of them can be allocated separately. This allows combining the benefits of larger cluster sizes (less metadata and RAM requirements) with the benefits of smaller units of allocation (less copy-on-write, smaller images). If the subcluster size matches the block size of the filesystem used inside the virtual machine then we can eliminate the need for copy-on-write entirely.
So with subcluster allocation we get:
- Sixteen times less metadata per unit of allocation, greatly reducing the amount of necessary L2 cache.
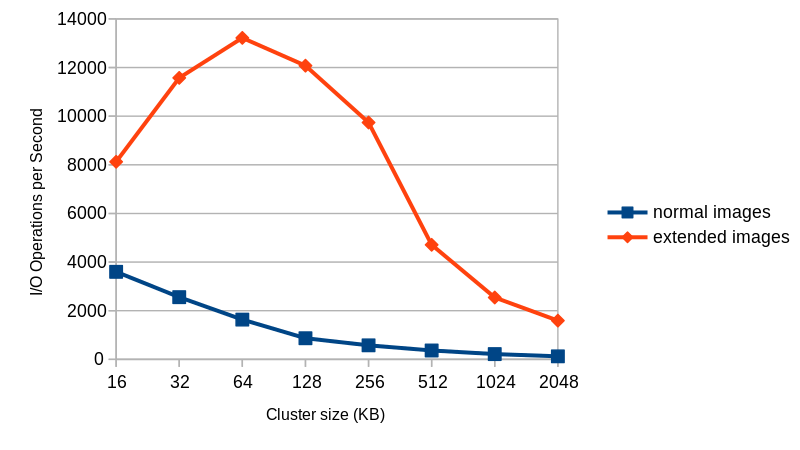
- Much faster I/O during allocation when the image has a backing file, up to 10-15 times more I/O operations per second for the same cluster size in my tests (see chart below).
- Smaller images and less duplication of data.
This figure shows the average number of I/O operations per second that I get with 4KB random write requests to an empty 40GB image with a fully populated backing file.
 |
Things to take into account:
- The performance improvements described earlier happen during allocation. Writing to already allocated (sub)clusters won’t be any faster.
- If the image does not have a backing file chances are that the allocation performance is equally fast, with or without extended L2 entries. This depends on the filesystem, so it should be tested before enabling this feature (but note that the other benefits mentioned above still apply).
- Images with extended L2 entries are sparse, that is, they have holes and because of that their apparent size will be larger than the actual disk usage.
- It is not recommended to enable this feature in compressed images, as compressed clusters cannot take advantage of any of the benefits.
- Images with extended L2 entries cannot be read with older versions of QEMU.
How to use this?
Extended L2 entries are available starting from QEMU 5.2. Due to the nature of the changes it is unlikely that this feature will be backported to an earlier version of QEMU.
In order to test this you simply need to create an image with extended_l2=on, and you also probably want to use a larger cluster size (the default is 64 KB, remember that every cluster has 32 subclusters). Here is an example:
$ qemu-img create -f qcow2 -o extended_l2=on,cluster_size=128k img.qcow2 1T
And that’s all you need to do. Once the image is created all allocations will happen at the subcluster level.
More information
This work was presented at the 2020 edition of the KVM Forum. Here is the video recording of the presentation, where I cover all this in more detail:
You can also find the slides here.
Acknowledgments
This work has been possible thanks to Outscale, who have been sponsoring Igalia and my work in QEMU.
 |
And thanks of course to the rest of the QEMU development team for their feedback and help with this!
I got more information from this one article than I have from many others on the topic – thanks for that. Out of interest, what is your recommendation for filesystem cluster sizes supporting qcow2 images? Specifically if you consider a filesystem based around ZFS, the record size of the dataset should be set to 64k I assume – or with extended L2 attributes – just match what is chosen when the image is created?
Thanks.
Hi,
I’m not familiar with how block allocation works on ZFS so I cannot really give you an informed opinion.
You are talking about the filesystem on the host, right? The only thing that I can tell you is that QEMU writes new data in multiples of the cluster size (or subcluster size with extended qcow2 images) so I imagine that as long as the qcow2 (sub)cluster size is a multiple of the filesystem block size then it’s all good.
is it possible to convert existing qemu images with the convert command to take advantage of a larger cluster size and the extended_l2 option like this:
mv hd.qcow2 hd.qcow2.bak
qemu-img convert -O qcow2 -o cluster_size=1M,extended_l2=on hd.qcow2.bak hd.qcow2
Yes, and the answer that you gave is precisely how you would do it.
>> It is not recommended to enable this feature in compressed images, as compressed clusters >> cannot take advantage of any of the benefits.
Regarding not to use compressed images, does that mean:
– the backing qcow2 image should not be compressed, and
– the linking qcow2 also should not be compressed
The image that you created with extended_l2=on should not be compressed.
The format of the backing file does not matter, it does not even need to be qcow2.
what kind of image type is compressed ?
“compressed” is not a separate image type, compression is a feature that qcow2 images support. See the qemu-img manpage for more details.
qemu-img seems to create zlib-compressed qcow2 images by default? Using the command you give at the end of the post (size adjusted):
$ qemu-img create -f qcow2 -o extended_l2=on,cluster_size=128k img.qcow2 25G
results in the following output:
Formatting ‘img.qcow2’, fmt=qcow2 cluster_size=131072 extended_l2=on compression_type=zlib size=26843545600 lazy_refcounts=off refcount_bits=16
man qemu-img only says this about compression_type:
> This option configures which compression algorithm will be used for compressed clusters on the image. Note that setting this option doesn’t yet cause the image to actually receive compressed writes. It is most commonly used with the -c option of qemu-img convert, but can also be used with the compress filter driver or backup block jobs with compression enabled.
Which doesn’t clarify what’s happening by default here.
A qcow2 image contains a collection of data clusters, that’s the data that you see from your VM.
All qcow2 images support compression, however strictly speaking there are no “compressed” and “uncompressed” images. Instead, each individual data cluster can be either compressed or uncompressed.
The compression algorithm used for those compressed clusters can be selected with the ‘compression_type’ option when creating the image. The current alternatives are zlib (default) or zstd.
When you create a new image using qemu-img a compression algorithm is selected and stored in the image header, but that does not mean that any data is going to be compressed. It means that **IF** a compressed cluster is written to the image it must use the selected algorithm.
Compression in qcow2 is read-only, so no matter what kind of image you have, when you are operating QEMU normally and the VM writes data, that data is always going be uncompressed.
However you can write compressed data if you are creating a new image converting it from an existing one:
$ qemu-img convert -f qcow2 -O qcow2 -c src.qcow2 dst.qcow2That ‘-c’ option there writes compressed data, so for simplicity I call this a “compressed image” since every single data cluster is compressed, but those clusters won’t benefit from the feature described in this blog post.
I hope it’s clear now.
A very superficial benchmark: create a 7z archive of all the files in system32 (just the files) to c:\temp\:
QCOW2 image wiht 128K, L2=on: 1:32min
QCOW2 image with 64K, L2=off: 0:26min
Really no difference in CrystalDiskMark between the two setups.
Not using any backing image though.
Hardly usefull to dray any conclusion other than 128K/L2 will not always give you better performance.
OS: Debian 12 (QEMU 7.2.2 / libvirt 9.0.0)
Hi, as the post explains you got the expected results for your tests.
And creating two 7z archives is not a reliable way to measure disk I/O performance… the fact that one of them was 3 times (!!) slower than the other when CrystalDiskMark says that there’s no difference should give you a hint 🙂
Hi Berto
Well, it’s a real-world testing, I find it more valid than CrystalDiskMark (as cache is most of it).
But why is this this the expected result, I must have missed something?
I did by the way try the same afterward using a backing image, same result.
Hi Brian,
this feature improves some specific aspects of qcow2 files, as explained in the presentation.
The problem with casually creating 7z archives is that you’re probably not measuring what you think you’re measuring, and there are many other factors that could be explaining the differences in your tests.
Also, if the image where you’re writing the data does not have a backing file the allocation performance is probably going to be the same in all cases. And even if it has a backing file you might not notice the difference, depending on several factors.
All this is to say that this is not a magic setting to speed up everyday tasks, so if this is what you were expecting I don’t think that you need to bother with this setting 🙂
Hi,
I’m doing some benchmark with fio 4k randwrite,
for images with backing_file, I’m seeing indeed to big performance gain (4000->22000iops)
but for image without backing_file, I don’t see any benefit, and a little bit less iops (with big 1TB image, a 20GB image don’t see any performance difference)
with a 20GB image, I’m around 22k iops randwrite 4K/randread 4k
with a 1TB image: (virtio-scsi + iothread)
fio –filename=/dev/sdb –direct=1 –rw=randwrite –bs=4k –iodepth=32 –ioengine=libaio –name=test
default l2-cache-size , extended_l2=off, cluster_size=64k : 2700 iops
l2-cache-size=8MB , extended_l2=off, cluster_size=64k: 2900 iops
l2-cache-size=64MB , extended_l2=off, cluster_size=64k: 5100 iops
l2-cache-size=128MB , extended_l2=off, cluster_size=64k : 22000 iops
default l2-cache-size , extended_l2=on, cluster_size=128k: 1500 iops
l2-cache-size=8MB , extended_l2=on, cluster_size=128k: 2000 iops
l2-cache-size=64MB , extended_l2=on, cluster_size=128k: 4500 iops
l2-cache-size=128MB , extended_l2=on, cluster_size=128k: 22000 iops
seem that performance is equal when the l2-cache-size is big enough to keep all in memory, I thinked that I could reduce the l2-cache-size, as they are less l2 metadatas ? or does I miss something ?
Hi, it’s normal that the performance is similar for images without backing files, I discuss that in the presentation at the 2:40 mark.
About the second question, in order to reduce the size of the L2 metadata you need to increase the cluster size, so you can try with 1MB or 2MB clusters. In those cases the subcluster sizes are 32KB and 64KB respectively (so it’s comparable with the default qcow2 image without subclusters, which have 64KB clusters). See the presentation at 13:35 for more details.
ah ok, thanks.
I’m going to do some benchs with 1MB cluster + l2_extended vs 64k wihout subcluster
Pingback: Converting QEMU qcow2 images directly to stdout | The world won't listen
i’m curious why this new feature which exists for a while now is having such a hard time to find it’s way as default settings into all hypervisor platforms, especially while it fixes issues of qcow2 on zfs: https://gitlab.com/qemu-project/qemu/-/work_items/3213 ( the slowness is NOT being triggered when qcow file is being created with qemu-img manually with preallocation=off.
surprisingly, it is also NOT being triggered when qcow2 being created with preallocation=metadata,extended_l2=on,cluster_size=128k as recommended at https://blogs.igalia.com/berto/2020/12/03/subcluster-allocation-for-qcow2-images/ )
as far is i know, no hypervisor/qemu project does use the better performing settings as default. anybody know the reason for that ?
I can think of a few reasons:
– Images created with extended_l2=on cannot be read with older versions of QEMU, so this can create interoperability issues.
– While it has plenty of test coverage and I haven’t heard of any serious bug since it was added, it hasn’t been as battle tested as the traditional qcow2 format.
– There are many standard workloads where the benefits that this brings are not so important, so it makes sense that you enable it only in the cases where you really need it.