The HTML Standard section on Custom Handlers describes the procedure to register custom protocol handlers for URLs with specific schemes. When a URL is followed, the protocol dictates which part of the system handles it by consulting registries. In some cases, handlers may fall to the OS level and and launch a desktop application (eg. mailto:// may launch a native application) or, the browser may redirect the request to a different HTTP(S) URL (eg. mailto:// can go to gmail).
There are multiple ways to invoke the registerProtocolHandler method from the HTML API. The most common is through Browser Extensions, or add-ons, where the user must install third-party software to add or modify a browser’s feature. However, this approach puts on the users the responsibility of ensuring the extension is secure and that it respects their privacy. Ideally, downstream browsers could ship built-in protocol handlers that take this load off of users, but this was previously difficult.
During the last years Igalia and Protocol Labs have been working on improving the support of this HTML API in several of the main web engines, with the long term goal of getting the IPFS protocol a first-class member inside the most relevant browsers.
In this post I’m going to explain the most recent improvements, especially in Chrome, and some side advantages for Chromium embedders that we got on the way.
Componentization of the Custom Handler logic
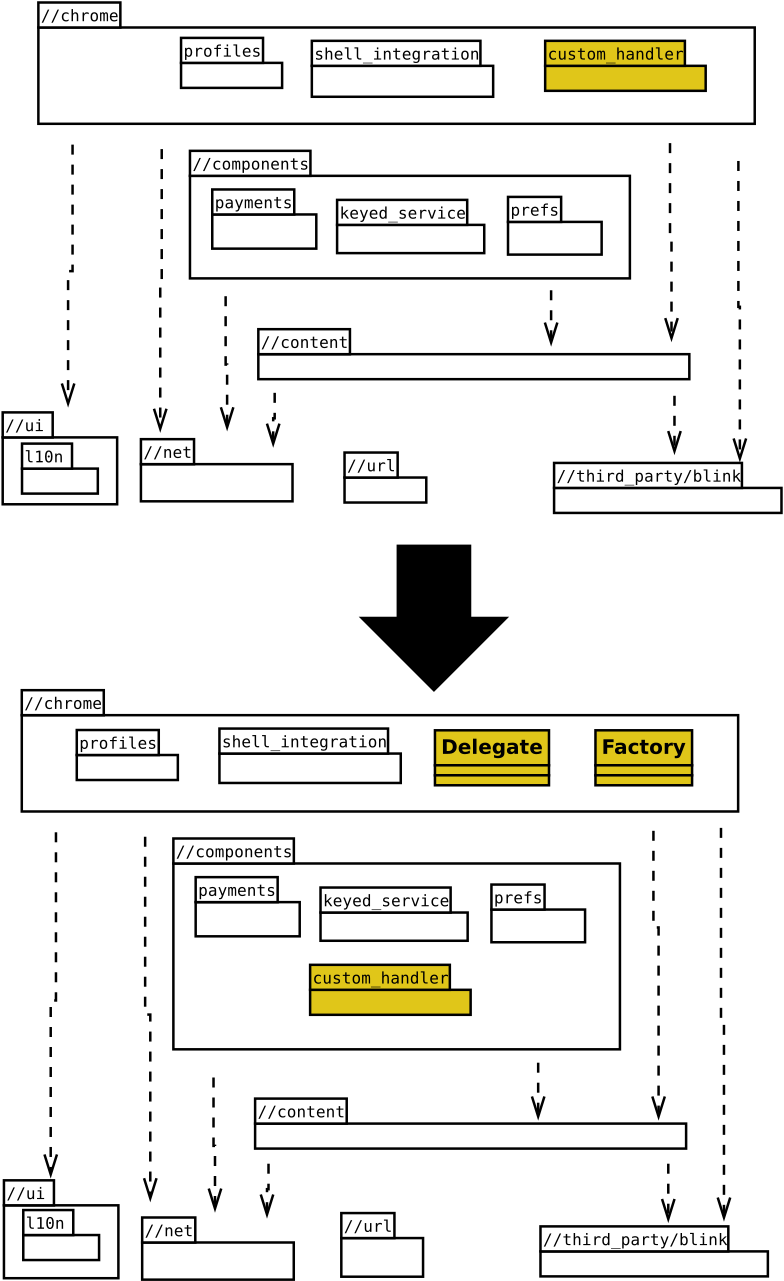
The first challenge faced by Chromium-based browsers wishing to add support for a new protocol was the architecture. Most of the logic and relevant codebase lived in the //chrome layer. Thus, any intent to introduce a behavior change on this logic would require a direct fork and patch the //chrome layers with the new logic. The design wasn’t defined to allow Chrome embedders to extend it with new features
The Chromium project provides a Public Content API to allow embedders reusing a great part of the browser’s common logic and to implement, if needed, specific behavior though the specialization of these APIs. These would seem to be the ideal way of extending the browser capabilities to handle new protocols. However, accessing //chrome from any layer (eg. //content or //components) is forbidden and constitutes a layering violation.
After some discussion with Chrome engineers (special thanks to Kuniko Yasuda and Colin Blundell) we decided to move the Protocol Handlers logic to the //components layer and create a new Custom Handlers component.
The following diagram provides a high-level overview of the architectural change:
Changes in the Chrome’s component design
The new component makes the Protocol Handler logic Chrome independent, bringing us the possibility of using the Content Public API to introduce the mentioned behavior changes, as we’ll see later in this post.
Only the registry’s Delegate and the Factory classes will remain in the //chrome layer.
The Delegate class was defined to provide OS integration, like setting as default browser, which needs to access the underlying operating systems interfaces. It also deals with other browser-specific logic, like Profiles. With the new componentized design, embedders may provide their own Delegate implementations with different strategies to interact with the operating system’s desktop or even support additional flavors.
On the other hand, the Factory (in addition to the creation of the appropriated Delegate’s instance) provides a BrowserContext that allows the registry to operate under Incognito mode.
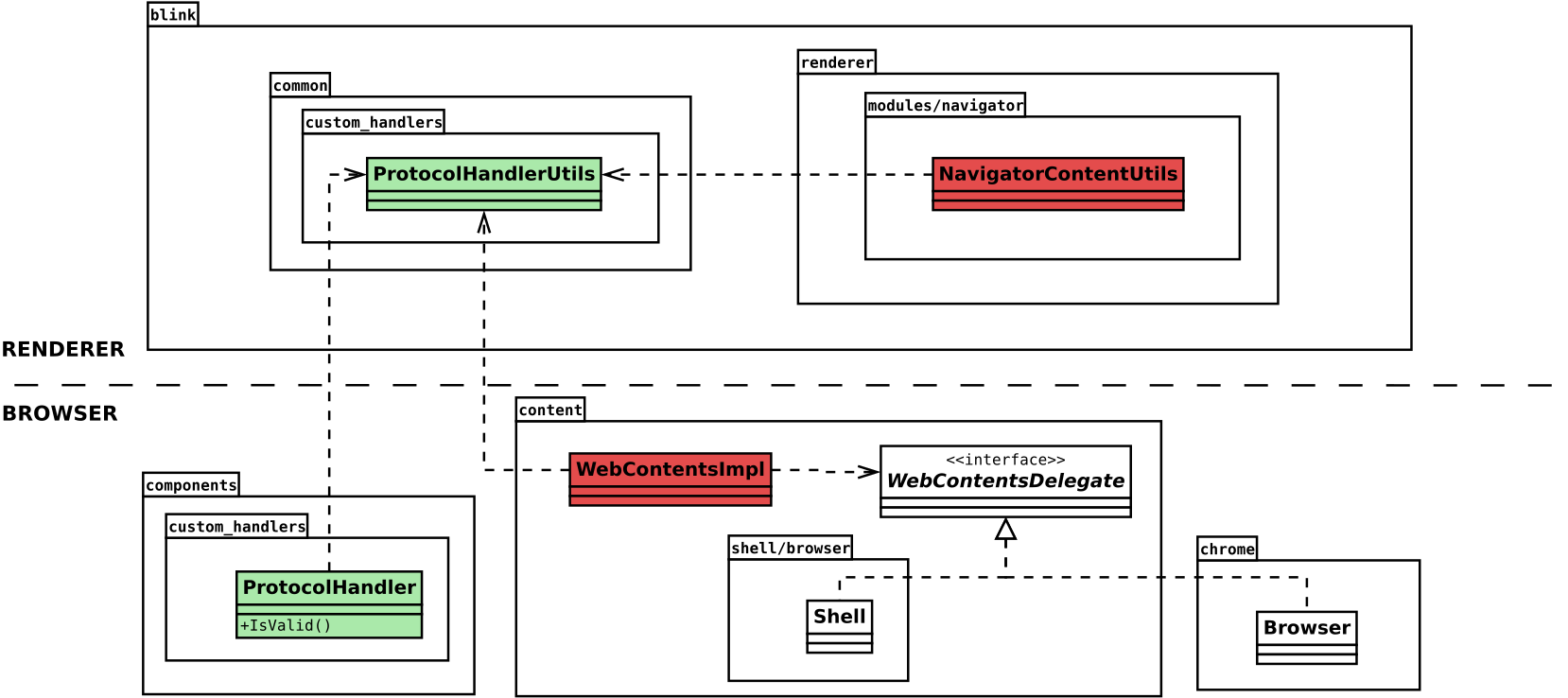
Lets now get a deeper look into the component, trying to understand the responsibilities of each class. The following class diagram illustrates the multi-process architecture of the Custom Handler logic:
Multi-process architecture class diagram
The ProtocolHandlerRegistry class has been modified to allow operating without user preferences storage; this is particularly useful to move most of the browser tests to the new component and avoid the dependency with the prefs and user_prefs components (eg. testing). In this scenario the registered handlers will be stored in memory only.
It’s worth mentioning that as part of this architectural change, I’ve applied some code cleanup and refactoring, following the policies dictated in the base::Value Code Health task-force. Some examples:
Get rid of DictionaryValue and ListValue (CL#3484122)
The ProtocolHandlerThrottle implements URL redirection with the handler provided by the registry. The ChromeContentBrowserClient and ShellBrowserContentClient classes use it to implement the CreateURLLoaderThrottles method of the ContentBrowserClient interface.
The specialized request is the responsible for handling the permission prompt dialog response, except for the the content-shell implementations, which bypass the Permission APIs (more on this later). I’ve also been working on a new design that relies on the PermissionContextBase::CreatePermissionRequest interface, so that we could create our own custom request and avoid the direct call to the PermissionRequestManager. Unfortunately this still needs some additional support to deal with the RegisterProtocolHandlerPermissionRequest‘s specific parameters needed for creating new instances, but I won’t extend on this, as it deserves its own post.
Finally, I’d like to remark that the new component provides a simple registry factory, designed mainly for testing purposes. It’s basically the same as the one implemented in the //chrome layer except some limitations of the new component:
No incognito mode
Use of a mocking Delegate (no actual OS interaction)
Single-Point security checks
I also wanted to apply some refactoring as well to improve the inter-process consistency and increase the amount of shared code between the renderer and browser process.
One of the most relevant parts of this refactoring was the one applied to the implement the Custom Handlers’ normalization process, which goes from some URL’s syntax validation to the security and privacy checks. I’ve landed some patches (CL#3507332, CL#3692750) to implement functions that are shared among the renderer and browser processes to implement the mentioned normalization procedure.
Security and privacy logic refactoring
The code has been moved to blink/common so that it could be invoked also by the new Custom Handlers component described before. Both the WebContentsImpl (run by the Browser process) and the NavigatorContentUtils (by the Renderer process) rely on this common code now.
Additionally, I have moved all the security and privacy checks from the Browser class, in Chrome, to the WebContentsImpl class. This implies that any embedder that implements the WebContentsDelegate interface shouldn’t need to bother about these checks, assuming that any ProtocolHandler instance is valid.
Conclusion
In the introduction I mentioned that the main goal of this refactoring was to decouple the Custom Handlers logic from the Chrome’s specific codebase; this would allow us to modify or even extend the implementation of the Custom Handlers APIs.
The componentization of some parts of the Chrome’s codebase has many advantages, as it’s described in the Browser Components design document. Additionally, a new Custom Handlers component would provide other interesting advantages on different fronts.
One of the most interesting use cases is the definition of Web Platform Tests for the Custom Handlers APIs. This goal has 2 main challenges to address:
Testing Automation
Content Shell support
Finally, we would like this new component to be useful for Chrome embedders, and even browsers built directly on top of a full featured Chrome, to implement new Custom Handlers related features. This line of work would eventually be useful to improve the support of distributed protocols like IPFS, as an intermediate step towards a native implementation of the protocols in the browser.
Chrome 84 reached the stable channel a few weeks ago, and there are already several great posts describing the many important additions, interesting new features, security fixes and improvements in privacy policies (([1], [2], [3], [4]) it contains. However, there is a change that I worked on in this release which might have passed unnoticed by most, but I think is very valuable: A change regarding CSS Custom Properties (variables) performance.
The design of CSS, in general, takes great care in considering how features are designed with respect to making it possible for them to perform well. However, implementations may not perform as well as they could, and it takes a considerable amount of time to understand how authors use the features and which cases are more relevant for them.
CSS Custom Properties are an interesting example to look at here: They are a wonderful feature that provides a lot of advantages for web authors. For a whole lot of cases, all of the implementations of CSS Custom Properties perform well enough that most people won’t notice. However, we at Igalia have been analyzing several use cases and looking at some reports around their performance in different implementations.
Let’s consider a fairly straightforward example in which an author sets a single property in a toggleable class in the body, and then uses that property several times deeper in the tree to change the foreground color of some text.
Only about 20% of those actually use this property, 5 elements deep into the tree, and only to change the foreground color.
To evaluate Chromium’s performance in a case like this we can define a new perf tests, using the perf tools the Chromium project has available for browser engineers. In this case, we want a huge tree so that we can evaluate better the impact of the different optimizations.
These are the results obtained runing the test in Chrome 83:
avg
median
stdev
min
max
163.74 ms
163.79 ms
3.69 ms
158.59 ms
163.74 ms
I admit that it’s difficult to evaluate the results, especially considering the number of nodes of such a huge DOM tree. Lets compare the results of the same test on Firefox, using different number of nodes.
Nodes
50K
20K
10K
5K
1K
500
Chrome 83
163.74 ms
55.05 ms
25.12 ms
14.18 ms
2.74 ms
1.50 ms
FF 78
28.35 ms
12.05 ms
6.10 ms
3.50 ms
1.15 ms
0.55 ms
1/6
1/5
1/4
1/4
1/2
1/3
As I commented before, the data are more accurate when the DOM tree has a lot of nodes; in any case, the difference is quite clear and shows there is plenty room for improvement. WebKit based browsers have results more similar to Chromium as well.
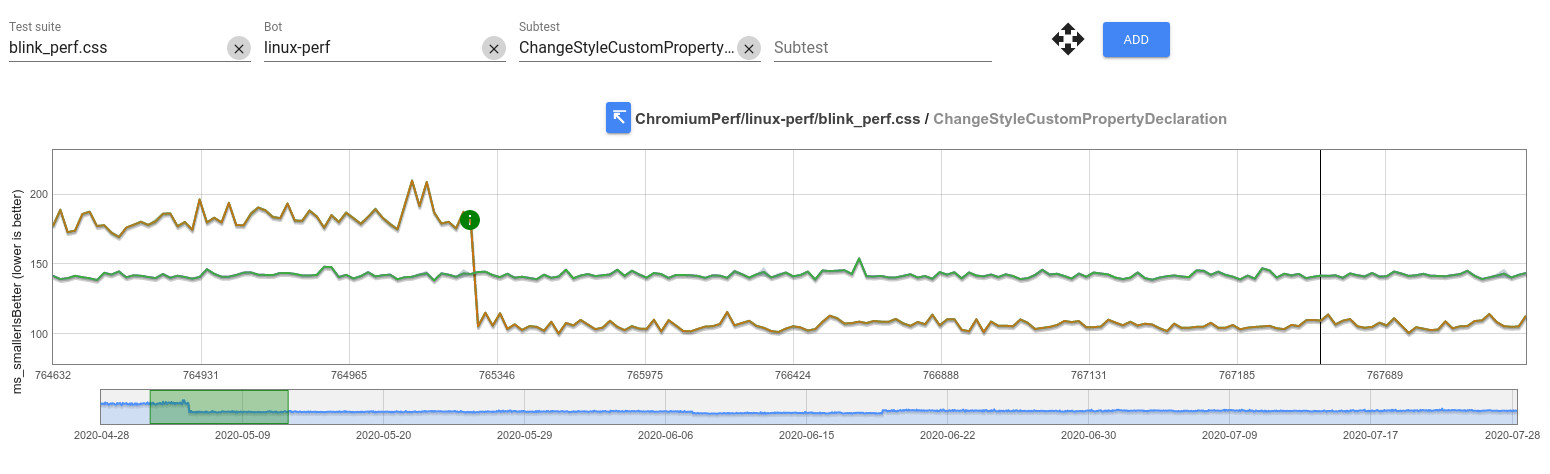
Performance tests like the one above can be added to browsers for tracking improvements and regressions over time, so we’ve added (r763335) that to Chromium’s tree: We’d like to see it get faster over time, and definitely cannot afford regressions (see Chrome Performance Dashboard and the ChangeStyleCustomPropertyDeclaration test for details) .
So… What can we do?
In Chrome 83 and lower, whenever the custom property declaration changed, the new declaration would be inherited by the whole tree. This inheritance implied executing the whole CSS cascade and recalculating the styles of all the nodes in the entire tree, since with this approach, all nodes may be affected.
Chrome had already implemented an optimization on the CSS cascade implementation for regular CSS properties that don’t depend on any other to resolve their value. These subset of CSS properties are defined as Independent Properties in the Chromium codebase. The optimization mentioned before affects how the inheritance mechanism is implemented for these Independent properties. Whenever one of these properties changes, instead of recalculating the styles of the inherited properties, children can just copy the whole parent’s computed style. Blink’s style engine has a component known as Matched Properties Cache responsible of deciding when is possible to avoid the style resolution of an element and instead, performing an efficient copy of the matched computed style. I’ll get back to this concept in the last part of this post.
In the case of CSS Custom Properties, we could apply a similar approach as a good step. We can consider that the nodes with computed styles that don’t have references to custom properties declarations shouldn’t be affected by the new declaration, and we can implement the inheritance directly by copying the parent’s computed style. The patch with the optimization I’ve implemented in r765278 initially landed in Chrome 84.0.4137.0
Let’s look at the result of this one action in the Chrome Performance Dashboard:
That’s a really good improvement!
However, it’s also just a first step. It’s clear that Chrome still has a wide margin for improvement in this case, as well any WebKit based browser – Firefox is still, impressively, markedly faster as it’s been described in the bug report filed to track this issue. The following table shows the result of the different browsers together; even disabling the muti-thread capabilities of Firefox’s Stylo engine (STYLO_THREAD=1), FF is much faster than Chrome with the optimization applied.
Chrome 83
Chrome 84
FF 78
FF 78 th=1
avg median stdev min max
163.74 ms
163.79 ms
3.69 ms
158.59 ms
163.74 ms
117.37 ms
117.52 ms
1.98 ms
113.66 ms
120.87 ms
28.35 ms
28.50 ms
0.93 ms
26.00 ms
30.00 ms
38.25 ms
38.50 ms
1.86 ms
35.00 ms
41.00 ms
Before continue, I want get back to the Matched Properties Cache (MPC) concept, since it has an important role on these style optimizations. This cache is not a new concept in the Chrome’s engine; as a matter of fact, it’s also used in WebKit, since it was implemented long ago, before the fork that created the new blink engine. However, Google has been working a lot on this area in the last years and some of the most recent changes in the MPC have had an important impact on style resolution performance. As a result of this work, elements with independent and non-independent properties using CSS Variables might produce cache hits in the MPC. The results of the Performance Dashboard show a considerable improvement in the mentioned ChangeStyleCustomPropertyDeclaration test (avg: 108.06 ms)
Additionally, there are several other cases where the use of CSS Variables has a considerable impact on performance, compared with using regular CSS properties. Obviously, resolving CSS Variables has a cost, so it’s clear that we could apply additional optimizations that reduce the impact of the variable resolution, especially for handling specific style changes that might not affect to a substantial portion of the DOM tree. I’ve been experimenting with the MPC to explore the idea an independent CSS Custom Properties cache; nodes with variables referencing the same custom property will produce cache hits in the MPC, even though other properties don’t match. The preliminary approach I’ve been implementing consists on a new matching function, specific for custom properties, and a mechanism to transfer/copy the property’s data to avoid resolving the variable again, since the property’s declaration hasn’t change. We would need to apply the css cascade again, but at least we could save the cost of the variable resolution.
Of course, at the end of the day, improving performance has costs and challenges – and it’s hard to keep performance even once you get it. Bit if we really want performant CSS Custom Properties, this means that we have to decide to prioritize this work. Currently there is reluctance to explore the concept of a new Custom Properties specific cache – the challenge is big and the risks are not non-existent; cache invalidation can get complicated. But, the point is that we have to understand that we aren’t all going to agree what is important enough to warrant attention, or how much investment, or when. Web authors must convince vendors that these use cases are worth being optimized and that the cost and risks of such a complex challenges should be assumed by them.
This work has been sponsored by Bloomberg, which I consider one of the most important contributors of the Web Platform. After several years, the vision of this company and its responsibility as consumer of the platform has lead to many and important contributions that we all enjoy now. Although CSS Grid Layout might be the most remarkable one, there are may other not that big, like this work on CSS Custom Properties, or several other new features of the CSS Text specification. This is a perfect example of an company that tries to change priorities and adapt the web platform to its needs and the use cases they consider more aligned with their business strategy.
I understand that not every user of the web platform can do this kind of investment. This is why I believe that initiatives like Open Priorization could help to move the web platform in a positive direction. By providing a way for us to move past a lot of these conversation and focus on the needs that some web authors and users of the platform consider more important, or higher priority. Improving performance for CSS Custom Properties isn’t currently one of the projects we’ve listed, but perhaps it would be an interesting one we might try in the future if we are successful with these. If you haven’t already, have a look and see if there is something there that is interesting to you or your company – pledges of any size are good – ten thousand $1 donations are every bit as good as ten $1000 donations. Together, we can make a difference, and we all benefit.
Also, we would love to hear about your ideas. Is improving CSS Custom Properties performance important to you? What else is? Share your comments with us on Twitter, either me (@lajava77) or our developer advocate Brian Kardell (@briankardell), or email me at jfernandez@igalia.com. I’d be glad to answer any question about the Open Priorization experiment.
The CSS Text 3 specification defines a module for text manipulation and covers, among a few other features, the line breaking behavior of the browser, including white space handling. I’ve been working lately on some new features and bug fixing for this specification and I’d like to introduce in this posts the last one we made available for the Web Platform users. This is yet another contribution that came out the collaboration between Igalia and Bloomberg, which has been held for several years now and has produced many important new features for the Web, like CSS Grid Layout.
The feature
I guess everybody knows the white-space CSS property, which allows web authors to control two main aspects of the rendering of a text line: collapsing and wrapping. A new value break-spaces has been added to the ones available for this property, which allows web authors to emulate a terminal-like line breaking behavior. This new value operates basically like pre-wrap, but with two key differences:
any sequence of preserved white space characters takes up space, even at the end of the line.
a preserved white space sequence can be wrapped at any character, moving the rest of the sequence, intact, to the line bellow.
What does this new behavior actually mean ? I’ll try to explain it with a few examples. Lets start with a simple but quite illustrative demo which tries to emulate a meteorology monitoring system which shows relevant changes over time, where the gaps between subsequent changes must be preserved:
Another interesting use case for this feature could be a logging system which should preserve the text formatting of the logged information, considering different window sizes. The following demo tries to describe this such scenario:
In the demo shown before there are several cases that I think it’s worth to analyze in detail.
A breaking opportunity exists after any white space character
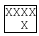
The main purpose of this feature is to preserve the white space sequences length even when it has to be wrapped into multiple lines. The following example tries to describe this basic use case:
The example above shows how the white space sequence with a length of 15 characters is preserved and wrapped along 3 different lines.
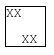
Single leading white space
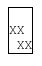
Before the addition of the break-spaces value this scenario was only possible at the beginning of the line. In any other case, the trailing white spaces were either collapsed or hang, hence the next line couldn’t start with a sequence of white spaces. Lets consider the following example:
Like when using pre-wrap, the single leading space is preserved. Since break-spaces allows breaking opportunities after any white space character, we break after the first leading white space (” |XX XX”). The second line can be broken after the first preserved white space, creating another leading white space in the next line (” |XX | XX”).
However, lets consider now a case without such first single leading white space.
Again, it s not allowed to break before the first space, but in this case there isn’t any previous breaking opportunity, so the first space after the word XX should overflow (“XXX | XX”); the next white space character will be moved down to the next line as preserved leading space.
Breaking before the first white space
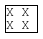
I mentioned before that the spec states clearly that the break-space feature allows breaking opportunities only after white space characters. However, it’d be possible to break the line just before the first white space character after a word if the feature is used in combination with other line breaking CSS properties, like word-break or overflow-wrap (and other properties too).
The two white spaces between the words are preserved due to the break-spaces feature, but the first space after the XXXX word would overflow. Hence, the overflow-wrap: break-word feature is applied to prevent the line to overflow and introduce an additional breaking opportunity just before the first space after the word. This behavior causes that the trailing spaces are moved down as a leading white space sequence in the next line.
We would get the same rendering if word-break: break-all is used instead overflow-wrap (or even in combination), but this is actualy an incorrect behavior, which has the corresponding bug reports in WebKit (197277) and Blink (952254) according to the discussion in the CSS WG (see issue #3701).
Consider previous breaking opportunities
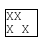
In the previous example I described a combination of line breaking features that would allow breaking before the first space after a word. However, this should be avoided if there are previous breaking opportunities. The following example is one of the possible scenarios where this may happen:
In this case, we could break after the second word (“XX X| X”), since overflow-wrap: break-word would allow us to do that in order to avoid the line to overflow due to the following white space. However, white-space: break-spaces only allows breaking opportunities after a space character, hence, we shouldn’t break before if there are valid previous opportunities, like in this case in the space after the first word (“XX |X X”).
This preference for previous breaking opportunities before breaking the word, honoring the overflow-wrap property, is also part of the behavior defined for the white-space: pre-wrap feature; although in that case, there is no need to deal with the issue of breaking before the first space after a word since trailing space will just hang. The following example uses just the pre-wrap to show how previous opportunities are selected to avoid overflow or breaking a word (unless explicitly requested by word-break property).
In this case, break-all enables breaking opportunities that are not available otherwise (we can break a word at any letter), which can be used to prevent the line to overflow; hence, the overflow-wrap property doesn’t take any effect. The existence of previous opportunities is not considered now, since break-all mandates to produce the longer line as possible.
This new white-space: break-spaces feature implies a different behavior when used in combination with break-all. Even though the preference of previous opportunities should be ignored if we use the word-break: break-all, this may not be the case for the breaking before the first space after a word scenario. Lets consider the same example but using now the word-break: break-all feature:
The example above shows that using word-break: break-all doesn’t produce any effect. It’s debatable whether the use of break-all should force the selection of the breaking opportunity that produces the longest line, like it happened in the pre-wrap case described before. However, the spec states clearly that break-spaces should only allow breaking opportunities after white space characters. Hence, I considered that breaking before the first space should only happen if there is no other choice.
As a matter of fact, specifying break-all we shouldn’t considering only previous white spaces, to avoid breaking before the first white space after a word; the break-all feature creates additional breaking opportunities, indeed, since it allows to break the word at any character. Since break-all is intended to produce the longest line as possible, this new breaking opportunity should be chosen over any previous white space. See the following test case to get a clearer idea of this scenario:
Bear in mind that the expected rendering in the above example may not be obtained if your browser’s version is still affected by the bugs 197277(Safari/WebKit) and 952254(Chrome/Blink). In this case, the word is broken despite the opportunity in the previous white space, and also avoiding breaking after the ‘XX’ word, just before the white space.
There is an exception to the rule of avoiding breaking before the first white space after a word if there are previous opportunities, and it’s precisely the behavior the line-break: anywhere feature would provide. As I said, all these assumptions were not, in my opinion, clearly defined in the current spec, so that’s why I filed an issue for the CSS WG so that we can clarify when it’s allowed to break before the first space.
Current status and support
The intent-to-ship request for Chrome has been approved recently, so I’m confident the feature will be enabled by default in Chrome 76. However, it’s possible to try the feature in older versions by enabling the Experimental Web Platform Features flag. More details in the corresponding Chrome Status entry. I want to highlight that I also implemented the feature for LayoutNG, the new layout engine that Chrome will eventually ship; this achievement is very important to ensure the stability of the feature in future versions of Chrome.
In the case of Safari, the patch with the implementation of the feature landed in the WebKit’s trunk in r244036, but since Apple doesn’t announce publicly when a new release of Safari will happen or which features it’ll ship, it’s hard to guess when the break-spaces feature will be available for the web authors using such browser. Meanwhile, It’s possible to try the feature in the Safari Technology Preview 80.
Finally, while I haven’t see any signal of active development in Firefox, some of the Mozilla developers working on this area of the Gecko engine have shown public support for the feature.
The following table summarizes the support of the break-spaces feature in the 3 main browsers:
At Igalia we believe that the Web Platform Tests project is a key piece to ensure the compatibility and interoperability of any development on the Web Platform. That’s why a substantial part of my work to implement this relatively small feature was the definition of enough tests to cover the new functionality and basic use cases of the feature.
During the implementation of a browser feature, even a small one like this, it’s quite usual to find out bugs and interoperability issues. Even though this may slow down the implementation of the feature, it’s also a source of additional Web Platform tests and it may contribute to the robustness of the feature itself and the related CSS properties and values. That’s why I decided to implement the feature in parallel for WebKit (Safari) and Blink (Chrome) engines, which I think it helped to ensure interoperability and code maturity. This approach also helped to get a deeper understanding of the line breaking logic and its design and implementation in different web engines.
I think it’s worth mentioning some of these code architectural differences, to get a better understanding of the work and challenges this feature required until it reached web author’s browser.
Chrome/Blink engine
Lets start with Chrome/Blink, which was especially challenging due to the fact that Blink is implementing a new layout engine (LayoutNG). The implementation for the legacy layout engine was the first step, since it ensures the feature will arrive earlier, even behind an experimental runtime flag.
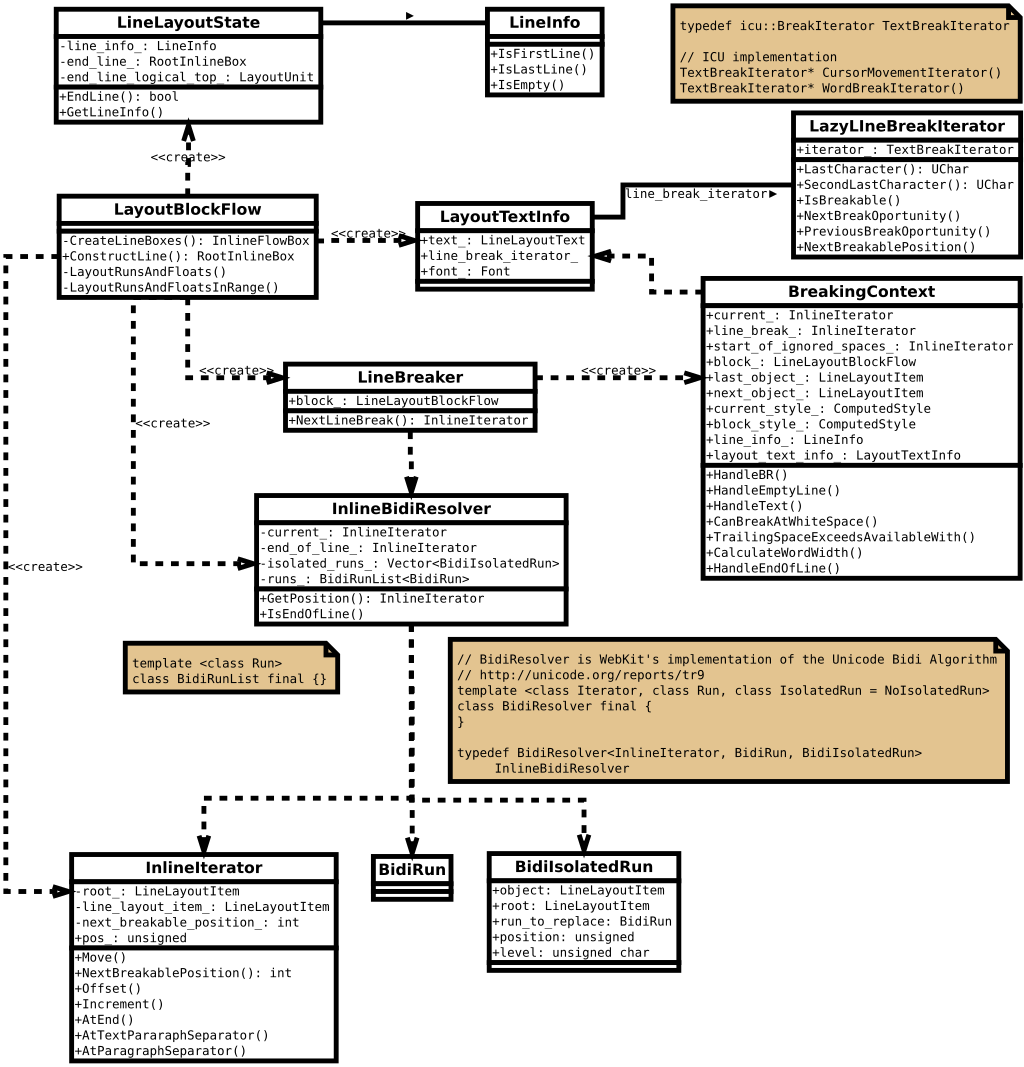
The legacy layout relies on the BreakingContext class to implement the line breaking logic for the inline layout operations. It has the main characteristic of handling the white space breaking opportunities by its own, instead of using the TextBreakIterator (based on ICU libraries), as it does for determining breaking opportunities between letters and/or symbols. This design implies too much complexity to do even small changes like this, especially because is very sensible in terms of performance impact. In the following diagram I try to show a simplified view of the classes involved and the interactions implemented by this line breaking logic.
The LayoutNG line breaking logic is based on a new concept of fragments, mainly handled by the NGLineBreaker class. This new design simplifies the line breaking logic considerably and it’s highly optimized and adapted to get the most of the TextBreakIterator classes and the ICU features. I tried to show a simplified view of this new design with the following diagram:
Although as time passes this is less probable, WebKit and Blink still share some of the layout logic from the ages prior to the fork. Although Blink engineers have applied important changes to the inline layout logic, both code refactoring and optimizations, there are common design patterns that made relatively easy porting to WebKit the patches that implemented the feature for the Blink’s legacy layout. In WebKit, the line breaking logic is also implemented by the BreakingContext class and it has a similar architecture, as it’s described, in a quite simplified way, in the class diagram above (it uses different class names for the render/layout objects, though) .
However, Safari supports for the mac and iOS platforms a different code path for the line breaking logic, implemented in the SimpleLineLayout class. This class provides a different design for the line breaking logic, and, similar to what Blink implements in LayoutNG, is based on a concept of text fragments. It also relies as much as possible into the TextBreakIterator, instead of implementing complex rules to handle white spaces and breaking opportunities. The following diagrams show this alternate design to implement the line breaking process.
This SimpleLineLayout code path in not supported by other WebKit ports (like WebKitGtk+ or WPE) and it’s not available either when using some CSS Text features or specific fonts. There are other limitations to use this SimpleLineLayout codepath, which may lead to render the text using the BreakingContext class.
I hope that at this point these 2 facts are clear now:
The white-space: break-spaces feature is a very simple but powerful feature that provides a new line breaking behavior, based on unix-terminal systems.
Although it’s a simple feature, on the paper (spec), it implies a considerable amount of work so that it reaches the browser and it’s available for web authors.
In this post I tried to explain in a simple way the main purpose of this new feature and also some interesting corner cases and combinations with other Line Breaking features. The demos I used shown 2 different use cases of this feature, but there are may more. I’m sure the creativity of web authors will push the feature to the limits; by then, I’ll be happy to answer doubts, about the spec or the implementation for the web engines, and of course fix the bugs that may appear once the feature is more used.
Igalia and Bloomberg working together to build a better web
Finally, I want to thank Bloomberg for supporting the work to implement this feature. It’s another example of how non-browser vendors can influence the Web Platform and contribute with actual features that will be eventually available for web authors. This is the kind of vision that we need if we want to keep a healthy, open and independent Web Platform.
I had the pleasure to attend the Web Engines Hackfest last week, hosted and organized by Igalia in its HQ in A Coruña. I’m really proud of what we are achieving with this event, thank so much to everybody involved in the organization but, specially, to the people attending. This year we had a lot of talent in a single place, hacking and sharing their expertise on the Web Platform; I really think we all have pushed the Web Platform forward during these days.
As you may already know, I’m part of the Web Platform team at Igalia working on the implementation of the CSS Grid Layout feature for Blink and WebKit web engines. This work has been sponsored by Bloomberg, as part of the collaboration we started several years ago to improve the Web Platform in many areas, from JS (V8, JSC and even ChakraCore) to different modules of the layout engine (eg. CSS features, editing/selection).
Since the day I received the invitation to attend the hackfest I knew that one of the tasks I wanted to hack on was the implementation of the CSS Grid feature in the new Chromium’s layout engine (still experimental), known as LayoutNG. Having Chistinan Biesinger, one of the Google engineers working on LayoutNG, here during 3 days was so good to let pass by the oportunity to, at least, start this task. I asked him to give a lighting talk during the layout breakout session about the current status of the LayoutNG project, a brief explanation of some of the most relevant details of its logic and its advantages with the current layout.
Layout Breakout Session
A small group of people interested on layout met to discuss about the future of layout in different web engines. I attended with some folks representing Igalia, and other people from Mozilla, Google, WebKit and ARM.
Christian described the key parts of the new LayoutNG, which provides a simpler code and generally better performance (although results are still preliminary since its under development phase). The concept of fragments gained relevance in this new layout model and currently, inline and block layout is basically complete; the multicolumn layout is quite advanced while Flexbox is still in the early stages (although a substantial portion of the layout tests are passing now).
We discussed about the different strategies that Firefox, Chrome and Safari are following to redesign the layout logic, which has a huge legacy codebase required to support the old web along the last years. However, browsers need to adapt to the new layout models that a modern Web Platform requires. Chrome with LayoutNG implies a clear bet, with a big team and strong determination; it seems it’ll be ready to ship in the first months of 2019. Firefox is also starting to implement a new layout design with Servo, although I couldn’t get details about its current status and plans. Finally, WebKit started a few months ago a new project called Next-Generation layout which tries to implement a new Layout Formatting Context (LFC) logic from scratch, getting rid f the huge technical debt acquired during the last years; although I couldn’t get confirmation, my opinion is that it’s still an experimental project.
We also had time to talk about the effort ARM is doing towards a better parallelization of the CSS parsing and style recalc logic, following a similar approach to Mozilla’s Sylo in Servo. It’s a very intresting initiative, but still quite experimental. There is some progress on specific codepahts, but still dealing with Oilpan (Blink’s Garbage Collector) which is the root cause of several issues that prevents to obtain an effective parallelization.
Hacking, hacking, hacking, ….
As I commented, this event is designed precisely to gather together some of the most brilliant minds in the Web Platform to discuss, analyze and hack on complex topics that are usually very difficult to handle when working remotely. I had a clear hacking task this time, so that’s why I decided to focus a bit more on coding. Although I already had assumed that implementing CSS Grid in LayoutNG would be a huge challenge, I decided to take it and at least start the task. I took as reference the Flexible Box implementation, which is under development right now and something Christian was partially involved on.
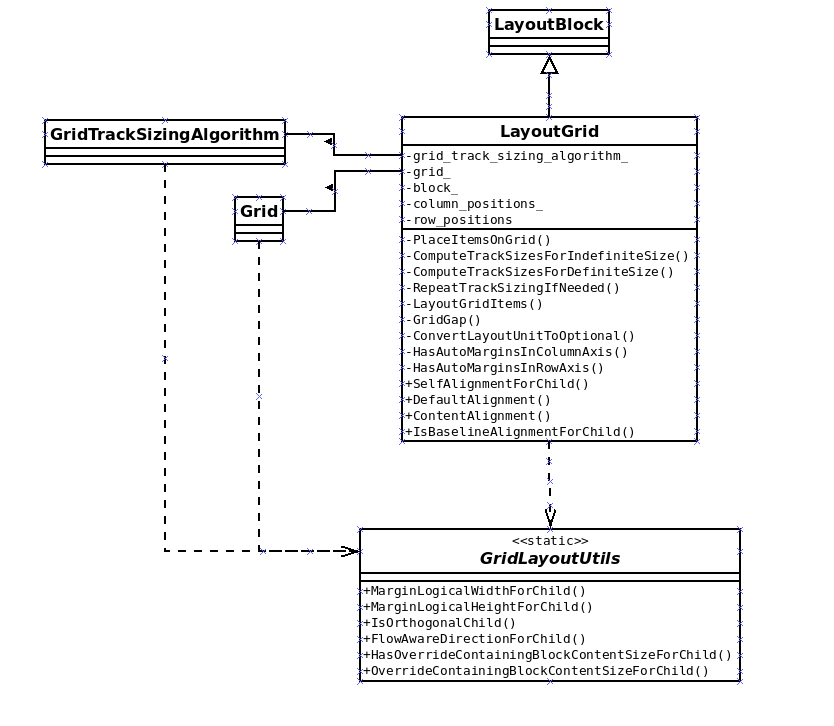
As it happened with the Flexbible Box implementation, the first step was to redesign the logic so that we can get rid of the dependency of the old Layout Tree, in this case, the LayoutGrid class. This has ben a complex and long task, which took me a quite big part of my time during the hackfest. The following diagrams show the redesign effort achieved, which I’d admit is still a preliminary approach that needs to be refined:
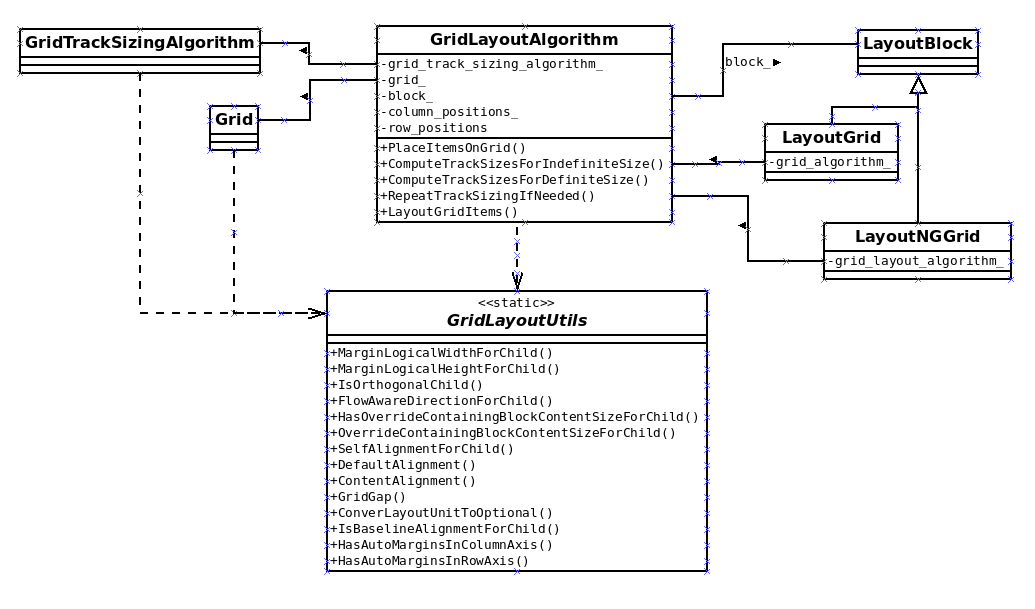
The next step was to implement an skeleton of the new layout-ng grid algorithm. Thanks to Christian’s direction, I quickly figure out how to do it and it looks like something like this:
Finally, I tried to implement the Grid layout’s algorithm, according to the CSS Grid Layout feature’s specification, using the new LayoutNG APIs. This is the more complex tasks, since I still have to learn how sizing and positioning functions are used on the new layout logic, specially how to use the new Fragments and ContainerBuilder concepts.
I submitted a WIP CL so that anybody can take a look, give suggestions or continue with the work. My plan is to devote some time to this challenge, every now and then, but I can’t set specifc goals or schedule for the time being. If anybody wants to speed up this task, perhaps it’d be possible to fund a project, which Igalia would be happy to participate.
Other Web Engines Hackfest stories
I also tried to attend some of the talks give during the hackfest and participate in a few breakout sessions. I’ll give now my impression of some of the ones I liked more.
I enjoyed a lot the one given by Camille Lamy, Colin Blundell and Robert Kroeger (Google) about the Chrome’s Servicification project. The new services design they are implementing is awesome and it will improve for sure Chrome modularity and codebase maintenance.
I participated in the MathML breakout session, which has somehow related to LayoutNG. Igalia launched a crowfunding campaign to implement the MathML specification in Chrome, using the new LayoutNG APIs. We thin that MathML could be a great success case for the new LayoutNG APIs, which has the goal of provide a stable API to implement new and complex layout models. This model will provide flexibility to the web engine, proving an easier way to implement new layout models without depending too much on the Chrome development cycle. In a way, this development model could be similar to a polyfill, but it’s integrated in the browser as native code instead of via external libraries.
As a member of the Igalia\’s team implementing the CSS Grid Layout feature for Blink and WebKit rendering engines, I\’m very proud of what we\’ve achieved from our collaboration with Bloomberg. I think Grid is a very interesting feature for the Web Platform and we still can\’t see all its potential.
One of my main assignments on this project is to implement the CSS Box Alignment spec for Grid. It\’s obvious that alignment is an important feature for many cases in web development, but I consider it a key for a layout model like the one Grid provides.
We recently announced that the patch implementing the self-baseline alignment landed in Blink. This was the last alignment functionality pending to implement, so now we can consider that the spec is complete for Grid. However, implementing a feature like CSS Box Alignment has an additional complexity in the form of interoperability issues.
Interoperability is always a challenge when implementing any new specification, but I think it\’s specially problematic for a feature like this for several reasons:
The feature applies to several layout models.
The CSS Flexible Box specification already defined some of the CSS properties and values.
Once a new layout model implements the new specification, Flexbox is forced to follow it as well.
I admit that the editors of this new specification document made a huge effort to keep backward compatibility with the Flexbox spec (which caused not so few implementation challenges). However, the current Flexbox implementation of the CSS properties and values that both specs have in common would become a Partial Implementation regarding the new spec.
Recently Florian Rivoal found out that this partial implementation of the CSS Box Alignment feature prevents the use of cascade or @support for providing customized fallbacks for the unimplemented Alignment properties.
What does Partial Implementation actually mean ?
As anybody can imagine, implementing a fancy web feature takes a considerable amount of time. During this period, the feature passes through several phases with different exposure to the end users. It\’s precisely due to the importance of end user\’s feedback that these new web features are shipped under experimental flags. This workflow is specially useful no only for browser devs but for the spec editors as well.
For this reason, the W3C CSS Working Group defines a general policy to manage Partial Implementations, which can be summarized as follows:
So that authors can exploit the forward-compatible parsing rules to assign fallback values, CSS renderers must treat as invalid (and ignore as appropriate) any at-rules, properties, property values, keywords, and other syntactic constructs for which they have no usable level of support. In particular, user agents must not selectively ignore unsupported property values and honor supported values in a single multi-value property declaration: if any value is considered invalid (as unsupported values must be), CSS requires that the entire declaration be ignored.
This policy is added to every spec as part of its Conformance appendix, so it is in the case of the CSS Box Alignment specification document. However, the interpretation of the Partial Implementation policy is far from trivial, specially for a feature like CSS Box Alignment. The most restrictive interpretation would imply the following facts:
Any new CSS property of the new spec should be declared invalid until is supported by all the layout models it applies to.
Any of the already existent CSS properties with new values defined in the new spec should be declared invalid until all these new values are implemented in all the layout models such property applies to.
Browsers shouldn\’t ship (without experimental flags) any CSS property or value until it\’s implemented in all the layout model it applies to.
When we discussed about this at Igalia we applied a less restrictive interpretation, based on the assumption that the spec actually defined several features which could be implemented and shipped independently, obviously avoiding any browsers interoperability issues. As it\’s been always in the nature of the specification, keeping backward compatibility with Flexbox implementations has been a must, since its spec already defines some of the CSS properties now present in the new spec.
The issue filed by Florian was discussed during the Tokyo F2F Apr 19-21 2017 meeting, where it was agreed to add a new section in the CSS Box Alignment spec to clarify how implementors of this feature should manage Partial Implementations:
Since it is expected that support for the features in this module will be deployed in stages corresponding to the various layout models affected, it is hereby clarified that the rules for partial implementations that require treating as invalid any unsupported feature apply to any alignment keyword which is not supported across all layout modules to which it applies for layout models in which the implementation supports the property in general.
The new text added makes the Partial Implementation policy less restrictive and, even it contradicts our interpretation of independent alignment features per layout model, it affects only to models which already implement any of the CSS properties defined in the new spec. In this case, only Flexbox has to be updated to implement the new values defined for its alignment related CSS properties: align-content, justify-content and align-self.
Analysis of the implementation and shipment status
Before thinking on how to address the Partial Implementation issues, I decided to analyze what\’s the status of the CSS Box Alignment feature in the different browsers. If you are interested in the full analysis, it\’s available here. The following table shows the implementation status of the new spec in the Safary, Chrome and Firefox browsers, using a color code like unimplemented, only grid or both (flex and grid):
If you can try out some examples of these Partial Implementation issues, just try flexbox vs grid cases with some of these alignment values: align-items: center, align-self: left; align-content: start or justify-content: end.
The 3 major browsers analyzed have shipped most, if not all, the CSS Box Alignment spec implemented for CSS Grid Layout (since Chrome 57, Safari 10.1, Firefox 52). Firefox is the browser which implemented and shipped a wider support for CSS Flexible Box.
We can extract the following conclusions:
The 3 browsers analyzed have shipped Partial Implementations of the CSS Box Alignment specification, although Firefox is almost complete.
The 3 browsers have shipped a Grid feature that supports completely the new CSS Box Alignment spec, although Safari still misses the self-baseline values.
The 3 implementations of the new CSS Box Alignment specification are backward compatible with the CSS Flexible Box specification, even though it implements for some properties a lower level of the spec (e.g. self-baseline keywords)
Work in progress
Although we are still evaluating the problem together with the Blink and WebKit communities, at Igalia we are already working on improving the situation. We all agree on the damage to the Web Platform that these Partial Implementation issues are causing, as Florian pointed out initially, so that\’s a good starting point. There are bug reports on both WebKit and Blink and we are already providing patches for some of them.
We are still discussing about the best approach, but our bet would be to request an intent-to-implement-and-ship for a CSS Box Alignment (for flexbox layout) feature. This approach fits naturally in our initial plans of implementing several independent features from the alignment specification. It seems that it\’s what Firefox is doing, which already announced the implementation of CSS Box Alignment (for block layout)
Thanks to Bloomberg for sponsoring this work, as part of the efforts that Igalia has been doing all these years pursuing a better and more open web.
I’ve been working for a while already on the implementation of the CSS Grid Layout standard for the WebKit and Blink web engines. It’s a complex specification, indeed, like most of them, so I enjoyed a lot decrypting all the angles behind the language used to define the different CSS properties, their usage and limits, exceptions and so on. It’s fair to start thanking the WebKit reviewers and Blink owners for their patient and support reviewing patches. It also worth mentioning that the E.D is still a live document with frequent changes and active discussions in the www-style mailing list, which is very active and supportive solving doubts and attending suggestions of the hackers working on the implementation.
Before continue reading, I’d strongly recommend reading the previous posts of my colleges Manuel and Sergio to understand the basic concepts of the CSS Grid Layout and its main features and advantages for the web.
I had the chance to land several patches in WebKit and Blink that improved the current implementation of the standard, both fixing bugs and adapting it to the latest syntax changes introduced in the spec, but perhaps the most noticeable improvements are, so far, the new grid-template and grid shorthands added recently.
The “grid-template” shorthand
Quoting the CSS Grid Layout specs:
The grid-template property is a shorthand for setting grid-template-columns, grid-template-rows, and grid-template-areas in a single declaration. It has several distinct syntax forms:
It’s always easier if we have some examples at hand:
grid-template: auto 1fr auto / auto 1fr;
grid-template: 10px /"a" 15px;
grid-template: 10px /(head1)"a" 15px (tail1)(head2)"b" 20px (tail2);
grid-template:(first) 10px repeat(2,(nav nav2) 15px)/"a b c" 100px (nav)(nav2)"d e f" 25px (nav)(nav2)"g h i" 25px (last);
grid-template: auto 1fr auto / auto 1fr;
grid-template: 10px / "a" 15px;
grid-template: 10px / (head1) "a" 15px (tail1)
(head2) "b" 20px (tail2);
grid-template: (first) 10px repeat(2, (nav nav2) 15px) / "a b c" 100px (nav)
(nav2) "d e f" 25px (nav)
(nav2) "g h i" 25px (last);
It’s important to notice that the subgrid functionality is under discussion to be postponed for the level 2 of the specification, hence it was not implemented, for the time being, in the shorthand either. This decision had the support of IE and Chromium browsers; Mozilla partially agree on this, even though with some doubts.
There was something special in the implementation of this shorthand property. Usually, the CSS property parsing methods are implemented straight forward, avoiding unnecessary or duplicated operations over the parsed value list. However, due to the ambiguity of the shorthand syntax, it’s not clear which form the expression belongs to until reaching the <string> clause. In order to reuse the <grid-template-{row, column}> parsing function, it was necessary to allow rewinding the parsedValue list in case of detecting the wrong form was being processed.
Another remarkable implementation detail was the change in the gridLineName parsing function, required to join the adjoining line names of the last and first columns (nav and nav2 in the example). See below the longhand equivalence of the last case in the previous example:
grid-template-columns:(first) 10px repeat(2,(nav nav2) 15px);
grid-template-rows: 100px (av nav2) 25px (nav nav2) auto (last):
grid-template-areas:"a b c""d e f""g h i";
grid-template-columns: (first) 10px repeat(2, (nav nav2) 15px);
grid-template-rows: 100px (av nav2) 25px (nav nav2) auto (last):
grid-template-areas: "a b c"
"d e f"
"g h i";
The “grid” shorthand
Quoting the CSS Grid Layout specs:
The grid property is a shorthand that sets all of the explicit grid properties (grid-template-rows, grid-template-columns, and grid-template-areas) as well as all the implicit grid properties (grid-auto-rows, grid-auto-columns, and grid-auto-flow) in a single declaration.
Even that the shorthand sets both implicit and explicit grid properties, it can be only specified either implicit or explicit grid properties; the missing properties will be set to the initial values. Now let’s see some examples:
The “grid” shorthand is the recommended mechanism even to define just the the explicit shorthand, unless web authors are interested on cascade separately the impicit grid properties.
Current status and next steps
Both properties landed Blink trunk rencetly (revisions 170552 and 171143) and and they are waiting for the final review in WebKit, hopefully they will land soon. There are enough layout tests to cover the most common cases but perhaps some additional cases might be added in the future. As it was mentioned, there are certain ambiguities in both shorthands syntax and it’s also important to check out the www-style mailing list looking for changes that might require modifying the implementation, hence adding the proper test cases.
With the implemmentation of these two new shorthands, the properties implementation tasks are almost completed. We are working gonw on fixing bugs and implementing the alignment features. There is a quite important gap between the Blink and WebKit implementation, but we are working on porting patches as soon as possible, since we think it’s important to have both implementations synced.
I’ll attend the WebKit Contributors Meeting next week, so perhaps I could speed up the landing the patches for the shorthand properties. My main goal, though, will be to gather feedback from the WebKit community about the status of the CSS Grid Layout implementation, what features they miss the most, which bugs should have more priority and share with them our future plans at Igalia.
All this work was possbile thanks to the collaboration between Igalia and Bloomberg, We both are working hard to help and promote the wide adpoption of this standar, which will be shipped soon on IE and hopefully also in Chromimum. We are also following the efforts Mozila is doing, which give us the impresion that the interest of most of the browsers on this standar is quite high.
I would like to introduce in this post the main problems we have detected in the Selection implementation of two of the most important web engines, such as Blink and WebKit. I’ve already described some of these issues, particularly for CSSRegions, but I’ll go a bit further now analyzing them and also introducing one of the proposal we have been working on at Igalia s part of the collaboration we have with Adobe.
Selection is a DOM Tree matter
At Igalia, we have been investigating how to adapt the selection to the new layout models which provide more complex ways of visualizing the content defined in the DOM Tree. Let’s consider the following basic example using CSSRegions layout:
Figure 1: base case
In the last post about this issue we have identified 4 main problems with selection in CSSRegions:
Selection direction
Highlighting and content mismatch
Incorrect block gaps filling
Clear the selection
I’ll describe some examples where these issues are present, where are the root causes and how they can be solved or, at least, improved. I’ll try as well to explain how the Selection works, starting from the mouse events the end user generates to perform a new selection, how those are mapped into a DOM Tree range and finally, how the rendering process produces the highlighting of the selected elements.
Figure 2: Highlighting and selected content mismatch
I’ll use this first example (Figure 2) to briefly describe how the Selection is implemented and how all the involved components interact to generate both, the selected DOM Range and the corresponding highlighting by the RenderTree. Obviously the end user selects contents from the Visualized elements, in this case the content of two regular blocks (no regions involved). The mouse events are translated to VisiblePosition instances (Start and End) in the DOM Tree using the positionForPoint method. Such VisiblePositions are then mapped into the corresponding RenderObjects in the Render Tree; these objects are the ones used to traverse the tree in the RenderView::setSelection method and mark the appropriated elements with one of the following flags: SelectionNone, SelectionStart, SelectionInside, SelectionEnd, SelectionBoth. These flags are also very important in the block gaps filling algorithm, implemented basically in the RenderBlock::selectionGaps method.
The algorithm implemented in the RenderVieww::setSelection method can be described, very simplified, as the following steps:
gathering information (RenderSelectionInfo and RenderblockSelectionInfo) of the old selection.
clearing the old selection (basically mark all the elements as SelectionNone)
updating the flags of the elements of the new selection.
gathering information of the new selection.
repainting old objects which might have changed.
painting the new selected objects.
repainting the old blocks which might have changed.
painting the new selected blocks.
The algorithm traverses the RenderTree, from the Start to the End using the RenderObject::nextInPreOrder function. Here is where the clear operation issues can appear. If not all objects can be reached by the pre-order traversal, the clear operation does not work properly. That’s why we introduced a way to traverse back the Tree (r155058) looking for elements which can be unreachable. One of the causes of this issue is the selection direction change.
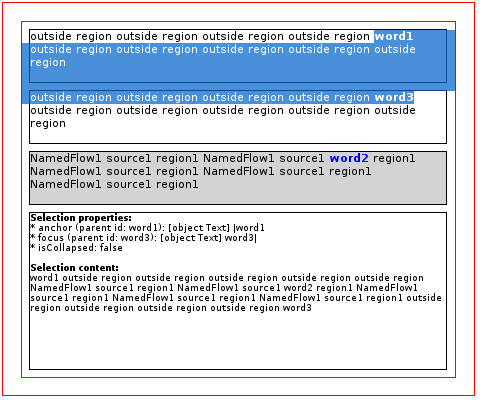
This first example shows the highlighting and content mismatch issue, since the DOM Range considers the source (flow-into) element, while is not highlighted by the RenderTree.
The next example considers now selection from both regions and regular blocks and introduces also an interesting Selection topic: selection direction.
Figure 3: Incorrect block gaps filling
As you can see in the diagram Figure 3, the user selected content upwards. In most of the cases the selection direction is not used at all, so Start must be always above the End VisiblePosition in the DOM Tree. The VisibleSelection ensures that, but in this case, because of how the Source (flow-into) is defined according to the CSSRegions specification and where it was placed in the HTML code, the original Start and End position are not flipped. We will talk more about this in the next example. However, the RenderObject associated to a DOM element with a flow-into property is located in the in the render tree under the RenderFlowThread object, which itself is placed at the end of normal render tree, thus causing the start render object to be below the end render object. This fact causes the highlighted content to be exactly the opposite to what the user actually selected.
This example illustrates also the issue of incorrect block gaps filling, since the element with the id content-1 is considered a block gap to be filled. This happens because of the changes introduced in the already mentioned revision r155058 since the element with id content-2 and the body are flagged as SelectionEnd, the intermediate elements are considered as block gaps to be filled.
At this point is quite clear that the way the Render Tree is traversed is very important to produce a coherent selection rendering; notice that in this case, highlight and selected content match perfectly. The idea of using the Region DIV as container of the Source DIV content portion, which is rendered inside such region, looks like a promising approach. The next example will go further into this idea.
Figure 4: Selection direction
In this example (Figure 4) the Start and End VisiblePosition instance have to be flipped by the generated VisibleSelection, since the DIV with the id content-1 is above the original Start element defined by the end user. By flipping both positions it makes the corresponding Start and End RenderObject instances to be consistent, that’s why there is no selection direction issue in this case. However, because of the position of the End element as child of the RenderFlowThread, the RenderElement with the id content-2 is selected, which, while being seamless from the user experience point of view, it does not match the selected content retrieved from the DOM Range.
The solution: Regions as containers
At this point is clear that the selection direction issues are one of the most important source of problems for the Selection with CSSRegions. The current algprithms, RenderView::setselection and RenderBlock::selectionGaps, require to traverse the RenderTree downwards from start to end. In fact, this is specially important for the block gaps filling algorithm.
It’s important to notice that the divergence of the DOM and Render trees when using CSSRegions comes from how these two concepts, the flow-into DOM element and the RenderFlowThread object, are managed and placed in each trees. Why not just using the region elements for the selection algorithms and considering both flow-into and RFT as “meta-elements” where the selected content is extracted from ?
Considering the steps defined previously for the selection algorithm the regions as containers approach could be described as follows:
Case 1: Start and Stop elements, either both or none, are children of the RenderFlowThread.
The current RenderView::setSelection algorithm works fine.
Case 2: Only Start is child of the RenderFlowThread.
First, determining the RenderElements range [RegionStart, RegionEnd] in the RenderFlowThread associated to the RenderRegion the Start element is rendered by.
Then, applying the current algorithm to the range of elements [Start, RegionEnd]
Finally, applying the current algorithm from the NextInPreOrder element of the RenderRegion until the Stop, as usual.
Case 3: Only Stop is child of the RenderFlowThread.
First, applying the current algorithm from the Start element to the RenderRegion the Stop element is rendered by.
Then, determining the RenderElements range [RegionStart, RegionEnd] in the RenderFlowThread associated to the RenderRegion the Stop element is rendered by.
Finally, applying the current algorithm to the range of elements [RegionStart, Stop]
Determining the selection direction, at VisibleSelection, is also affected by the structure of the RenderTree; even that the editing module in both WebKit and Blink is also using rendering info for certain operations, this is perhaps one of the weakest points of this approach. Let’s use one of the examples defined before to illustrate this situation.
Figure 5: Block gaps filling issues solved
While traversing the RenderTree, once a RenderRegion is reached its corresponding range of RenderObjects is determined in the RenderFlowThread. The entire range will be traversed for the blocks flagged as SelectionInside. For the ones flagged as SelectionStart or SelectionEnd, the steps previously defined are applied.
The key of this new approach is that traversing is always downwards, from the Start to the End, which solves also the block gaps related issues.
Let’s considering now a more complex example (Figure 6), with several regions between a number of regular blocks. selection is more natural with this approach, coherent with what the user expects and also matching the DOM Tree range for most of the cases. This is, however, the biggest drawback of this approach, since it does not follow completely the Editing/Selection specs. I’ll talk more about this in the last lines of this post.
Figure 6: Selection direction issues solved
The following video showcase our proposal on the WebKit MiniBrowser testing application using a real HTML example based on the Figure 6 diagram.
Even though selection is more natural an coherent, as I already mentioned, it does not follow completely the Editing/Selection specs. As I stated at the beginning of this post, selection is a DOM matter, defined by a Range of elements in the DOM Tree. This very simple case (Figure 7) is enough to describe this issue:
Figure 7: Regions as containers NON specs compliant
The regions as containers approach does not considers the Source (flow-into) elements as actual DOM elements, so they will never be part of the selection. This breaks the Editing/Selection specification, since those are regular DOM elements as they are defined in the CSS Region standard. This approach was our first try and perhaps too ambitious, providing a good user experience on selection with CSSRegions and specs compliant at the same time. Even that it was a good experience we can conclude that the problem is too complex and it requires a different strategy.
We had the opportunity to introduce and discuss our proposal during the last WebKitGtk+ Hackfest, where Rego, Mihnea and me had the chance to work hand in hand, carefully analyzing and digesting this proposal. Even that we finally discard it, we were able to design other approaches which some of them are really promising. Rego will introduce some of them shortly in a blog post. Hence, can’t end this post without thanking to Igalia and the GNOME Foundation for sponsoring such a productive and useful hackfest.
Back in early June, Adobe and Igalia announced a collaboration to work on the CSS Regions and CSS Shapes W3C standards. Our first challenge has been to improve the Selection use cases when using complex layout models, like CSS Regions.
The CSS Regions model allows content to flow across multiple areas called Regions. This new approach offers web content designers a way to build richer and more complex layouts, mapping content with specific visual areas of a document. Defining different Flow Threads with multiple Regions, associating them to specific content, and applying different styles to a set of Regions is very powerful in terms of design and user experience. If you are interested, here you can find some examples of what is possible with CSS Regions.
But having this flexibility in web design requires overcoming quite a few technical challenges. The current implementation of CSS Regions in WebKit changes the way the Render Tree is created from the DOM Tree. This poses the challenge of making selection work with regions since selection is DOM based. Given its importance and frequent use, improving the interaction of selection and CSS Regions has been the main goal of our collaboration.
The W3C selection specification, which has not been updated since the last year, does not address the complexities introduced by new layout modules, like CSS Regions, CSS FlexBox and CSS Grid Layout module . We found out very quickly that selection had many issues, with respect to both visual appearance and selected content. We have created a tests suite to evaluate the different use cases of selection with CSS Regions.
Selected content does not match the highlighted area.
Selection direction issues
Let’s start with a very simple description of the concept of Selection Direction, which consist of the following points:
The WebCore::VisibleSelection class has two attributes called base and extent declared as dom::Position instances
Such positions refer respectively to the anchor and focus nodes in the DOM Tree.
Additionally, WebCore::VisibleSelection has two dom:Position attributes, start and end, which are used later during the rendering phase
Once the base and extent fields are set when instantiating a new VisibleSelection class, some adjustments and checks are performed to validate the selection. One of those checks is whether base position is beforeextent in the DOM Tree. Based on the result of this check, the start and end attributes will be set to either base or extent respectively.
In the first test, the selected content includes the entire region block, even when it was not selected by the user. The cause, as we will see in later, derives from the position of the source block in the DOM Tree, which in this case is defined between the two regular blocks.
The second example shows some selection direction related issues; in this case, what the user selected is precisely the content between the two highlighted areas. The problem here is that the base node of the original selection is below the extent node in the DOM Tree, so they are swapped in the selection logic. In addition, the CSS Regions implementation builds the Render Tree in a way that the source content defined by a RenderNamedFlowThread block is positioned below where it was defined in the DOM Tree. The consequence of this is that the start node is below the end node, so the highlighted area starts in the region block and continues from the root element (usually the body) until reaching the end node.
Our first approach was trying to provide a better user experience during selection with CSS Regions. We thought that adding multi-range capabilities to the DOM Selection API was the best way to go and we provided a patch. However, this approach was rejected by some Apple reviewers because multi-range selection introduces many problems, such as those detailed in the selection specification.
We have opened the debate again on the mailing list, though, because we think there might be some advantages to this approach, even without modifying the selection API. For instance, being able to handle independent Ranges and compose the expected selection will provide the flexibility needed to implement complex use cases. But, after some discussion with some of the Adobe Web Platform contributors, we have decided to focus on improving the selection following the current specification. While we feel this approach may lead to a non-optimal user experience for certain use cases, we expect implementing it will help us discover the problems inherent in the current selection specification. We have also been discussing these issues with some reviewers from Apple, Ryosuke Niwa and David Hyatt, and looking for alternatives to the multi-range approach.
We have posted additional patches, one to improve the selection behavior and another to revert the current limitation of selections related to including content from different Flow Threads. We think that this approach provides better integration of CSS Regions with HTML documents. Plus, it will allow us to properly evaluate the performance issues of selection with CSS Regions.
The other challenges we faced during this collaboration include:
changing how the selection rendering traverses the Render Tree in order to deal with the special RenderFlowThread blocks
adjusting the block gaps filling algorithm
clearing the selection
selection direction issues derived from the Render Tree and DOM Tree divergence
We detected a number of other issues, such as how LayoutPoints are positioned in the DOM Tree when pointing to Region blocks, leading to an incorrect Selection extent node. We are confident that we will ultimately have a fully-compliant selection specification implementation for CSS Regions, but the improvements using this approach are limited. Even after solving all the issues we have detected so far, selection might still seem weird and buggy from an end user perspective. Thus we think that the final solution, one which will provide the user with a more consistent experience, will be to complement the selection specification to consider not only the DOM Tree, but also how the Render Tree is built by the Layout Model.
As you probably know, GeoClue is part of the Meego architecture as the Geolocation component. However, current plans are using the QtMobility API for UI applications and defining GeoClue as one of the available backends.
The QtMobility software implements a set of APIs to ease the development of UI software focused on mobile devices. It provides some interesting features and tools for a great variety of mobile oriented development areas:
Contacts
Bearer (Network Management)
Location
Messaging
Multimedia
Sensors
Service Framework
System Information
All those software pieces are a kind of abstraction to expose easy and comprehensive API’s to be used in the UI application developments. In regard to Geolocation, lets describe in detail the Location component.
It was recently announced the first public implementation of a GeoClue based backend for the QtMobility Location API. The starting point to implement the GeoClue backend, as described in the QtMobility documentation, is the QGeoPositionInfoSource abstract class. The implementation of this abstract class using GeoClue seems not too hard, however, the current GeoClue architecture has some limitations to fulfill the QtMobility specifications:
The QtGeoPositionInfo class, defined for storing the Geolocation data retrieved by the selected backend (GeoClue in this case) manages together global location, direction and velocity.
The GeoClue API has separated methods and classes for location, address and velocity. Independent signals are emitted whenever such parameters are changed.
The GeoClue Velocity interface is not implemented in the GeoClue Master provider.
Even though is not too hard to implement the abstract methods of the QGeoPositionInfoSource class, the start/stop updating methods are not very efficient in regard to battery and memory consumption. There is not easy or direct way to remove one provider when is not used.
As part of the Igalia’s plans on Meego, I’ve been working in the implementation of such GeoClue based backend for the Meego QtMobility framework. Now that part of my work has been already done, it’s time to share efforts and contribute to the public repository with some patches and performance reports I’ve got during the last months. Some work is still needed before releasing my work, but I hope I will be able to send something in the following weeks, so stay tunned.
Even though the code is not ready for being public, I could show a snapshots of the test application I implemented for the Meego Handset platform using the Meego Touch framework:
GeoClue test application for Meego Handset
The purpose of this application would be monitoring the DBus communication between the different location providers, creating some performance tests and evaluating the impact on a Mobile platform.
As promised, GeoClue now supports Connman as the connectivity manager module for acquiring network based location data.This step has been essential to complete the integration of GeoClue in the Meego architecture.
Thanks to Bastian Nocera for reviewing and pushing the commit, which is now part of the master branch of GeoCLue. Let see if it passes the appropriated tests before becoming part of some official release.
Network based positioning is one of the advantages of using GeoClue as Location provider. That’s obvious for Desktop implementations, where GPS and Cell Id based methods are not the most common use cases. On the other hand, Mobile environments could also get benefits from network based positioning, assisting the GPS based methods for improving the fix acquiring process; perhaps indicating where the closest satellite network is or showing a less accuracy location while the GPS fix is being established.
Finally, I would like to remark that my work is part of the Igalia’s bet for the Meego platform. I think the GeoClue project will be an important technology to invest in the future, since it’s relevant also for GNOME and Desktop technologies. In fact, GeoClue is also the Ubuntu’ s default Geolocation component.