QEMU 2.5 has just been released, with a lot of new features. As with the previous release, we have also created a video changelog.
I plan to write a few blog posts explaining some of the things I have been working on. In this one I’m going to talk about how to control the size of the qcow2 L2 cache. But first, let’s see why that cache is useful.
The qcow2 file format
qcow2 is the main format for disk images used by QEMU. One of the features of this format is that its size grows on demand, and the disk space is only allocated when it is actually needed by the virtual machine.
A qcow2 file is organized in units of constant size called clusters. The virtual disk seen by the guest is also divided into guest clusters of the same size. QEMU defaults to 64KB clusters, but a different value can be specified when creating a new image:
qemu-img create -f qcow2 -o cluster_size=128K hd.qcow2 4G
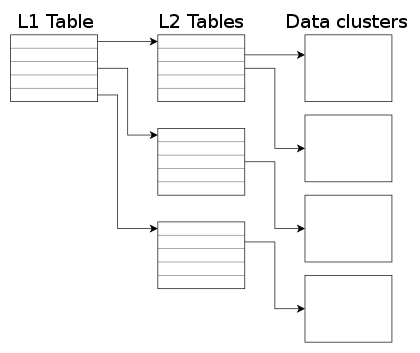
In order to map the virtual disk as seen by the guest to the qcow2 image in the host, the qcow2 image contains a set of tables organized in a two-level structure. These are called the L1 and L2 tables.
There is one single L1 table per disk image. This table is small and is always kept in memory.
There can be many L2 tables, depending on how much space has been allocated in the image. Each table is one cluster in size. In order to read or write data to the virtual disk, QEMU needs to read its corresponding L2 table to find out where that data is located. Since reading the table for each I/O operation can be expensive, QEMU keeps a cache of L2 tables in memory to speed up disk access.
 |
The L2 cache can have a dramatic impact on performance. As an example, here’s the number of I/O operations per second that I get with random read requests in a fully populated 20GB disk image:
| L2 cache size | Average IOPS |
|---|---|
| 1 MB | 5100 |
| 1,5 MB | 7300 |
| 2 MB | 12700 |
| 2,5 MB | 63600 |
If you’re using an older version of QEMU you might have trouble getting the most out of the qcow2 cache because of this bug, so either upgrade to at least QEMU 2.3 or apply this patch.
(in addition to the L2 cache, QEMU also keeps a refcount cache. This is used for cluster allocation and internal snapshots, but I’m not covering it in this post. Please refer to the qcow2 documentation if you want to know more about refcount tables)
Understanding how to choose the right cache size
In order to choose the cache size we need to know how it relates to the amount of allocated space.
The amount of virtual disk that can be mapped by the L2 cache (in bytes) is:
disk_size = l2_cache_size * cluster_size / 8
With the default values for cluster_size (64KB) that is
disk_size = l2_cache_size * 8192
So in order to have a cache that can cover n GB of disk space with the default cluster size we need
l2_cache_size = disk_size_GB * 131072
QEMU has a default L2 cache of 1MB (1048576 bytes)[*] so using the formulas we’ve just seen we have 1048576 / 131072 = 8 GB of virtual disk covered by that cache. This means that if the size of your virtual disk is larger than 8 GB you can speed up disk access by increasing the size of the L2 cache. Otherwise you’ll be fine with the defaults.
How to configure the cache size
Cache sizes can be configured using the -drive option in the command-line, or the ‘blockdev-add‘ QMP command.
There are three options available, and all of them take bytes:
- l2-cache-size: maximum size of the L2 table cache
- refcount-cache-size: maximum size of the refcount block cache
- cache-size: maximum size of both caches combined
There are two things that need to be taken into account:
- Both the L2 and refcount block caches must have a size that is a multiple of the cluster size.
- If you only set one of the options above, QEMU will automatically adjust the others so that the L2 cache is 4 times bigger than the refcount cache.
This means that these three options are equivalent:
-drive file=hd.qcow2,l2-cache-size=2097152
-drive file=hd.qcow2,refcount-cache-size=524288
-drive file=hd.qcow2,cache-size=2621440
Although I’m not covering the refcount cache here, it’s worth noting that it’s used much less often than the L2 cache, so it’s perfectly reasonable to keep it small:
-drive file=hd.qcow2,l2-cache-size=4194304,refcount-cache-size=262144
Reducing the memory usage
The problem with a large cache size is that it obviously needs more memory. QEMU has a separate L2 cache for each qcow2 file, so if you’re using many big images you might need a considerable amount of memory if you want to have a reasonably sized cache for each one. The problem gets worse if you add backing files and snapshots to the mix.
Consider this scenario:
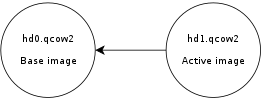 |
Here, hd0 is a fully populated disk image, and hd1 a freshly created image as a result of a snapshot operation. Reading data from this virtual disk will fill up the L2 cache of hd0, because that’s where the actual data is read from. However hd0 itself is read-only, and if you write data to the virtual disk it will go to the active image, hd1, filling up its L2 cache as a result. At some point you’ll have in memory cache entries from hd0 that you won’t need anymore because all the data from those clusters is now retrieved from hd1.
Let’s now create a new live snapshot:
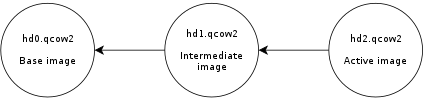 |
Now we have the same problem again. If we write data to the virtual disk it will go to hd2 and its L2 cache will start to fill up. At some point a significant amount of the data from the virtual disk will be in hd2, however the L2 caches of hd0 and hd1 will be full as a result of the previous operations, even if they’re no longer needed.
Imagine now a scenario with several virtual disks and a long chain of qcow2 images for each one of them. See the problem?
I wanted to improve this a bit so I was working on a new setting that allows the user to reduce the memory usage by cleaning unused cache entries when they are not being used.
This new setting is available in QEMU 2.5, and is called ‘cache-clean-interval‘. It defines an interval (in seconds) after which all cache entries that haven’t been accessed are removed from memory.
This example removes all unused cache entries every 15 minutes:
-drive file=hd.qcow2,cache-clean-interval=900
If unset, the default value for this parameter is 0 and it disables this feature.
Further information
In this post I only intended to give a brief summary of the qcow2 L2 cache and how to tune it in order to increase the I/O performance, but it is by no means an exhaustive description of the disk format.
If you want to know more about the qcow2 format here’s a few links:
- The qcow2 file specification, from the QEMU repository.
- qcow2 L2/refcount cache configuration, the original text this post is based on. It also covers the refcount block cache.
- The reinvention of qcow2, a presentation (slides and video) by Kevin Wolf at KVM Forum 2011.
- qcow2 – why (not)?, a presentation (slides and video) by Max Reitz and Kevin Wolf at KVM Forum 2015.
Acknowledgments
My work in QEMU is sponsored by Outscale and has been made possible by Igalia and the invaluable help of the QEMU development team.
 |
Enjoy QEMU 2.5!
[*] Updated 10 March 2021: since QEMU 3.1 the default L2 cache size has been increased from 1MB to 32MB.
Hi,
interesting post. I have a virtual machine using qemu/kvm under Debian unstable (with qemu 2.5) which has a 40G disk, and I have lots of memory. Thus I thought to increase the L2 cache to 5M.
I struggled with your instructions (and I guess I still do). After showing to use `qemu-img` for creating, the other commands simply give the `–drive` option w/o mentioning the command. I tried to set using `qemu-img amend`, but that did not work.
I finally found that `qemu-system-x86_64` accepts the `–drive` option. However, this starts the image instead of simply modifying the cache size. On top of this, I normally use `virt-manager` as my interface, and that does not seem to allow specifying this option.
So I guess I’m still confused:
– what is the correct command to manipulate the L2 cache size?
– will that L2 cache change be persistent or do I have to provide this option every time I start the image?
– is
Hi Norbert,
here’s how you do it:
qemu-system-x86_64 -drive file=hd.qcow2,l2-cache-size=5M
(note that -drive takes only one dash, it’s not –drive)
The cache is not persistent, you have to specify its size every time you open a new disk image.
Thanks. So I guess I have to migrate away from virt-manager, or see if I can hack it to allow this configuration in virt-manager
I guess you can use this:
http://blog.vmsplice.net/2011/04/how-to-pass-qemu-command-line-options.html
Pingback: Links 18/12/2015: Linux in Blockchain and Red Hat’s Good Results | Techrights
Hi, I read an article of qemu io-throttling from your blog. Could you please enlighten me about how to achieve the proportional IO sharing by using cgroup, instead of qemu?
My qemu config is like: -drive file=$DISKFILe,if=none,format=qcow2,cache=none,aio=native
Test command inside vm is like: dd if=/dev/vdc of=/dev/null iflag=direct
Cgroup of the qemu process is properly configured as well.
But no matter how change the proportion, such as vm1->400 and vm2->100, I can only get the equal IO speed.
Wondering cgroup blkio.weight or blkio.weight_device has no effect for qemu???
Bob: do you maybe need to change the I/O scheduler?
https://unix.stackexchange.com/questions/69300/cgroups-blkio-weight-doesnt-seem-to-have-the-expected-effect
The IO scheduler is cfg indeed.
Pingback: QEMU and the qcow2 metadata checks | The world won't listen
Haven’t been able to find a way to set the cache using libvirt XML…is it possible?
Or do I have to specify the whole storage device in an element, if that’s even possible?
I havent found a way to do this in the newer versions of QEMU like 4.x either. How can we do this?
Hello, I’m not sure how to do it with libvirt, but note that the default L2 cache size is now 32MB (since QEMU 3.1).
See also this libvirt bug: https://bugzilla.redhat.com/show_bug.cgi?id=1377735
Pingback: Subcluster allocation for qcow2 images | The world won't listen
bro you have a error in your formula.. due math principies..
disk_size = l2_cache_size * (cluster_size / 8) to be clear and work all your investigations
i noted that for others that does not are english native speakers this article is not so usefully due that!