Last year I worked on implementing in Turnip the support for a HW feature present in Qualcomm Adreno GPUs: the low-resolution Z buffer (aka LRZ). This is a HW feature already supported in Freedreno, which is the open-source OpenGL driver for these GPUs.
What is low-resolution Z buffer
Low-resolution Z buffer is very similar to a depth prepass that helps the HW avoid executing the fragment shader on those fragments that will be subsequently discarded by the depth test afterwards (Hidden surface removal). This feature comes with some limitations though, such as the fragment shader not being allowed to have side effects (writing to SSBOs, atomic operations, etc) among others.
The interesting part of this feature is that it allows the applications to submit the vertices in any order (saving CPU time that was otherwise used on ordering them) and the HW will process them in the binning pass as explained below, detecting which ones are occluded and giving an increase in performance in some specific use cases due to this.

To understand better how LRZ works, we need to talk a bit about tiled-based rendering. This is a way of rendering based on subdividing the framebuffer in tiles and rendering each tile separately. The advantage of this design is that the amount of memory and bandwidth is reduced compared to immediate mode rendering systems that draw the entire frame at once. Tile-based rendering is very popular on embedded GPUs, including Qualcomm Adreno.
Entering into more details, the graphics pipeline is divided into three different passes executed per tile of the frame.
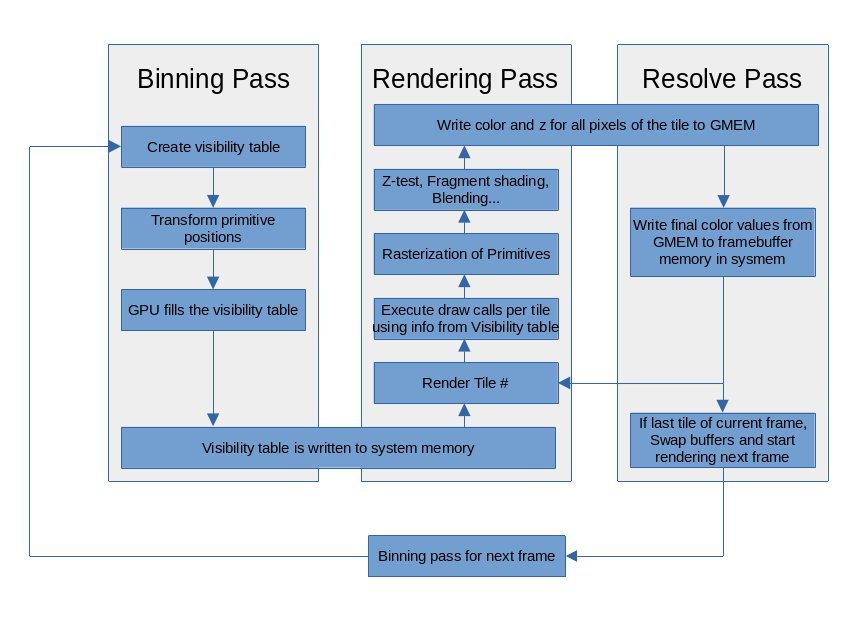 |
|---|
| Tiled-rendering architecture diagram. |
-
The binning pass. This pass processes the geometry of the scene and records in a table on which tiles a primitive will be rendered. By doing this, the HW only needs to render the primitives that affect a specific tile when is processed.
-
The rendering pass. This pass gets the rasterized primitives and executes all the fragment related processes of the pipeline (fragment shader execution, depth pass, stencil pass, blending, etc). Once it finishes, the resolve pass starts.
-
The resolve pass. It first resolves the tile buffer (GMEM) if it is multisample, and copy the final color and depth values for all tile pixels back to system memory. If it is the last tile of the framebuffer, it swap buffers and start the binning pass for next frame.
Where is LRZ used then? Well, in both binning and rendering passes. In the binning pass, it is possible to store the depth value of each vertex of the geometries of the scene in a buffer as the HW has that data available. That is the depth buffer used internally for LRZ. It has lower resolution as too much detail is not needed, which helps to save bandwidth while transferring its contents to system memory.
Thanks to LRZ, the rendering pass is only executed on the fragments that are going to be visible at the end. However, there are some limitations as mentioned before: if a fragment shader has collateral effects, such as writing SSBO, atomics, etc; or if blending is enabled, or if the fragment shader could modify the fragment’s depth… then LRZ cannot be used as the results may be wrong.
However, LRZ brings a couple of things on the table that makes it interesting. One is that applications don’t need to reorder their primitives before submission to be more efficient, that is done by the HW with LRZ automatically. Another one is performance improvements in some use cases. For example, imagine a fragment shader discards parts of fragments but it doesn’t have any other collateral effect otherwise. In that case, although we cannot do early depth testing, we can do early LRZ as we know that some fragments won’t pass a depth test even if they are not discarded by the fragment shader.
Turnip implementation
Talking about the LRZ implementation, I took Freedreno’s code as a starting point to implement LRZ on Turnip. After some months of work, it finally landed in Mesa master.
Last week, more patches related to LRZ landed in Mesa master: the ones fixing LRZ interactions with VK_EXT_extended_dynamic_state, as with this extension the application can change some states in command buffer time that could affect LRZ state and, therefore, we need to track them accordingly.
I also implemented some LRZ improvements that are currently under review also landed (thanks Eric Anholt!), such as the support to do early-LRZ-late-depth test that I mentioned before, which could bring a performance improvement in some applications.
 |
|---|
| Left: original vulkan tutorial demo implementation. Right: same demo modified to discard fragments with red component lower than 0.5f. |
For instance, I did some measurements in a vulkan-tutorial.com implementation of my own that I modified to discard a significant amount of fragments (see previous figure). This is one of the cases that early-LRZ-late-depth test helps to improve performance.
When running the modified demo with these patches, I found a performance improvement between 13-16%.
Acknowledgments
All this LRZ work was my first big contribution to this open-source reverse engineered driver! I don’t want to finish this post without thanking publicly Rob Clark for the original Freedreno implementation and his reviews of my work, as well as Jonathan Marek and Connor Abbott for their insightful reviews, advice and tips to make it working. Edited: Many thanks to Eric Anholt for his reviews in the last two patch series!
Happy hacking!