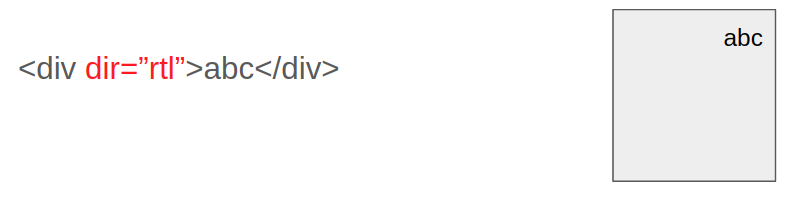Following up on my previous post, I would like to share an update on the progress of the Extension migration work that has been underway over the past few months.
To briefly recap the motivation behind this effort: Igalia’s long-term goal is to enable embedders to use the Extension system without depending on the //chrome layer. In other words, we want to make it possible to support Extension functionality with minimal implementation effort using only //content + //extensions.
Currently, some parts of the Extension system still rely on the //chrome layer. Our objective is to remove those dependencies so that embedders can integrate Extension capabilities without needing to include the entire //chrome layer.
As a short-term milestone, we focused on migrating the Extension installation implementation from //chrome to //extensions. This phase of the work has now been completed, which is why I’m sharing this progress update.
Extension Installation Formats
Chromium supports several formats for installing Extensions. The most common ones are zip, unpacked and crx.
Each format serves a different purpose:
zip – commonly used for internal distribution or packaged deployment
unpacked – primarily used during development and debugging
crx – the standard packaged format used by the Chrome Web Store
During this migration effort, the code responsible for supporting all three installation formats has been successfully moved to the //extensions layer.
As a result, the Extension installation pipeline is now significantly less dependent on the //chrome layer, bringing us closer to enabling Extension support directly on top of //content + //extensions.
Patch and References
To support this migration, several patches were introduced to move installation-related components into the //extensions layer and decouple them from //chrome.
For readers who are interested in the implementation details, you can find the related changes and discussions here:
These links provide more insight into the design decisions, code changes, and ongoing discussions around the migration.
Demo
Below is a short demo showing the current setup in action.
This demo was recorded using app_shell on Linux, the minimal stripped-down browser container designed to run Chrome Apps and using only //content and //extensions/ layers.
To have this executable launcher, we also extended app_shellwith the minimal functionality required for embedders to install the extension app.
This allows Extensions to be installed and executed without relying on the full Chrome browser implementation, making it easier to experiment with and validate the migration work.
Next Steps
The next short-term goal is to migrate the code required for installing Extensions via the Chrome Web Store into the //extensions layer as well.
At the moment, parts of the Web Store installation flow still depend on the //chrome layer. The next phase of this project will focus on removing those dependencies so that Web Store-based installation can also function within the //extensions layer.
Once this work is completed, embedders will be able to install Extension apps from Chrome WebStore with a significantly simpler architecture (//content + //extensions).
This will make the Extension platform more modular, reusable, and easier to integrate into custom Chromium-based products.
I will continue to share updates as the migration progresses.
A History of Extensions for Embedders — and Where We’re Heading
Chromium’s Extensions platform has long been a foundational part of the desktop browsing experience. Major Chromium-based browsers—such as Chrome and Microsoft Edge—ship with full support for the Chrome Extensions ecosystem, and user expectations around extension availability and compatibility continue to grow.
In contrast, some Chromium embedders— for instance, products built directly on the //content API without the full //chrome stack—do not naturally have access to Extensions. Similarly, the traditional Chrome for Android app does not support Extensions. While some embedders have attempted to enable limited Extensions functionality by pulling in selected pieces of the //chrome layer, this approach is heavyweight, difficult to maintain, and fundamentally incapable of delivering full feature parity.
At Igalia we have been willing to help on the long term-goal of making Extensions usable on lightweight, //content-based products, without requiring embedders to depend on //chrome. This post outlines the background of that effort, the phases of work so far, the architectural challenges involved, and where the project is headed.
Note: ChromeOS supporting extensions (ChromeOS has announced plans to incorporate more of the Android build stack) is not the same thing as Chrome-Android App supporting extensions. The two codepaths and platform constraints differ significantly. While the traditional Chrome app on Android phones and tablets still does not officially support extensions, recent beta builds of desktop-class Chrome on Android have begun to close this gap by enabling native extension installation and execution.
The following diagram illustrates the architectural evolution of Extensions support for Chromium embedders.
Traditional Chromium Browser Stack
At the top of the stack, Chromium-based browsers such as Chrome and Edge rely on the full //chrome layer. Historically, the Extensions platform has lived deeply inside this layer, tightly coupled with Chrome-specific concepts such as Profile, browser windows, UI surfaces, and Chrome services.
This architecture works well for full browsers, but it is problematic for embedders. Products built directly on //content cannot reuse Extensions without pulling in a large portion of //chrome, leading to high integration and maintenance costs.
Phase 1 — Extensions on Android (Downstream Work)
In 2023, a downstream project at Igalia required extension support on a Chromium-based Android application. The scope was limited—we only needed to support a small number of specific extensions—so we implemented:
basic installation logic,
manifest handling,
extension launch/execution flows, and
a minimal subset of Extensions APIs that those extensions depended on.
This work demonstrated that Extensions can function in an Android environment. However, it also highlighted a major problem: modifying the Android //chrome codepath is expensive. Rebasing costs are high, upstream alignment is difficult, and the resulting solution is tightly coupled to Chrome-specific abstractions. The approach was viable only because the downstream requirements were narrow and controlled.
Following Phase 1, we began asking a broader question:
Can we provide a reusable, upstream-friendly Extensions implementation that works for embedders without pulling in the //chrome layer?
Motivation
Many embedders aim to remain as lightweight as possible. Requiring //chrome introduces unnecessary complexity, long build times, and ongoing maintenance costs. Our hypothesis was that large portions of the Extensions stack could be decoupled from Chrome and reused directly by content-based products.
One early idea was to componentize the Extensions code by migrating substantial parts of //chrome/*/extensions into //components/extensions.
We tested this idea through Wolvic , a VR browser used in several commercial solutions. Wolvic has two implementations:
a Gecko-based version, and
a Chromium-based version built directly on the //content API.
Originally, Extensions were already supported in Wolvic-Gecko, but not in Wolvic-Chromium. To close that gap, we migrated core pieces of the Extensions machinery into //components/extensions and enabled extension loading and execution in a content-only environment.
By early 2025, this work successfully demonstrated that Extensions could run without the //chrome layer.
However, this work lived entirely in the Wolvic repository, which is a fork of Chromium. While open source, this meant that other embedders could not easily benefit without additional rebasing and integration work.
This raised an important question:
Why not do this work directly in the Chromium upstream so that all embedders can benefit?
Phase 3 — Extensions for Embedders (//content + //extensions)
Following discussions with the Extensions owner (rdevlin.cronin@chromium.org), we refined the approach further.
Rather than migrating functionality into //components, the preferred long-term direction is to move Extensions logic directly into the //extensions layer wherever possible.
Chrome Web Store compatibility Embedders should be able to install and run extensions directly from the Chrome Web Store.
Short-term Goal: Installation Support
Our immediate milestone is to make installation work entirely using //content + //extensions.
Current progress:
✅ .zip installation support already lives in //extensions
🚧 Migrating Unpacked directory installation from //chrome to //extensions (including replacing Profile with BrowserContext abstractions)
🔜 Moving .crx installation code from //chrome → //extensions
As part of this effort, we are introducing clean, well-defined interfaces for install prompts and permission confirmations:
Chrome will continue to provide its full-featured UI
Embedders can implement minimal, custom UI as needed
What Comes Next:
Once installation is fully supported, we will move on to:
Chrome Web Store integration flows
Core WebExtensions APIs required by commonly used extensions
Main Engineering Challenge — Detaching from the Chrome Layer
The hardest part of this migration is not moving files—it is breaking long-standing dependencies on the //chrome layer.
The Extensions codebase is large and historically coupled to Chrome-only concepts such as:
Profile
Browser
Chrome-specific WebContents delegates
Chrome UI surfaces
Chrome services (sync, signin, prefs)
Each migration requires careful refactoring, layering reviews, and close collaboration with component owners. While the process is slow, it has already resulted in meaningful architectural improvements.
What’s Next?
In the next post, We’ll demonstrate:
A functioning version of Extensions running on top of //content + //extensions only — capable of installing and running extensions app.
from Igalia side, we continue working on ways to make easier integrating Chromium on other platforms, etc. This will mark the first end-to-end, //chrome-free execution path for extensions in content-based browsers.
MPArch stands for Multiple Pages Architecture, and the Chromium teams at Igalia and Google are working together on an MPArch project that unites the implementation of several features (back/forward-cache, pre-rendering, guest views, and ports) that support multiple pages in the same tab but are implemented with different architecture models into a single architecture.
I recommend you read the recently posted blog by Que first if you are not familiar with MPArch. It will help you understand the detailed history and structure of MPArch.
This post assumes that the reader is familiar with the //content API and describes the ongoing task of removing reference FrameTreeNode from RenderFrameHost on the MPArch project.
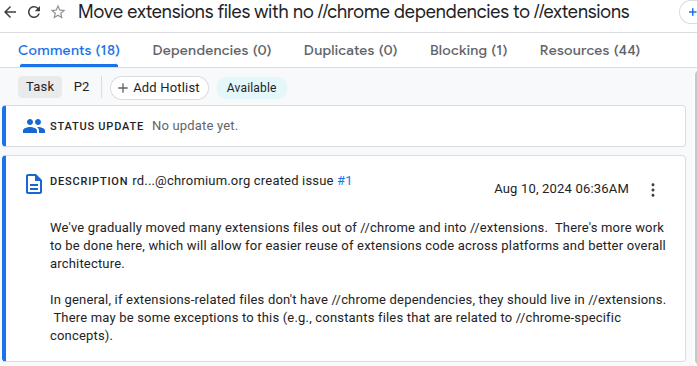
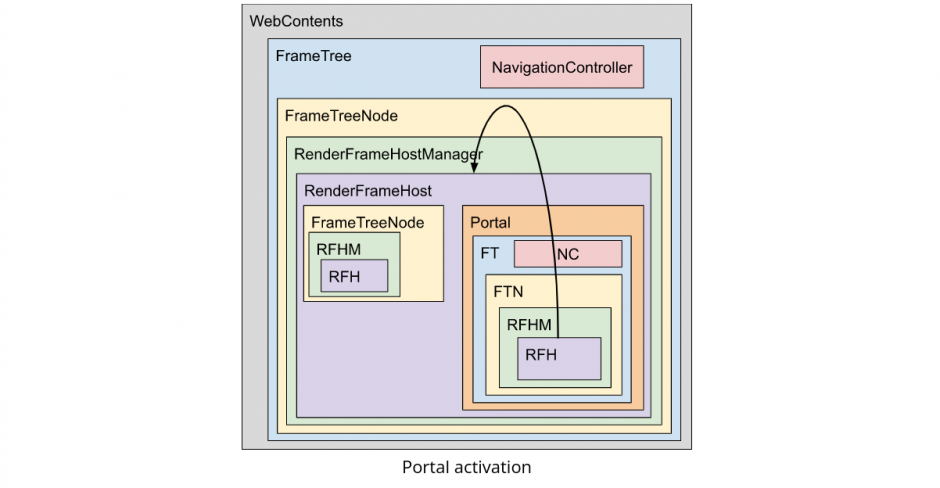
Relationship between FrameTreeNode and RenderFrameHost in MPArch
The main frame and iframe are mirrored as FrameTreeNode and the document of each frame is mirrored as RenderFrameHost. Each FrameTreeNode has a current RenderFrameHost, which can change over time as the frame is navigated.
Let’s look at the relationship between FrameTreeNode and RenderFrameHost of features using the MPArch structure.
BFCache BFCache (back/forward cache) is a feature to cache pages in-memory (preserving javascript state and the DOM state) when the user navigates away from them.
When the document of the new page is navigated, the existing document, RenderFrameHost, is saved in BFCache, and when the back/forward action occurs, RenderFrameHost is restored from BFCache. The FrameTreeNode is kept when RenderFrameHost is saved/restored.
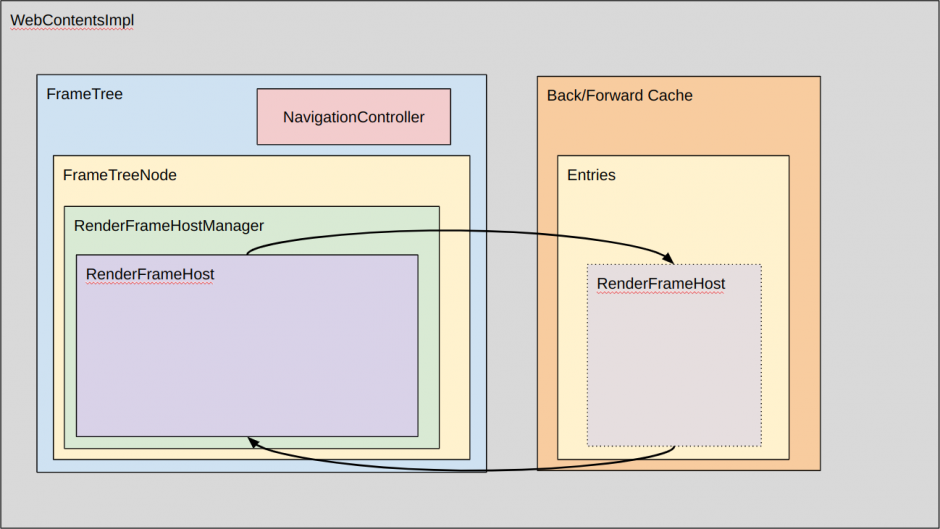
Prerendering Prerender2 is a feature to pre-render the next page for faster navigation. In prerender, a document will be invisible to the user and isn’t allowed to show any UI changes, but the page is allowed to load and run in the background.
When the prerendered page is activated, the current RenderFrameHost that FrameTreeNode had is replaced with RenderFrameHost in Prerender.
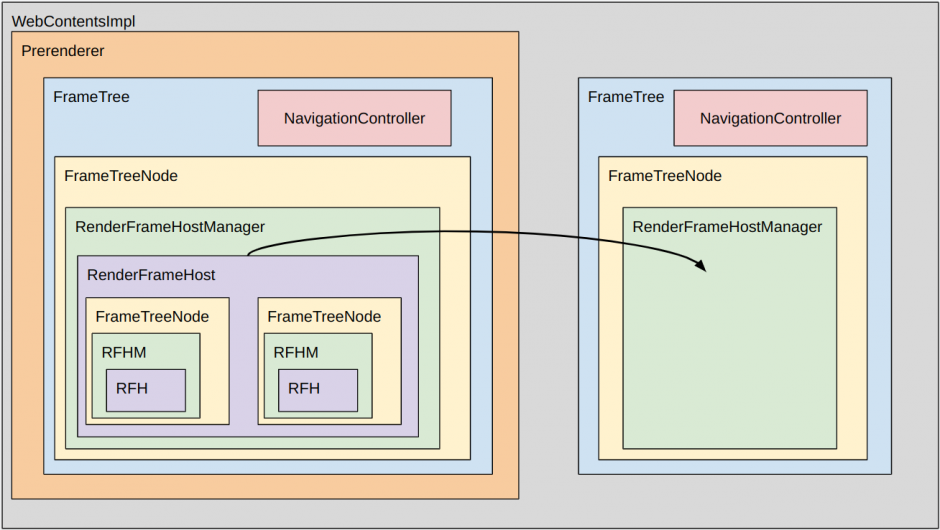
Fenced Frame The fenced frame enforces a boundary between the embedding page and the cross-site embedded document such that user data visible to the two sites is not able to be joined together.
The fenced frame works similarly to the main frame for security and privacy-related access, and to the subframe for other cases on the browser side. To this end, it is wrapped as a dummy FrameTreeNode in FrameTree, and the fenced frame can be accessed through a delegate.
GuestView & Portals Chromium implements a tag with a GuestVIew which is the templated base class for out-of-process frames in the chrome layer. For more detail, please refer to Julie’s blog.
Portals allow the embedding of a page inside another page, which can later be activated and replace the main page.
The GuestView and Portals are implemented with a multiple WebContents model and considering refactoring to MPArch.
Pending Deletion When RenderFrameHost has started running unload handlers (this includes handlers for the unload, pagehide, and visibilitychange events) or when RenderFrameHost has completed running the unload handlers, RenderFrameHost‘s lifecycle is in the pending Deletion.
Reference FrameTreeNode from RenderFrameHost
Accessing FrameTreeNode from RenderFrameHost that enters BFCache, accessing FrameTreeNode from old RenderFrameHost that has already been swapped from the prerendered page, or accessing FrameTreeNode in the pending deletion status all have security issues. Currently, RenderFrameHost has direct access to FrameTreeNode internally and exposed methods to allow access to FrameTreeNode externally.
Introduce RenderFrameHostOwner RenderFrameHostOwner is an interface for RenderFrameHost to communicate with FrameTreeNode owning it which can be null or can change during the lifetime of RenderFrameHost to prevent accidental violation of implicit “associated FrameTreeNode stays the same” assumptions.
RenderFrameHostOwner is,
// - Owning FrameTreeNode for main RenderFrameHosts in kActive, kPrerender,
// kSpeculative or kPendingCommit lifecycle states.
// - Null for main RenderFrameHosts in kPendingDeletion lifecycle state.
// - Null for main RenderFrameHosts stored in BFCache.
// - Owning FrameTreeNode for subframes (which stays the same for the entire
// lifetime of a subframe RenderFrameHostImpl).
At all places where FrameTreeNode is used, we are auditing them if we could replace FrameTreeNode with RenderFrameHostOwner after checking what lifecycle states of RenderFrameHost we can have. However, there are still some places that are not available to use RenderFrameHostOwner (e.g. unload handler). We are still investigating how to deal with these cases. It would be necessary to refactor for RenderFrameHost::frame_tree_node(), which is widely used inside and outside RenderFrameHost, and that work is ongoing.
Now Chromium supports :dir pseudo-class as experimental (--enable-blink-features=CSSPseudoDir) since M89. I actively worked on this feature funded by eyeo. When I was working on :dir pseudo-class on Chromium, it was necessary to solve issues regarding the performance and functionality of existing direction implementations. This posting is about explaining these issues and how I had solved them in more detail. I also had a talk about this at BlinkOn14.
What is directionality?
All HTML elements have their own directionality. Let’s see a simple example.
1) LTR
When we add explicitly a dir attribute to an element like <div dir="ltr">, or in cases where an element that doesn’t have the dir attribute inherits it from its parent that has ltr direction, the element’s directionality is ltr.
2) RTL
When we add explicitly the dir attribute to an element like <div dir="rtl">, or when an element that doesn’t have the dir attribute inherits it from its parent that has rtl direction, the element’s directionality is rtl.
3) dir=auto
The element’s directionality is resolved through its own descendants, and it is determined as the directionality of the closest descendant that can determine directionality among the descendants. This is usually a character with bidirectional information.
How do elements have directionality in Blink?
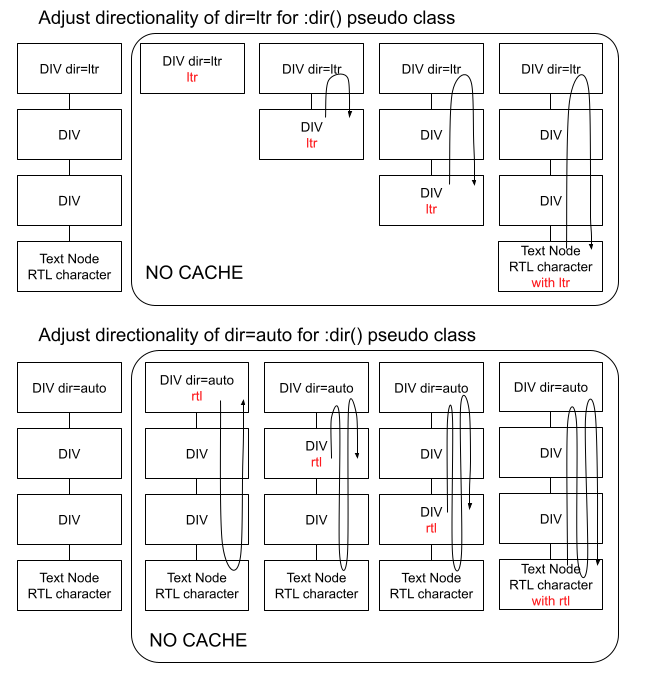
Before the element had a caching value for its direction, it depended on the direction property in ComputedStyle, and there were functionality and performance problems.
We didn’t know the directionality if ComputedStyle was not created yet.
We used it with the direction property of CSS in ComputedStyle, but not exactly the same with the element’s directionality.
There were cases when the directionality of the element needed to be recalculated even when there is no change in the element.
We need to recalculate more for :dir pseudo-class.
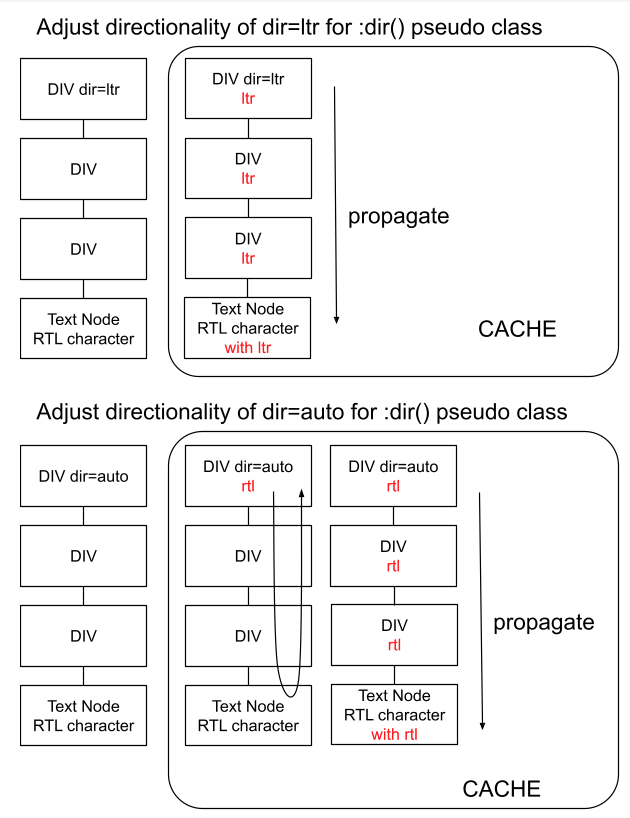
To solve these problems, we now cache the directionality of the element. We can see the detailed signatures in node.h.
There are the rules to cache the element directionality like
If dir=ltr|rtl, update the directionality of the element and its descendant immediately.
If dir=auto, resolve the directionality and update the element and its descendant immediately.
If no valid dir, use the directionality of the parent before parsing children.
If the child is inserted with no valid dir, use the directionality of the parent.
Complete caching the directionality of all elements before calculating the style.
Note: We have exception handling for the <slot> element to access it via the flattened tree, but it’s still in the middle of the implementation since it is still unclear and under discussion on the Web Spec.
Improved the performance for dir=auto by reducing a calculation of the directionality
Unfortunately, there are no comprehensive measurements of how much performance has improved after caching the directionality of all elements, because it is tricky to measure. However, theoretically, this is clearly a way to improve performance. In addition, a few additional patches had a chance to measure performance and we were able to see improvement. For instance, we do not adjust directionality if the new text’s direction is the same as the old one, or doesn’t have a strong directionality and drop out of the tree walk if the node changed children is passed during traversing. The following results were obtained.
You can also watch the talk online (47:40 min) presented on BlinkOn14.
I will post about :dir pseudo-class when we clarify <slot> and support the feature by default on Chromium. Thanks all!
Introduction
A few months ago, I’ve finished the task of replacing imprecise-width integer types like (unsigned) short, int, long, long long by precise-width integer types like (u)int16/int32/int64_t in Blink.. I’ve been working on the Onion Soup project and it was my first task of this project. When I took this task, I thought it would be comparatively simple and quite mechanical work, but this was not the case. It was sometimes required to understand whole code flow in-depth even out of blink or to explain the benefit of such changes to reviewers.
I’d like to introduce why we should prefer using the precise-width integer type and what I did for this task.
Why should we use the precise-width integer type?
We should keep in mind the fact that the c++ standards don’t specify the specific size of each integer type.
Data Model Table
Data model
sizeof(int)
sizeof(long)
sizeof(long long)
example
LP32
16b
32b
64b
Win16
ILP32
32b
32b
64b
Win32, i386 OSX & Linux
LP64
32b
64b
64b
x86-64 OSX & Linux
LLP64
32b
32b
64b
Win64
Chromium supports various platforms with one repository and shows definitely the variable of different sizes with (unsigned) long between Android-Kitkat/MacOS/Win7 buildbots and other buildbots for try-bots. It means that it would have potential security issues like the stack overflow if we treat that long has 64 bits precise since the size of long is 64 bits like long long on almost all of build systems. And we should avoid mixing the use of the precise-width integer type and the imprecise-width integer type to store the same value.
Actually, after working on this I got a report mentioning that my changes to move from imprecise-width to precise-width types fixed a security issue. This made me realize that more existing issues could still be fixed this way, and I started fixing other ones reported via ClusterFuzz after that.
Google also recommends this in its own coding styleguide, see here.
Summary of my contributions in Blink
1) Decided the order of the changing type.
unsigned short -> uint16_t / short -> int16_t
unsigned long long -> uint64_t / long long -> int64_t
unsigned long -> uint32_t or uint64_t, long -> int32_t or int64_t
2) Wrote the patch including only related codes.
3) Found what is the proper type.
Which type is proper between uint32_t and uint64_t when I should change unsigned long?
Every time I asked myself the question since I had to consider the fact that unsigned long was 32 bit on Mac, Android-kitkat and Window7 buildbot and was 64 bit on others so far. So I needed to understand its code flow and the use cases not only in Blink but also out of Blink. In general, it would be best to avoid integer-width conversions where possible and to only convert to larger types when needed.
4) Utilized the template instead of the functions for each type
I reduced the code quantity with the template and avoided the build error by duplicated definition.
5) Used base::Optional when the initial value is ambiguous.
In general the variable’s initial value would be 0 or -1, but base::Optional is more readable and simple than comparing 0 or -1 to check the initial value. Actually, I needed to reach a consensus with the review since it could change the code logic.
bool HasValidSnapshotMetadata() const { return snapshot_size_ >= 0; }
long long snapshot_size_;
6) Used CheckedNumeric to check the overflow of the variable.
static bool SizeCalculationMayOverflow(unsigned width,
unsigned height,
unsigned decoded_bytes_per_pixel) {
unsigned long long total_size = static_cast<unsigned long long>(width) *
static_cast<unsigned long long>(height);
if (decoded_bytes_per_pixel == 4)
return total_size > ((1 << 29) - 1);
return total_size > ((1 << 28) - 1);
}
The above code was the old one before I changed and it was for checking if the variable has the overflow, I took some time to fully understand it.
I’ve used CheckedNumeric since the reviewer let me know this utility. As you can see from the code below, it has been changed to be simple and readable.
7) Oops! MSVC!
The below code shows the different results due to compilers.
class Foo {
uint16_t a;
unsigned b : 16;
};
std::cout << sizeof(Foo);
The results are from clang : 4 bytes, gcc : 4 bytes and msvc : 8 bytes
So, it caused the build break with MSVC toolchain on Windows buildbots as the class size was increased. It took a long time to analyze the cause and solve this issue.
In conclusion, it was very simple to fix. See the code below.
class Foo {
unsigned a : 16;
unsigned b : 16;
};
8) Brought out the potential issue with with the overflow.
Blink can handle the width and height within 4 bytes range. The old code showed the abnormal layout result with overflowed width/height but it did not crash. I added the assertion code to check if there is the overflow when changing the type. Finally, we prevent the overflow and solve to layout the object’s position and size within the maximum value of 4 bytes.
9) Added PRESUBMIT check.
Now that we cleaned up the Blink code from the imprecise-width types, a PRESUBMIT hook was added to prevent them from being reintroduced to the sourcebase. So I added the PRESUBMIT check to ensure new uses do not come in again.
10) Why do we still use int and unsigned?
This is the comment of the reviewer and I also agree with it.
Thee C++ style guide states "We use int very often, for integers we know are not going to be too big, e.g., loop counters. Use plain old int for such things. You should assume that an int is at least 32 bits, but don't assume that it has more than 32 bits. If you need a 64-bit integer type, use int64_t or uint64_t."
The style guide does state not to use the imprecise-width integers like long long/long/short, but int is the imprecise-width type that is explicitly preferred. Among other reasons, this is likely for readability and the fact that ints are by default the "native"/fastest type, and potentially large concerns over code churn. More there is not any benefit to replace int to int32t and potentially large concerns over code churn.
I’m happy to contribute to Chromium & Blink with more stable code through changing to the precise-width integer type and to learn more about this particular domain.