HBase is an open source, non-relational, distributed database modelled after Google’s BigTable (Source: HBase, Wikipedia). BigTable is a data store that relies on GFS (Google Filesystem). Since Hadoop is an open source implementation of GFS and MapReduce, it perfectly made sense to build HBase on top of Hadoop.
Usually HBase is categorized as a NoSQL database. NoSQL is a term often used to refer to non-relational databases. For instance, Graph databases, Object-Oriented databases, Key-Value data stores or Columnar databases. All of them are NoSQL databases. In the recent years there have been an emerging interest in this type of systems as the relational model has proved to be no effective to solve certain problems, especially those related to storing and handling large amounts of data.
In the year 2000, Berkeley researcher Eric Brewer published a now foundational paper known as the CAP Theorem. This theorem states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency. All nodes see the same data at the same time.
- Availability. A guarantee that every request receives a response about whether it was successful or failed.
- Partition tolerance. The system continues to operate despite arbitrary message loss or failure of part of the system.
According to the theorem, a distributed system can satisfy any two of these guarantees at the same time, but not all three (Source: CAP theorem, Wikipedia).
Usually NoSQL systems are depicted within a triangle representing the CAP Theorem, being each of the angles one the aforementioned guarantees: consistency, availability and partition tolerance. Each system is located in one of the sides of the triangle, depending on the pair of features favoured.
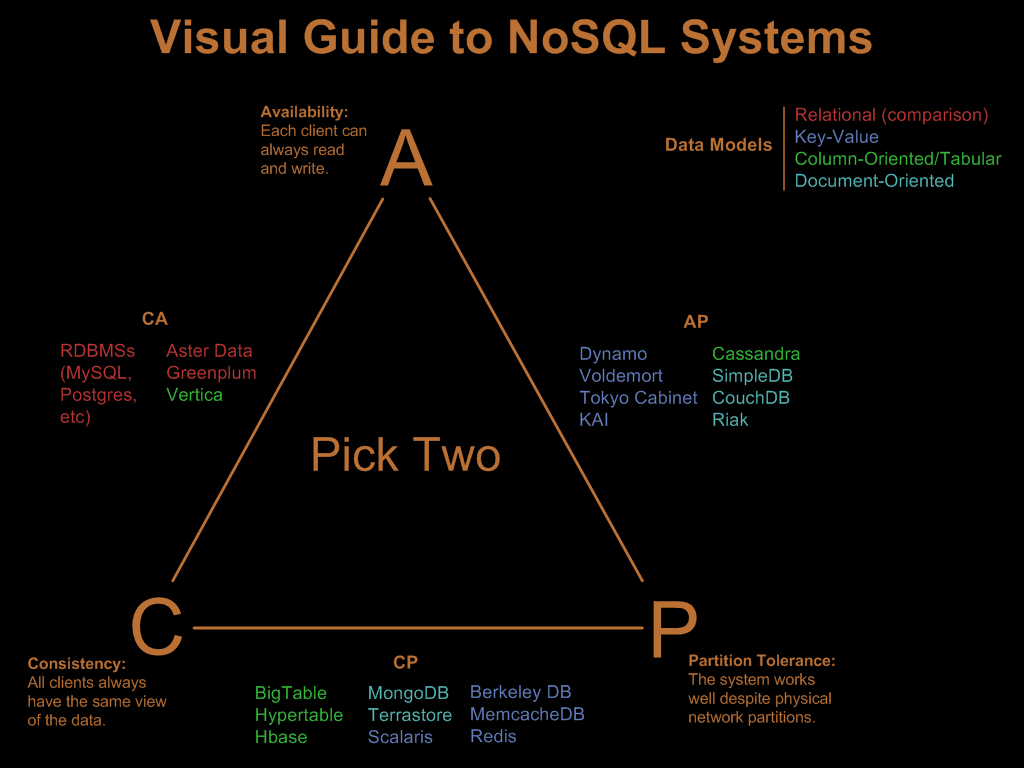
Visual Guide to NoSQL Systems (Source: http://blog.nahurst.com/visual-guide-to-nosql-systems)
As it is shown in the figure above, HBase is a columnar database that guarantees consistency of data and partition tolerance. On the other hand , systems like Cassandra or Tokyo Cabinet favour availability and partition tolerance.
Why NoSQL sytems have become relevant in the recent years? For the last 20 years the storage capacity of hard drives have multiply by several orders of magnitude, however seek and transfer times have not evolved at the same pace. Websites like Twitter receive more data everyday that it can write to a single hard drive, so data has to be written in clusters. Twitter users generate more than 12 TB per day, about 4 PB per year. Other sites, such as Google, Facebook or Netflix, handle similar figures, which means facing the same type of problems. But, big data storage and analysis is not something that only affects websites, for instance, the Large Scale Hadron Collider of Geneva produces about 12 PB per year.
HBase Data Model
HBase is a Columnar data store, also called Tabular data store. The main difference of a column-oriented database compared to a row-oriented database (RBMS) is about how data is stored in disk. Check how the following table would be serialized using a row-oriented and a column-oriented approach (Source: Columnar Database, Wikipedia).
| EmpId | Lastname | Firstname | Salary |
|---|---|---|---|
| 1 | Smith | Joe | 40000 |
| 2 | Jones | Mary | 50000 |
| 3 | Johnson | Cathy | 44000 |
Row-oriented
1,Smith,Joe,40000; 2,Jones,Mary,50000; 3,Johnson,Cathy,44000;
Column-oriented
1,2,3; Smith,Jones,Johnson; Joe,Mary,Cathy; 40000,50000,44000;
Physical organization has an impact on features such as partitioning, indexing, caching, views, OLAP cubes, etc. For instance, since common data is stored together, column-oriented excel at operations about aggregating data.
In HBase data is stored in tables, same as in the relational model. Each table consists of** rows, each identified by a RowKey. Each row has a fixed number of **column families. Each column family can contain a sparse number of columns. Columns also support versioning, that means, that different versions of the same column can exist at the same time. Versioning is usually implemented using a timestamp.
So, to fetch a value from a table we will need to specify three values: <RowKey, ColumnFamily, Timestamp>.
Perhaps the most obscure concept of this model are Column Families. Column Families consist of two parts: a prefix and a qualifier. The prefix is always fixed and it has to be specified when the table is created. However, the qualifier is dynamic and new qualifiers can be added to prefixes at run time. This allows to created an infinite collection of columns inside of column families. Take a look at the table below representing information about Students.
| RowKey | Timestamp | ColumnFamily |
|---|---|---|
| Student1 | t1 | courses:history=”H0112″ |
| Student1 | t2 | courses:math=”M0212″ |
| Student2 | t3 | courses:history=”H0112″ |
| Student2 | t4 | courses:geography=”G0112″ |
| Student2 | t5 | courses:geography=”G0212″ |
It is possible to add new courses just by storing new column families with the prefix courses. To get the code of the history subject Student1 is enrolled in , we need to provide three values: Student1; courses:history; timestamp. It is possible to retrieve all values in case a column family, with a different timestamp, is repeated. In the table above, we can see how Student2 is enrolled in the Geography course (timestamp=t4, courses:geography=”G0112″, however he enrolled again because the code of the subject changed (timestamp=t5; courses:geography=”G0212″).
Column Families work as a sort of light schema for the tables. Column families have to be specify when a table is created, and it is actually very hard to modify this schema. However, as the qualifier part of a column family is dynamic, it is very easy to add new columns to existing column families.
For further explanation about HBase Data Model I recommend the following articles: Hadoop Wiki – HBase DataModel, Understanding HBase and BigTable.
Features of HBase
HBase is built on top of Hadoop, that means, it relies on HDFS and it integrates very well with the MapReduce framework. Relying on HDFS provides a series of benefits:
- A distributed data storage running on top of commodity hardware
- Redundancy of data
- Fault-tolerant
In addition, HBase provides other series of benefits (among other features):
- Random reads and writes (this is not possible with plain Hadoop).
- Autosharding. Sharding, horizontal data distribution, is done automatically.
- Automatic failover based on Apache Zookeeper.
- Linear scaling of capacity. Just add new nodes as you need them.
Installing HBase
HBase depends on Hadoop, so it is necessary to install Hadoop before installing HBase. Currently there are several Hadoop branches being developed at the same time, so it is strongly recommended to install a HBase version that is compatible with a specific version of Hadoop (v1.0, v.0.22, v.0.23, etc). HBase v.0.90.6 is compatible with Hadoop v.1.x. To install HBase follow these steps:
- Install Hadoop if necessary.
- Download HBase.
- Move the downloaded tar file to /usr/local/share.
Now, uncompress it:
$ sudo tar xfvz hbase-0.90.6.tar.gz
Run HBase:
bin/start-hbase.sh
By default, HBase listens on port 60010. When a HBase server is running it is possible to check its state by connecting to http://locahost:60010.
Interacting with the HBase shell
First, start a HBase shell:
$ hbase shell
Once you are into a HBase session, create a new table:
> create 'students', 'courses'
Now insert some data into the table* ‘students’*.
put 'students', 'Student1', 'courses:history', 'H0112' put 'students', 'Student1', 'courses:math', 'M0212' put 'students', 'Student2', 'courses:history', 'H0112' put 'students', 'Student2', 'courses:geography', 'G0112' put 'students', 'Student2', 'courses:geography', 'G0212'
And now try the command ‘scan’ to show the contents of a table.
> scan 'students' ROW COLUMN+CELL Student1 column=courses:history, timestamp=1351332046854, value=H0112 Student1 column=courses:math, timestamp=1351332046914, value=M0212 Student2 column=courses:geography, timestamp=1351332047022, value=G0212 Student2 column=courses:history, timestamp=1351332046950, value=H0112 2 row(s) in 0.0390 seconds
The command ‘scan’ returns two rows (Student1 and Student2). Notice that the column family ‘courses:geography’ was inserted twice with different values, but only one value is shown. One of the features of HBase is versioning of data, this means that different versions of the same data can exist in the same table. Generally, this is implemented via a timestamp. So, why those two values don’t show up? To do so, it is necessary to tell scan how many versions of a row we would like to retrieve.
scan 'students', {VERSIONS => 3}
ROW COLUMN+CELL
Student1 column=courses:history, timestamp=1351332046854, value=H0112
Student1 column=courses:math, timestamp=1351332046914, value=M0212
Student2 column=courses:geography, timestamp=1351332047022, value=G0212
Student2 column=courses:geography, timestamp=1351332046990, value=G0112
Student2 column=courses:history, timestamp=1351332046950, value=H0112
2 row(s) in 0.0170 seconds
By default, when a table is created, the number of versions per Column Family is 3. However, it is possible to specify more:
> create 'students', {NAME => 'courses', VERSIONS => 10}
To fetch one Student:
> get 'students', 'Student2' COLUMN CELL courses:geography timestamp=1351332047022, value=G0212 courses:history timestamp=1351332046950, value=H0112 2 row(s) in 0.3100 seconds
The result displays all the current subjects Student2 is enrolled in.
If now we want to disenroll Student2 from subject* ‘history’*:
> delete 'students', 'Student2', 'courses:history'
<pre>get 'students', 'Student2' COLUMN CELL courses:geography timestamp=1351332047022, value=G0212 1 row(s) in 0.0140 seconds
Lastly, we drop table ‘students‘. Dropping a table is two-step operation:
> disable 'students' 0 row(s) in 2.0420 seconds
And now we can actually drop the table:
> drop 'students' 0 row(s) in 1.0790 seconds
Summary
This post was a brief introduction to HBase. HBase is a Columnar Database, usually categorized as a NoSQL database. HBase is built on top of Hadoop and shares many concepts with Google’s BigData, mainly its data model. In HBase data is stored in tables, being each table composed of rows and column families. A column family is a pair prefix:qualifier, where prefix is a fixed part and qualifier is variable. HBase also supports versioning by storing timestamp information for every column family. So, to retrieve a single value from a HBase table, the user has to specify three keys: <RowKey, ColumnFamily, Timestamp>. This way of storing/retrieving data makes that HBase is sometimes referred as a large sparse hash map.
As HBase relies on Hadoop it comes with the common features Hadoop provides: a distributed filesystem, data node fault tolerancy and good integration with the MapReduce framework. In addition, HBase provides other very interesting features such as autosharding, automatic failover, linear scaling of capacity and random reads and writes. The last one is a very interesting feature as plain Hadoop only allows to process the whole dataset in a batch.
And this is all for now. On a following post I will explain how to connect HBase with Hadoop, so it is possible to run MapReduce jobs over data stored in a HBase data store.
Please drop me a line if you have any feedback. Thanks!