
QuickJS: An Overview and Guide to Adding a New Feature
In a previous blog post, I briefly mentioned QuickJS (QJS) as an alternative implementation of JavaScript (JS) that does not run in a web browser. This time, I'd like to delve deeper into QJS and explain how it works.
First, some remarks on QJS's history and overall architecture. QJS was written by Fabrice Bellard, who you may know as the original author of Qemu and FFmpeg, and was first released in 2019. QJS is primarily a bytecode interpreter (with no JIT compiler tiers) that can execute JS relatively quickly.
You can invoke QJS from the command-line like NodeJS and similar systems:
$ echo "console.log('hello world');" > hello.js
$ qjs hello.js # qjs is the main executable for quickjs
hello worldQJS comes with another tool called qjsc that can produce small executable
binaries from JS source code. It does so by embedding QJS bytecode in C code
that links with the QJS runtime, which avoids the need to parse JS to bytecode
at runtime.
The following example demonstrates this (note: feel free to skip over the the details of this C code output, it's not crucial for the rest of the post):
$ qjsc hello.js -e -o hello.c # qjsc compiles the JS instead of running directly
$ cat hello.c
/* File generated automatically by the QuickJS compiler. */
#include "quickjs-libc.h"
const uint32_t qjsc_hello_size = 78;
const uint8_t qjsc_hello[78] = {
0x02, 0x04, 0x0e, 0x63, 0x6f, 0x6e, 0x73, 0x6f,
0x6c, 0x65, 0x06, 0x6c, 0x6f, 0x67, 0x16, 0x68,
0x65, 0x6c, 0x6c, 0x6f, 0x20, 0x77, 0x6f, 0x72,
0x6c, 0x64, 0x10, 0x68, 0x65, 0x6c, 0x6c, 0x6f,
0x2e, 0x6a, 0x73, 0x0e, 0x00, 0x06, 0x00, 0xa0,
0x01, 0x00, 0x01, 0x00, 0x03, 0x00, 0x00, 0x14,
0x01, 0xa2, 0x01, 0x00, 0x00, 0x00, 0x38, 0xe1,
0x00, 0x00, 0x00, 0x42, 0xe2, 0x00, 0x00, 0x00,
0x04, 0xe3, 0x00, 0x00, 0x00, 0x24, 0x01, 0x00,
0xcd, 0x28, 0xc8, 0x03, 0x01, 0x00,
};
static JSContext *JS_NewCustomContext(JSRuntime *rt)
{
JSContext *ctx = JS_NewContextRaw(rt);
if (!ctx)
return NULL;
JS_AddIntrinsicBaseObjects(ctx);
JS_AddIntrinsicDate(ctx);
JS_AddIntrinsicEval(ctx);
JS_AddIntrinsicStringNormalize(ctx);
JS_AddIntrinsicRegExp(ctx);
JS_AddIntrinsicJSON(ctx);
JS_AddIntrinsicProxy(ctx);
JS_AddIntrinsicMapSet(ctx);
JS_AddIntrinsicTypedArrays(ctx);
JS_AddIntrinsicPromise(ctx);
JS_AddIntrinsicBigInt(ctx);
return ctx;
}
int main(int argc, char **argv)
{
JSRuntime *rt;
JSContext *ctx;
rt = JS_NewRuntime();
js_std_set_worker_new_context_func(JS_NewCustomContext);
js_std_init_handlers(rt);
JS_SetModuleLoaderFunc(rt, NULL, js_module_loader, NULL);
ctx = JS_NewCustomContext(rt);
js_std_add_helpers(ctx, argc, argv);
js_std_eval_binary(ctx, qjsc_hello, qjsc_hello_size, 0);
js_std_loop(ctx);
JS_FreeContext(ctx);
JS_FreeRuntime(rt);
return 0;
}It's possible to embed parts of this C output into a larger program, for adding the ability to script a system in JS for example. You can also compile it, along with the QJS runtime, to WebAssembly (as is done in tools such as the Bytecode Alliance's Javy).
QJS as it exists today supports many features in the JS standard, but not all of them. What if you need to extend it to support modern JS features? Where would you start?
To address these questions, the rest of this post explains some of the internals of QJS by walking through the implementation of a new feature. The feature that we will explore is the ergonomic brand checks for private fields proposal, which I picked because it is a relatively simple and straightforward feature to implement. This proposal reached stage 4 in the TC39 process in 2021, and is currently part of the official ECMAScript 2022 standard.
Before getting into the details of adding the new feature, we'll first start with an explanation of what the proposal we are exploring actually does. After that, I'll explain how QJS processes JS code at a high-level before diving into the details of how to implement this proposal.
Explaining "ergonomic brand checks for private fields" #
The proposal we'll be exploring is titled "Ergonomic brand checks for private fields", which for the rest of this post I'll shorten to "private brand checks". Since ES2022, JS has supported private fields in classes. For example, you can declare a private field as follows:
class Foo {
#priv = 0; // private field declaration (needed for #priv to be in scope)
get() { return this.#priv; }
}
new Foo().get(); // returns 0
new Foo().#priv; // error, it's privateNote that the # syntax is special and only allowed for private field names.
Ordinary identifiers cannot be used to define a private field.
Private brand checks, also added in ES2022, are just a way to check if a given object has a given
private field with a convenient syntax. For example, the isFoo static method in the following
snippet uses a private brand check:
class Foo {
#priv; // necessary declaration
static isFoo(obj) { return #priv in obj; } // brand check for #priv
}
class Bar {
#priv; // a different #priv than above!
}
Foo.isFoo(new Foo()); // returns true
Foo.isFoo({}); // returns false
Foo.isFoo(new Bar()); // returns falseThe example shows that the proposal overloads the behavior of
in
so that if the left-hand side is a private field name, it checks for the
presence of that private field. Note that since private names are scoped
to the class, private names that look superficially identical in different
classes may not pass the same brand checks (as the example above showed).
Now that we know what this proposal does, let's talk about what it takes to implement it. Before explaining the nitty-gritty details, we'll first talk about the architecture of QJS at a high-level.
Architecture overview #
Most people probably run JS code in a web browser or via a runtime like NodeJS, Deno, or Bun that uses those browsers' JS engines. These engines typically use a tiered implementation strategy in which code often starts running in an interpreter and then tiers up to a compiler, perhaps multiple compilers, to produce faster code (see this blog post by Lin Clark for a high-level overview).
These engines typically also compile the JS source program into bytecode, an intermediate form that can be interpreted and compiled more easily than the source code or its parsed abstract syntax tree (AST).
QJS shares some of these steps, in that it also compiles JS to bytecode and then interprets the bytecode. However, it has no additional execution tiers.
While web browers generally have to fetch JS source code and compile to
bytecode while running (though there is bytecode caching
to optimize this), when QJS emits an executable (e.g., the use of qjsc from earlier)
it avoids the runtime parsing step by compiling the bytecode into the executable.
The QJS bytecode is designed for a stack machine (unlike, say, V8's Ignition interpreter which uses a register machine). That is, the operations in the bytecode fetch data from the runtime system's stack. WebAssembly (Wasm) made a similar choice, which reflects a goal shared by both Wasm and QJS to produce small binaries. A stack machine can save overhead in instruction encoding because the instructions do not specify register names to fetch operands from. Instead, instructions just fetch their operands from the stack.
Thus, the overall operation of QJS is that it parses a JS file and creates a representation of the module or script, which contains some functions. Each function is compiled to bytecode. Then QJS interprets that bytecode to execute the program.
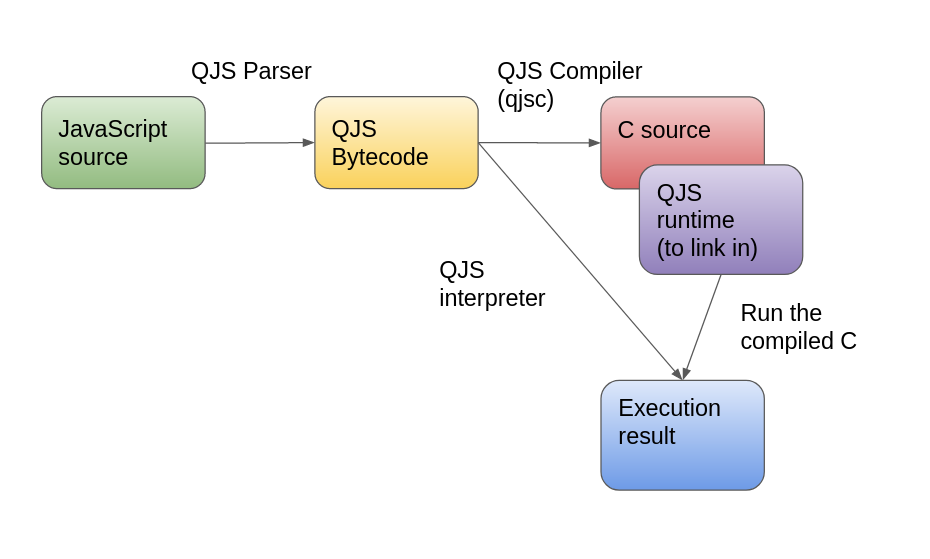
Adding support for a new proposal will affect several parts of this pipeline. In the case of private brand checks, we will need to modify the parser to accept the new syntax, add a new bytecode to represent the new operation, and add a new case in the core interpreter loop to implement that operation.
With that high-level overview in mind, we'll dive into specific parts of QJS in the following sections. Since QJS is written in C (in fact, the bulk of the system is contained in a single 10k+ line C file.), I'll be showing example snippets of C code to show what needs to change to implement private brand checks.
Parser #
The typical parsing pass in JS engines translates the JS source code to an internal AST representation. There is a separate bytecode generation pass that walks the AST and linearizes its structure into bytecodes.
QJS fuses these two passes and directly generates bytecode while parsing the source code. While this saves execution time, it does add its own kind of complexity.
To understand parsing, it's useful to know where QJS kicks off the process.
JS_EvalInternal is the entry
point for evaluating JS code. This can either evaluate and construct the runtime
representation of a script or module in order to execute it, or just compile it to bytecode
to emit to a file.
In turn, this will first run the lexer to create a tokenized version of the
source code. Afterwards, it calls js_parse_program to
parse the tokenized source code. The parser has its own state
(JSParseState) which contains information on where the parser is in the token
stream, the bytecodes emitted so far, and so on.
The parser broadly follows the structure of the JS specification's grammar,
in which statements and expressions are organized in a particular nesting structure to avoid ambiguity. For
modifying how the in operator gets parsed, we'll be interested in how relational expressions
in particular are parsed. As relational expressions are a kind of binary operator expression, they're handled in QJS by
the js_parse_expr_binary function.
That function handles binary operators by "level", corresponding to how they nest in the formal grammar. The bottom level consists
of multiplicative expressions, up to bitwise logical operators. The in operator is handled at level 5, along with other relational operators like <.
Since QJS will output the stack bytecode instructions in a single pass,
it's necessary in a binary expression like expr_1 in expr_2 to first parse
expr_1 and emit its bytecode, then parse expr_2 and emit that, then finally
emit the bytecode for OP_in (i.e., it's a post-order traversal of the AST, since
stack instructions are essentially postfix).
We won't need to change js_parse_expr_binary for private brand checks,
as the main difference from normal in operators is how the left-hand side is parsed.
For that, we'll be interested in js_parse_postfix_expr,
which parses references to variable names (and is eventually called by
js_parse_expr_binary). The js_parse_postfix_expr function,
like most other parsing functions, has a switch statement that dispatches on different
token types.
For example, there are tokens such as TOK_IDENT for ordinary identifiers for
variables (e.g., foo) and TOK_PRIVATE_NAME for private field names (e.g., #foo).
We will need to add a new case for private field tokens in the switch for js_parse_postfix_expr:
case TOK_PRIVATE_NAME:
{
JSAtom name;
// Only allow this syntax if the next token is `in`.
// The left-hand side of a private brand check can't be a nested expression, it
// has to specifically be a private name.
if (peek_token(s, FALSE) != TOK_IN)
return -1;
// I'll explain a bit about atoms later. This code extracts
// a handle for the string content of the private name.
name = JS_DupAtom(s->ctx, s->token.u.ident.atom);
if (next_token(s))
return -1;
// This is a new bytecode that we'll add that looks up that the private
// field is valid and produces data for the `in` operator.
emit_op(s, OP_scope_ref_private_field);
// These are the arguments for the above op code in the instruction stream.
emit_u32(s, name);
emit_u16(s, s->cur_func->scope_level);
break;
}This case allows a private name to appear, and only allows
it if the next token in the stream is in. We need the restriction because we don't want the
private name to appear in any other expression, as those are invalid (private names should
otherwise only appear in declarations in classes or in expressions like this.#priv).
It also emits the bytecode for this expression, which uses a
new scope_ref_private_field operator that we add. When new opcodes get added, they're
defined in quickjs-opcode.h.
The scope_ref_private_field opcode is a new variant on existing opcodes
like scope_get_private_field
that are already defined in that header.
The scope_ref_private_field operator actually never appears in
executable bytecode, and only appears temporarily as input to another pass. When I said bytecode
is emitted from the parser in a single pass earlier, this was actually a slight simplification.
After the initial parse, the bytecode goes through a scope resolution phase (see
resolve_variables) where certain
kinds of scope violations are ruled out. For example, the phase would signal an error on the following code:
// Invalid example
class Foo {
// missing declaration of #priv
foo(obj) { return #priv in obj; } // #priv is unbound
}There's also an optimization pass on the bytecode to obtain some speedups in interpretation later.
In the scope resolution phase, scope_ref_private_field is translated to a get_var_ref operation, which
looks up a variable in the runtime environment. This will resolve a variable to an index
that the runtime can use to look up the private field in an object's property table. The reason
we add this new operation is that existing operations like scope_get_private_field also
get translated to do the actual field lookup in the object immediately, whereas we want to wait until the
in operator is executed in order to do that.
Interpreter and runtime #
Once the bytecode compilation process is finished, the interpreter can start executing the program. QJS treats everything uniformly by considering all execution to take place in a function, so for example the code that runs in a module or script top-level is also in a special kind of function.
Therefore, all execution in QJS takes place in a core interpreter loop which runs a function body. It loads the bytecode for that function body and repeatedly runs the operations specified by the bytecode until it reaches the end. When executing the bytecode, the interpreter also maintains a runtime stack that stores temporary values produced by the operators. The interpreter allocates exactly enough stack space to run a particular function; the compiler pre-computes the max stack size for each function and encodes it in the bytecode format.
To add a new instruction, usually you add a new case to the big switch statement
in the main interpreter loop in JS_CallInternal.
Since we're just extending an existing operator, this case already exists.
So instead, we need to extend the helper function js_operator_in.
An annotated version of that function looks like this:
// Note: __exception is a QJS convention to warn if the result is unused
static __exception int js_operator_in(JSContext *ctx, JSValue *sp)
{
JSValue op1, op2;
JSAtom atom;
int ret;
// Reference the values in the top two stack slots
// op1 is the result of executing the left-hand side of the `in`
// op2 is the result of executing the right-hand side of the `in`
op1 = sp[-2];
op2 = sp[-1];
// op2 is the right-hand-side of `in`, which must be a JS object
if (JS_VALUE_GET_TAG(op2) != JS_TAG_OBJECT) {
JS_ThrowTypeError(ctx, "invalid 'in' operand");
return -1;
}
// Atoms are covered in more detail below
// but generally this just converts a string or symbol to a
// handle to an interned string, or it's a tagged number
atom = JS_ValueToAtom(ctx, op1);
if (unlikely(atom == JS_ATOM_NULL))
return -1;
// Look up if the property corresponding to left-hand-side name exists in the object.
ret = JS_HasProperty(ctx, op2, atom);
// QJS also has a reference-counting garbage collector. We need to appropriately
// free (i.e, decrement refcounts) on values when we stop using them.
JS_FreeAtom(ctx, atom);
if (ret < 0)
return -1;
JS_FreeValue(ctx, op1);
JS_FreeValue(ctx, op2);
// Push a boolean onto the top stack slot
// Note: the stack is shrunk after this by the main loop, so -2 is the top.
sp[-2] = JS_NewBool(ctx, ret);
return 0;
}At this point in the code, the results of evaluating the left- and right-hand
side expressions of an in are already on the stack. These are JS values, so
now might be a good time to talk about how values are represented in QJS.
Object Representation #
All JS engines have their own internal representation of JS values, which include primitive values such as symbols and numbers and also object values. Since JS is dynamically typed, a given function can be called with all kinds of values, so the engine's representation needs a way to distinguish the values to appropriately signal an error, or choose the correct operation.
To do this, values need to come with some kind of tag. Some engines use a tagging scheme such as NaN-boxing to store all values inside the bit pattern of a 64-bit floating point number (using the different kinds of NaNs that exist in the IEEE-754 standard to distinguish cases). My colleague Andy Wingo wrote a blog post on this topic a while ago, laying out various options that JS engines use.
QJS uses a much simpler scheme, and dedicates 128 bits to each JS value. Half of that is the payload (a 64-bit float, pointer, etc.) and half is the tag value. The following definitions show how this is represented in C:
typedef union JSValueUnion {
int32_t int32;
double float64;
void *ptr;
} JSValueUnion;
typedef struct JSValue {
JSValueUnion u;
int64_t tag;
} JSValue;On 32-bit platforms there is a different tagging scheme that I won't detail other than to note that it uses NaN-boxing with a 64-bit representation.
For the most part, the representation details are abstracted by various macros like JS_VALUE_GET_TAG
used in the example code above, so there won't be much need to directly interact
with the value representation in this post.
Reference counting and objects #
Compound data, such as objects and strings, are tracked by a relatively simple reference counting garbage collector in QJS. This is in contrast to the much more complex collectors in web engines, such as WebKit's Riptide, that have different design tradeoffs and requirements such as the need for concurrency. There's a lot more to say about how reference counting and compound data work in QJS, but I'll save most of those details for a future post.
Atoms and strings #
Certain data types have a special representation because they are so common and are used repeatedly in the program. These are small integers and strings. These correspond to property names, symbols, private names, and so on. QJS uses a datatype called an Atom for these cases (which has already appeared in code examples above).
An atom is a handle that is either tagged as an integer, or is an index that refers to an interned string, i.e., a unique string that is only allocated once and stored in a hash table. Atoms that appear in the program's bytecode are also serialized in the bytecode format itself, and are loaded into the runtime table on initialization.
The data type JSAtom is defined as a uint32_t, so it's just a 32-bit integer.
Properties of objects, for example, are always accessed with atoms as the
property key. This means that property tables in objects just need to map
atoms to the stored values.
You can see this in action with the JS_HasProperty lookup above, which
looks like JS_HasProperty(ctx, op2, atom). This code looks up a key atom in the
object op2's property table. In turn, atom comes
from the line atom = JS_ValueToAtom(ctx, op1), which converts the
property name value op1 into either an integer or a handle to an interned string.
Changing the operation to support private fields #
The actual change to js_operator_in to support private brand checks is
very simple. In the case that the private field is a non-method field, the
resolved private name lookup via get_var_ref pushes a symbol value
onto the stack. This case doesn't require any changes.
In the case that the private field refers to a method, the name lookup pushes a function object onto the stack. We then need to run a private brand check with the target object and this private function, to ensure the private function really is part of the object.
At a high level, you can see the similarity between this operation and the runtime semantics described in the formal spec for the private brand check proposal.
The modified code looks like the following:
static __exception int js_operator_in(JSContext *ctx, JSValue *sp)
{
JSValue op1, op2;
JSAtom atom;
int ret;
op1 = sp[-2];
op2 = sp[-1];
if (JS_VALUE_GET_TAG(op2) != JS_TAG_OBJECT) {
JS_ThrowTypeError(ctx, "invalid 'in' operand");
return -1;
}
// --- New code here ---
// This is the same as the previous code, but now under a conditional.
// It doesn't need to change, because after resolving the private field
// name to a symbol via `get_var_ref` the normal `JS_HasProperty` lookup
// works.
if (JS_VALUE_GET_TAG(op1) != JS_TAG_OBJECT) {
atom = JS_ValueToAtom(ctx, op1);
if (unlikely(atom == JS_ATOM_NULL))
return -1;
ret = JS_HasProperty(ctx, op2, atom);
JS_FreeAtom(ctx, atom);
// New conditional branch, in case the field operand is an object.
// When a private method is referenced via `get_var_ref`, it actually
// produces the function object for that method. We then can call
// the `JS_CheckBrand` operation that is already defined to check the
// validity of a private method call.
} else {
// JS_CheckBrand is modified to take a boolean (last arg) that
// determines whether to throw on failure or just indicate the
// success/fail state. This is needed as `in` doesn't throw when
// the check fails, it just returns false.
ret = JS_CheckBrand(ctx, op2, op1, FALSE);
}
// --- New code end ---
if (ret < 0)
return -1;
JS_FreeValue(ctx, op1);
JS_FreeValue(ctx, op2);
sp[-2] = JS_NewBool(ctx, ret);
return 0;
}Testing #
We can validate this implementation against the
official test262 tests. QJS comes with a
test runner that can run against test262 (invoking make test2 will run it).
Since we've added a new feature, we must also modify the tested features list
in the test262 configuration file
to specify that the feature should be tested. For private brand checks, we
change class-fields-private-in=skip in that file to class-fields-private-in.
After changing the test file, the test262 tests for the private brand check
feature all succeed with the exception of some syntax tests due to an existing
bug with how in is parsed in general in QJS (the code function f() { "foo" in {} = 0; } should fail to parse, but errors at runtime instead in QJS).
Wrap-up #
With the examples above, I've walked through what it takes to add a relatively simple JS language feature to QuickJS. The private brand checks proposal just adds a new use of an existing syntax, so implementing it mostly just touches the parser and core interpreter loop. A feature that affects more of the language, such as adding a new datatype or changing how functions are executed, would obviously require more code and deeper changes.
The full changes required to implement this feature (other than test changes) can be reviewed in this patch.
In future posts, I'm planning to explain other parts of the QJS codebase and potentially explore how it's being used in the WebAssembly ecosystem.
Header image credit: https://www.pexels.com/photo/selective-focus-photography-of-train-610683/
- Previous: Compiling Bigloo Scheme to WebAssembly
- Next: Porting BOLT to RISC-V