
Compiling Bigloo Scheme to WebAssembly
In the JavaScript world, browser implementations have focused on JIT compilation as a high-performance implementation technique. Recently, new applications of JS, such as on cloud compute and edge compute platforms, have driven interest in non-JIT implementations of the language. For these kinds of use cases, fast startup and predictable performance can make traditional implementation approaches appealing. An example implementation is QuickJS, which compiles JS to a bytecode format and interprets the bytecodes. Another approach is Manuel Serrano's work on Hopc, which is a performant AOT JS compiler that uses Scheme as an intermediate language.
Another direction that is gaining interest is compiling JavaScript to WebAssembly (Wasm). The motivations for this approach are explained very clearly in Lin Clark's article on making JS run fast on Wasm, and some of my Igalia colleagues are spearheading this effort with the SpiderMonkey JS engine in collaboration with Bytecode Alliance partners.
There is still an open question of if we can apply these techniques for AOT compilation of JS to compile JS to Wasm in a practical way (though the componentize-js effort appears to be building up to this using partial evaluation). One way to test this out would be to apply the previously mentioned Hopc compiler. Hopc compiles to Scheme which, via the Bigloo Scheme implementation, compiles to C. Using the standard C toolchain for Wasm (i.e., Emscripten), we can compile that C code to Wasm.
To even attempt this, we would have to first make sure Bigloo Scheme's C output can be compiled to Wasm, which is the main topic of this blog post.
Bigloo on Wasm #
In theory, it's simple to get Bigloo working with Wasm because it can emit C code, which you can compile with the C compiler of your choice. For example, you could use Emscripten's emcc to generate the final executable. In practice, it's more complicated than that.
For one, if you only compile the user Bigloo code to Wasm, it will fail to execute. The binary relies on several libraries that make up the runtime system, which themselves have to be compiled to Wasm in order to link a final executable.
The diagram below illustrates the compilation pipeline. The purple boxes at the lower right are the runtime libraries that need to be linked in.
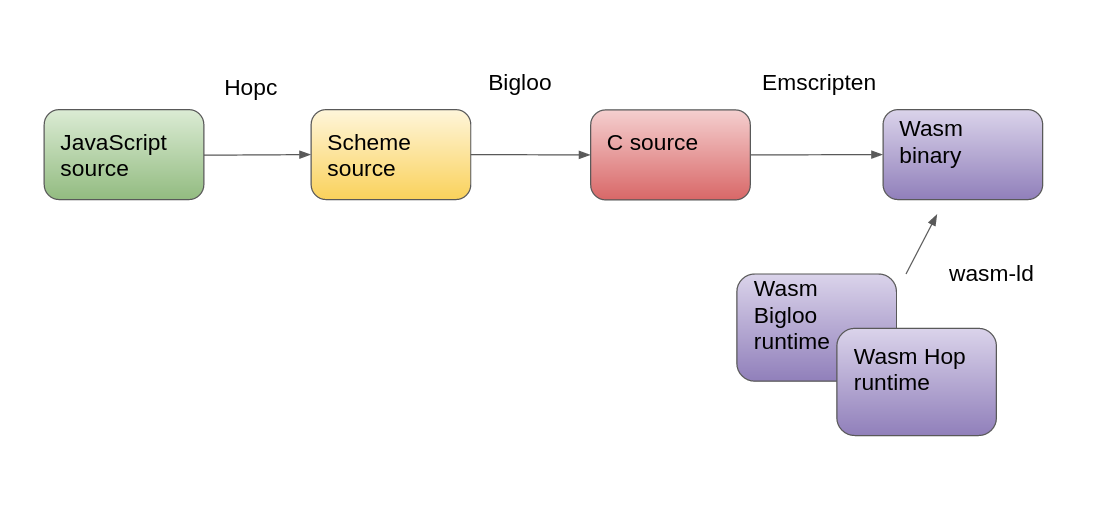
As a result, we will need to build Bigloo twice: once natively and once to Wasm. The latter build to Wasm will create the needed runtime libraries. This approach is also suggested in the Emscripten documentation for building projects that use self-execution.
I've scripted this approach in a Dockerfile that contains a reproducible setup for reliably compiling Bigloo to Wasm. You can see that starting at line 21 an ordinary native Bigloo is built, with a number of features disabled that won't work well in Wasm. Starting at line 42 a very similar build is done using the emconfigure wrapper that handles the configure script process for Emscripten. The options passed mirror the native build, but with some extra options needed for Wasm.
Like many projects that use Emscripten, some modifications are needed to get Bigloo to compile properly. For example, making C types more precise, backporting Emscripten compatibility patches for included libraries, and adjusting autoconf tests to return a desired result with Emscripten.
1 + 1 = 4? #
There are some tricky details that you need to get right to have working Wasm programs in the end. For example, when I first got a working docker environment to run Bigloo-on-Wasm programs, I got the following result:
$ cat num.scm # this is a Bigloo scheme module
(module num)
(display (+ 1 1)) (newline)
$ /opt/bigloo/bin/bigloo -O3 num.scm -o num.js -cc /emsdk/upstream/emscripten/emcc # compile to wasm, more arguments are needed in practice, this is a simplified example
$ emsdk/node/14.18.2_64bit/bin/node num.js # execute the compiled wasm in nodejs
4(Side note: if you haven't used a Wasm toolchain before, you may be confused why the output is num.js. Wasm toolchains often produce JS glue code that you use to load the actual Wasm code in a browser/JS engine.)
The Scheme program num.scm is supposed to print the result of "1 + 1". The wasm binary helpfully prints... 4. Other programs that I tried, like printing "hello world", resulted in the IO system trying to print random parts of Wasm's linear memory.
The proximal reason for this failure was that the value tagging code in the Bigloo runtime was being configured incorrectly. If you look at the Bigloo tagging code, you see these cpp definitions:
# define TAG_SHIFT PTR_ALIGNMENT
# define TAG_MASK ((1 << PTR_ALIGNMENT) - 1)
# define TAG_MASKOBJECT TAG_MASK
# define TAG_MASKPOINTER TAG_MASK
# define TAG(_v, shift, tag) \
((long)(((unsigned long)(_v) << shift) | tag))
# define UNTAG(_v, shift, tag) \
((long)((long)(_v) >> shift))
/* ... */
# define TAG_INT 0 /* integer tagging ....00 */The TAG operation is used throughout compiled Bigloo code to tag values into the unityped Scheme value representation. The default tagging scheme (see TAG_SHIFT) is a typical one that depends on the pointer alignment, which depends on the word size (4 bytes on 32-bit, 8 bytes on 64-bit). The PTR_ALIGNMENT definition is defined to be the log base 2 of the word size. This means 2 bits of the value are used for a tag on 32-bit platforms and 3 bits are used on 64-bit platforms.
In the case of numbers, the tag is 0 (TAG_INT above) so a discrepancy in tagging will produce a mis-shifted number value. That's exactly why the num.js program printed 4 above. It's the right answer 2 shifted by one bit.
The reason for that shift is that I was compiling native Bigloo in a 64-bit configuration since that's the architecture of the host machine. Wasm, however, is specified to have a 32-bit address space (unless the memory64 proposal is used). This discrepancy caused values to get shifted with 2 bits in some places, and 3 bits in others during tagging/untagging. After figuring this out, it was relatively easy to compile Bigloo with an i686 toolchain.
Function pointers #
After fixing 32-bit/64-bit discrepancies, simple Bigloo programs would run in a Wasm engine. On more complex examples, however, I was running into function pointer cast errors like the following:
$ emsdk/node/15.14.0_64bit/bin/node bigloo-compiled-program.js
RuntimeError: function signature mismatch
at <anonymous>:wasm-function[184]:0x3b430
at <anonymous>:wasm-function[1397]:0x3400bb
at <anonymous>:wasm-function[505]:0x118046
at <anonymous>:wasm-function[325]:0xd693e
at <anonymous>:wasm-function[4224]:0x71dd82
at Ya (<anonymous>:wasm-function[18267]:0x143d987)
at ret.<computed> (/test-output.js:1:112711)
at Object.doRewind (/test-output.js:1:114339)
at /test-output.js:1:114922
at /test-output.js:1:99074This is a documented issue that comes up when porting systems to Emscripten. It's not Emscripten's fault, because oftentimes the programs are relying on undefined behavior (UB) in C.
In particular, CPPReference says the following about function pointer casts:
Any pointer to function can be cast to a pointer to any other function type. If the resulting pointer is converted back to the original type, it compares equal to the original value. If the converted pointer is used to make a function call, the behavior is undefined (unless the function types are compatible)
which means that generally function pointer casts are undefined unless the source and target types are compatible. Bigloo has many cases where function pointers need to be cast. For example, the representation of Scheme procedures contains a field for a C function pointer:
/* procedure (closures) */
struct procedure {
header_t header;
union scmobj *(*entry)(); // <-- function pointer for the procedure entrypoint
union scmobj *(*va_entry)();
union scmobj *attr;
int arity;
union scmobj *obj0;
} procedure;The function pointer's C type cannot precisely capture the actual behavior even with a uniform value representation, as the arity of the Scheme procedure needs to be represented. C does not prevent you from calling the function with whatever arity you like though, as you can see in the Gstreamer API code:
obj_t proc = cb->proc; // A Scheme procedure object
switch( cb->arity ) {
case 0:
PROCEDURE_ENTRY( proc ) ( proc, BEOA ); // Extract the function entry pointer and call it
break;
case 1:
PROCEDURE_ENTRY( proc ) ( proc, convert( cb->args[ 0 ], BTRUE ), BEOA );
break;
/* ... */
}In practice, this kind of UB shouldn't cause problems for a typical C compiler because its output (assembly/machine code) is untyped. What matters is whether the calling convention is followed (it should be fine in Bigloo since these functions uniformly take and return scmobj* pointers).
Since Wasm has a sound static type system, it doesn't allow such loose typing of functions and will crash with a runtime type check if the types do not match. It's possible to work around this by using the EMULATE_FUNCTION_POINTER_CASTS Emscripten option to generate stubs that emulate the cast, but it adds significant overheads as the Emscripten docs note (emphasis mine):
Use EMULATE_FUNCTION_POINTER_CASTS. When you build with -sEMULATE_FUNCTION_POINTER_CASTS, Emscripten emits code to emulate function pointer casts at runtime, adding extra arguments/dropping them/changing their type/adding or dropping a return type/etc. This can add significant runtime overhead, so it is not recommended, but is be worth trying.
The overhead is clear in the generated code, because the option adds dummy function parameters to virtualize calls. Here's an example showing the decompiled Wasm code with emulated casts:
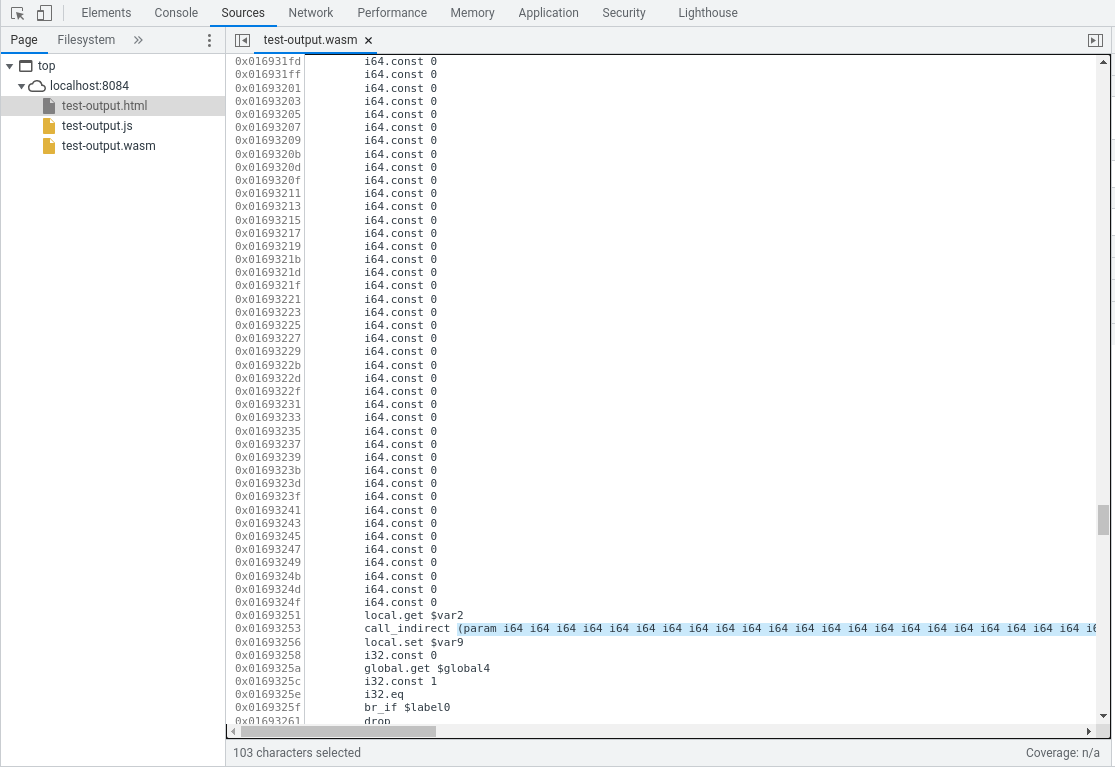
You can see that the function being called with call_indirect has a huge number of arguments (the highlighted (param i64 ...) shows the type of the function being called, and the (i64.const 0) ... above the call are the concrete arguments). There are more than 70 arguments here, and most of them are unused and are present only for the virtualization of the call. This can add up to a huge binary size cost, since there can also be a large number of functions in the Wasm module's indirect function table:
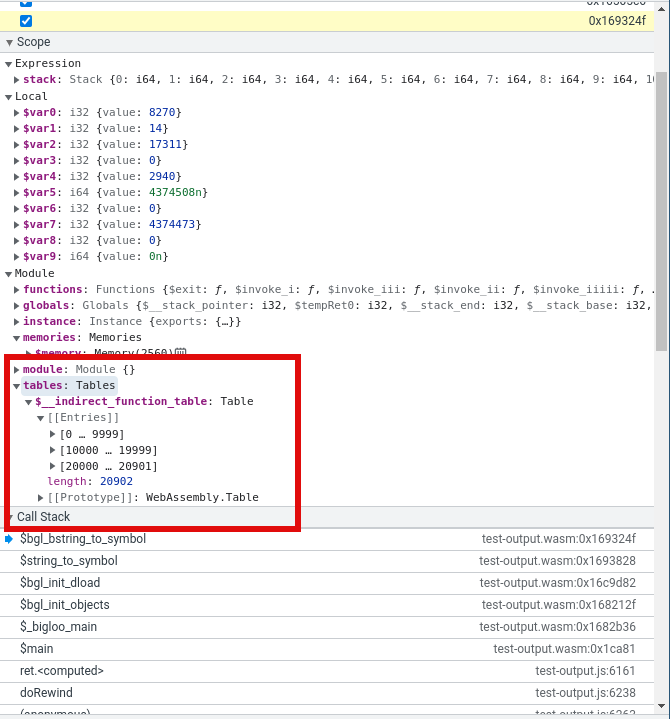
The screenshot from the V8 debugger above is showing the contents of the running module. In this case the module's table (highlighted in red) has over 20,000 function entries. Calls to many of these will incur the emulation overhead. It's not clear to me that there is any good way to avoid this cost without significantly changing the representation of values in Bigloo.
What about Hopc? #
After getting Bigloo to compile to Wasm, I did go back to the initial motivation of this blog post and tried to get Hopc (the JS to Scheme compiler) working in order to have a whole pipeline to compile JS to Wasm. While I was able to get a working build, I had some trouble producing a final Wasm program that could serve as a demo without crashing. At some point, some of the runtime initialization code hits a call_indirect on a null function pointer and crashes.
I suspect that even if I could resolve the crashes, there would be more work needed to make this practical for the use cases I described at the beginning. The best code size I've been able to get for a minimal JS program compiled to Wasm using this pipeline was 29MB, which is rather large. For comparison, Guy Bedford quoted in the JS to Wasm article linked earlier suggested 5-6MB was a reasonable number for a Spidermonkey embedding.
There may be opportunities to reduce this overhead. For example, disabling asyncify and function pointer cast emulation reduces the binary to 9.8MB, albeit a non-working one. Asyncify appears to be required to use the default BDW garbage collector due to the use of emscripten_scan_registers(). There is some discussion of possibly making the asyncify use optional (and possibly using Binaryen's "spill pointers" pass), but it looks like this will take more time to materialize. To avoid the asyncify overhead at the Bigloo level, it could be interesting to look into alternative GC configurations that don't use BDW at all. For the function pointer issue, maybe future changes that leverage the Wasm GC proposal (which has a ref.cast instruction that can cast a function reference to a more precise type) could provide a workaround.
Wrap-up #
It was fun to explore this possibility for AOT compiling JS to Wasm, and more generally it was a good exercise in porting a programming language to Wasm. While there were some tricky problems, the Emscripten tools were good at handling many parts of the process automatically.
I also had to debug a bunch of crashing Wasm code too, and found that the debug support was better than I expected. Passing the debug mode flag -g to emcc helped in getting useful stack traces and in utilizing the Chrome debugger. Though I did wish I had access to a rr-style time travel debugger to continue backwards from a crash site.
With regard to Hopc, I think it could be worth exploring further if the runtime crashes in Wasm can be resolved and if the binary size could be brought down using some of the approaches I suggested above. For the time being though, if you wanted to compile Scheme to Wasm you have an option available now with Bigloo. The Bigloo setup can compile some non-trivial Scheme programs too, such as this demo page that uses Olin Shivers' maze program compiled to Wasm: https://people.igalia.com/atakikawa/wasm/bigloo/maze.html
For another path to use Scheme on Wasm, also check out my colleagues' work to compile Guile to Wasm.
Header image credit: https://www.pexels.com/photo/close-up-photo-of-codes-1089440/