DRM scheduling cgroup controller
Introduction #
The topic of a Direct Rendering Manager (DRM) cgroup controller is something which has been proposed a few times in the past, but so far is still missing from the Linux graphics stack. Some of those attempts were focusing on controlling the GPU memory usage aspect, while some were concerned with scheduling. As I am continuing to explore this area as part of my work at Igalia, in this post we will discuss one possible way of implementing the latter.
General problem statement which we are trying to address is the fact many GPUs (and their respective kernel drivers) can simultaneously schedule workloads from different clients and that there are use-cases where having external control over scheduling decisions would be beneficial.
But first to clarify what we mean by “external control”. By that term we refer to the scheduling decisions being influenced from the outside of the actual process doing the rendering. If we were to draw a parallel to CPU scheduling, that would be the difference between a process (or a thread) issuing a system call such as setpriority(2) or nice(2) itself (“internal control”), versus its scheduling priority being modified by an external entity such as the user issuing the renice(1) shell command, launching the executable via the nice(1) shell command, or even using the CPU scheduling cgroup controller (“external control”).
This has two benefits. Firstly, it is the user who typically knows which tasks are higher priority and which should run in the background and therefore be as much as it is possible isolated from starving the foreground tasks from resources. Secondly, external control can be applied on any process in an unified manner, without the need for applications to individually expose the means to control their scheduling priority.
If we now return back to the world of GPU scheduling we find ourselves in a landscape where internal scheduling control is possible with many GPU drivers, but the external control is not. To improve on that there are some technical and conceptual challenges, because GPUs are not as nice and uniform in their scheduling needs and capabilities as CPUs are, but if we would be able to come up with something reasonable even if not perfect, it could bring improvements to the user experience in a variety of scenarios.
Past attempts - Priority based controllers #
The earliest attempt I can remember was from 2018, by Matt Roper[1], who proposed to implement a driver-specific priority based controller. The RFC limited itself to i915 (kernel driver for Intel GPUs) and, although the priority-based setup is well established in the world of CPU scheduling, and it is easy to understand its effects, the proposal did not gain much traction.
Because of the aforementioned advantages, when I proposed my version of the controller in 2022[2], it also included a slightly different version of a priority-based controller. In contrast to the earlier one, this proposal was in principle driver-agnostic and the priority levels were also abstracted.
The proposal was also accompanied by benchmark results showing that the approach was effective in allowing users on Linux to launch GPU tasks in the background, while leaving more GPU bandwidth to the foreground task than when not using the controller. Similarly on ChromeOS, when wired into the focused versus un-focused window cgroup management, it was able to demonstrate relatively more GPU time given to the foreground window.
Current proposal - Weight based controller #
Anticipating the potential lack of sufficient support for this approach the same RFC also included a second controller which takes a different route. It abstracts things one step further and implements a weight based controller based on GPU utilisation[3].
The basic idea is that the GPU time budget is split based on relative group weights across the cgroup hierarchy, and that the controller notifies the individual DRM drivers when their clients are over budget. From there it is left for the individual drivers to know how to best manage this situation, depending on the specific scheduling capabilities of the driver and the GPU hardware.
The user interface completely mimics the exiting CPU and IO cgroup controllers with the single drm.weight control file. The weights carry no absolute meaning and are only relative within a single group of siblings. Their only purpose is to split out the time budget between them.
Visually one potential cgroup configuration could look like this:
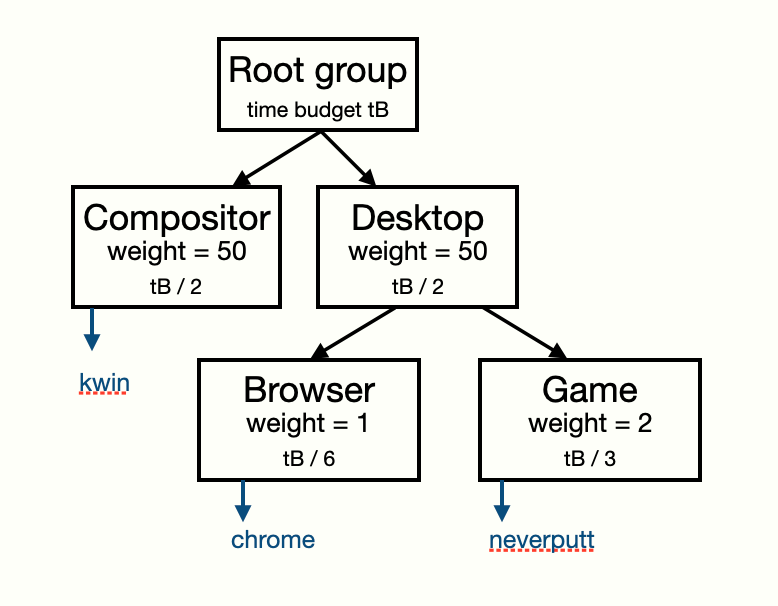
The DRM cgroup controller then executes a periodic scanning task which queries each DRM client for its GPU usage and notifies drivers when clients are over their allocated budget.
If we expand the concept with runtime adjustment of group weights based on window focus status, with two graphically active clients such as a game and a web browser, we can end up with the following two scenarios:
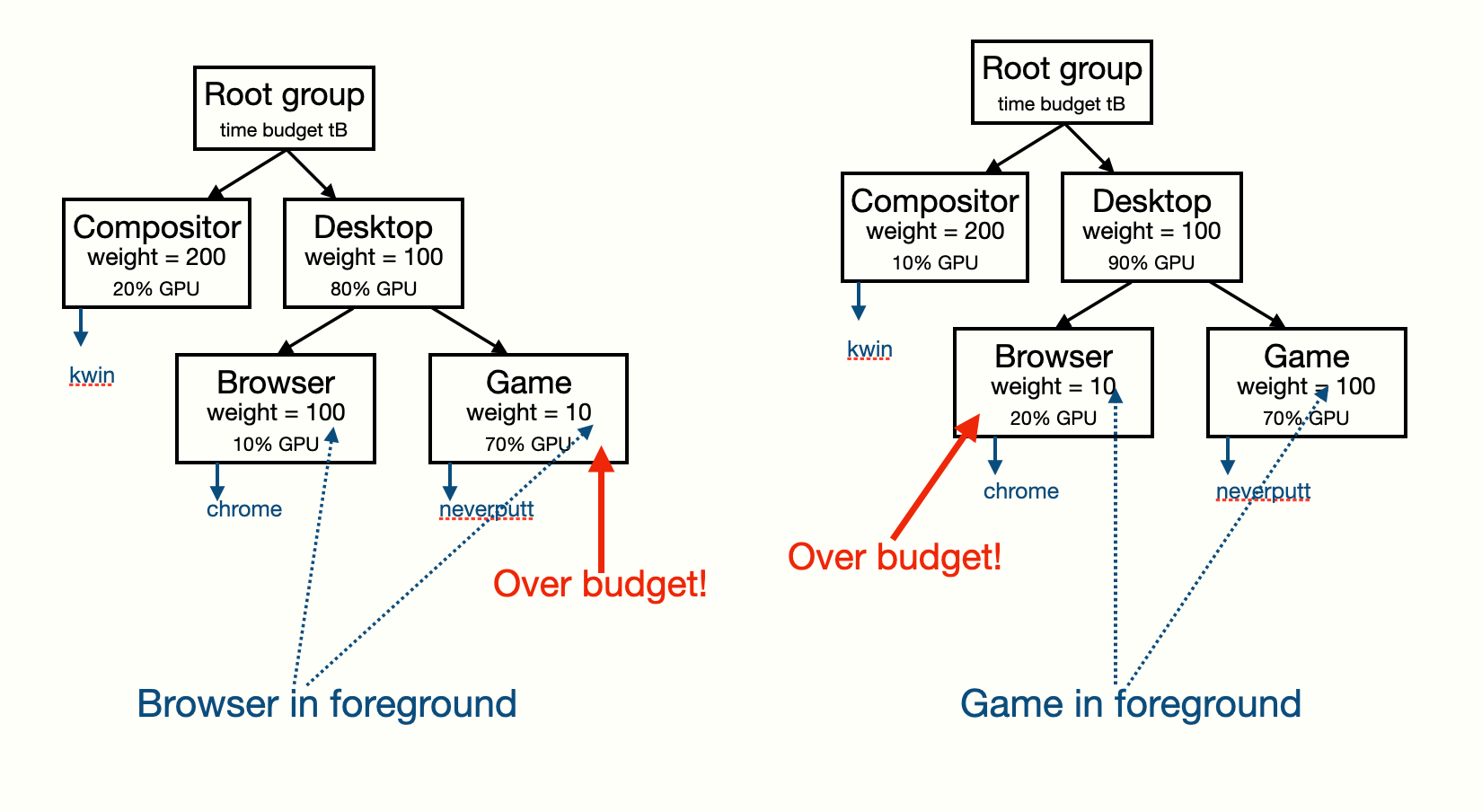
Here we show the actual GPU utilisation of each group together with their drm.weight. On the left hand side the web browser is the focused window, with the weights 100-to-10 in its favour.
The compositor is not using its full 200 / (200 + 100) so a portion is passed on to the desktop group to the extent of the full 80% required. Inside the desktop group the game is currently using 70%, while its actual allocation is 80% * (10 / (100 + 10)) = 7.27%. Therefore it is currently consuming is more than the budget and the corresponding DRM driver will be notified by the controller and will be able to do something about it.
After the user has given focus to the game window, relative weights will be adjusted and so will the budgets. Now the web browser will be over budget and therefore it can be throttled down, limiting the effect of its background activity on the foreground game window.
First driver implementation - i915 #
Back when I started developing this idea Intel GPU’s were my main focus, which is why i915 was the first driver I wired up with the controller.
There I implemented a rather simple approach of dynamically adjusting the scheduling priority of the throttled contexts, to the amount proportional to how much client is over budget in relative terms.
Implementation would also cross-check against the physical engine utilisation, since in i915 we have easy access to that metric, and only throttle if the latter is close to being fully utilised. (Why this makes sense could be an interesting digression relating to the fact that a single cgroup can in theory contain multiple GPUs and multiple clients using a mix of those GPUs. But lets leave that for later.)
One of the scenarios I used to test how well this works is to run two demanding GPU clients, each in its own cgroup, tweak their relative weights, and see what happens. The results were encouraging and are shown in the following table.
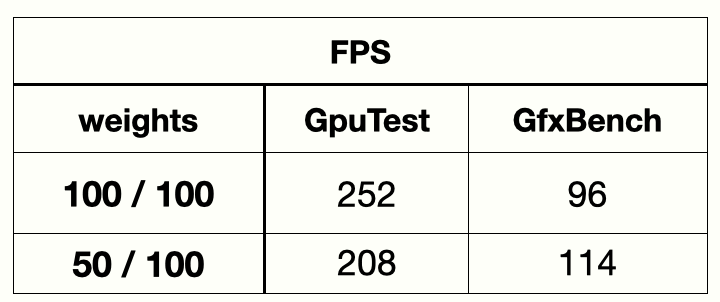
We can see that, when a clients group weight was decreased, the GPU bandwidth it was receiving also went down, as a consequence of the lowered context priority after receiving the over-budget notification.
This is a suitable moment to mention how the DRM cgroup controller does not promise perfect control, that is, achieving the actual GPU sharing ratios as expressed by group-relative weights. As we have mentioned before, GPU scheduling is not nearly at the same level of quality and granularity as in the CPU world, so the goal it sets is simply to improve things - do something which has a positive impact on user experience. At the same time, the mechanism and control interface proposed does not preclude individual drivers doing as good job as they can. Or even a future possibility of replacing the inner workings with a controller with something smarter, with no need to change the user space control interface.
Going back to the initial i915 implementation, the second test I have done was attempting to wire up with the background/foreground window focus handling in ChromeOS. There I experimented with a game (Android VM) running in parallel with a WebGL demo in a browser. At a certain point after both clients were running I lowered the weight of the background game and on the below screenshot we can see how the FPS metric in a browser jumped up.
This illustrates how having the controller can indeed improve the user experience. The user’s focus will be at the foreground window and therefore it does make sense to prioritise GPU access to that client for better interactiveness and smoother rendering there. In fact, in this example the actual FPS jumped from around 48-49 to 60fps. Meaning that throttling the background client has allowed the foreground one to match its rendering to display’s refresh rate.
Second implementation - amdgpu #
AMD’s kernel module was the next interesting driver which I wired up with the controller.
The fact that its scheduling is built on top of the DRM scheduler with only three distinct priority levels mandated a different approach to throttling. We keep a sorted list of “most offending” clients (most out of budget, or most borrowed unused budget from the sibling group), with the idea that the top client on that list gets throttled by lowering its scheduling priority. That was relatively straightforward to implement and sounded like it could potentially satisfy the most basic use case of background task isolation.
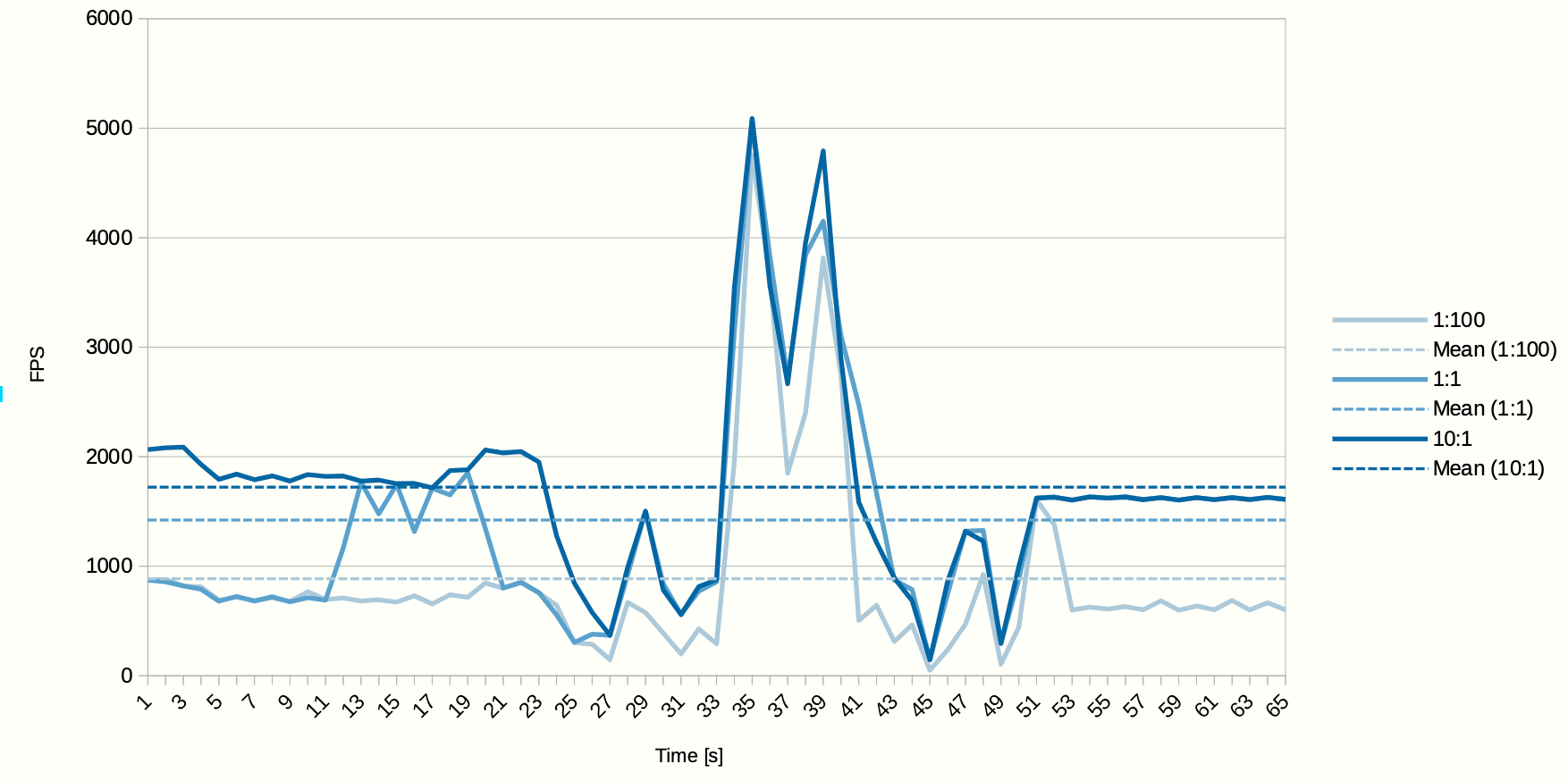
To test the runtime behaviour we set up two sibling cgroups and vary their relative scheduling weights. In one cgroup we run glxgears with vsync turned off and log its frame rate over time, while in the second group we run glmark2.
Let us first have a look on how glxgears frame rate varies during this test, depending on three different scheduling weight ratios between the cgroups. Scheduling weight ratio is expressed as glxgears:glmark2 ie. 10:1 means glxgears scheduling weight was ten times as much as configured for glmark2.
We can observe that, as the glmark2 is progressing through its various sub-benchmarks, glxgears frame rate is changing too. But it was overall higher in the runs where the scheduling weight ratio was in its favour. That is a positive result showing that even a simple implementation seems to be having the desired effect, at least to some extent.
For the second test we can look from the perspective of glmark2, checking how the benchmark score change depending on the ratio of scheduling weights.
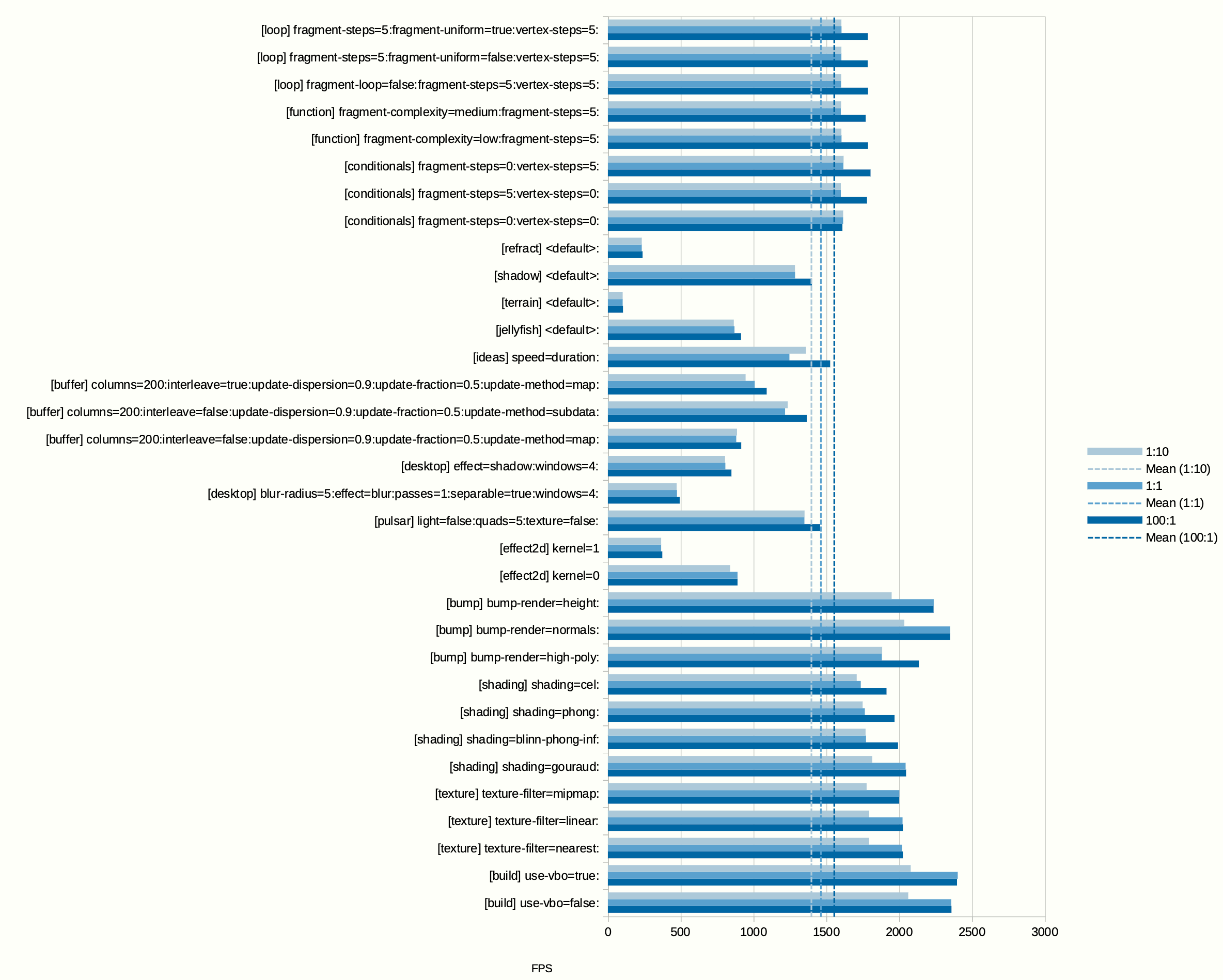
Again we see that the scores are generally improving when the scheduling weight ratio is increased in favour of the benchmark.
However, in neither case the change of the result is proportional to actual ratios. This is because the primitive implementation is not able to precisely limit the “background” client, but is only able to achieve some throttling. Also, there is an inherent delay in how fast the controller can react given the control loop is based on periodic scanning. This period is configurable and was set to two seconds for the above tests.
Conclusion #
Hopefully this write-up has managed to demonstrate two main points:
-
First, that a generic and driver agnostic approach to DRM scheduling cgroup controller can improve user experience and enable new use cases. While at the same time following the established control interface as it exists for CPU and IO control, which makes it future-proof and extendable;
-
Secondly, that even relatively basic driver implementations can be somewhat effective in providing positive control effects.
It also probably needs to be re-iterated that neither the driver implementations or the cgroup controller implementation itself are limited by the user interface proposed. Both could be independently improved under the hood in the future.
What is next? There is more work to be done such as conducting more detailed testing, polishing the implementation and potentially attempting to wire up more drivers to the controller. Further advocacy work in the DRM community too.