
I’ve been investigating the process of Chromium startup, the classes involved and the calls exchanged between them. This is a summary of my findings!
There are several implementations of a browser living inside Chromium source code, known as “shells”. Chrome is the main one, of course, but there are other implementations like the content_shell, a minimal browser designed to exercise the content API; the app_shell, a minimal container for Chrome Apps, and several others.
To investigate the difference between the different shell, we can start checking the binary entry point and find out how it evolves. This is a sequence diagram that starts from the content_shell main() function:
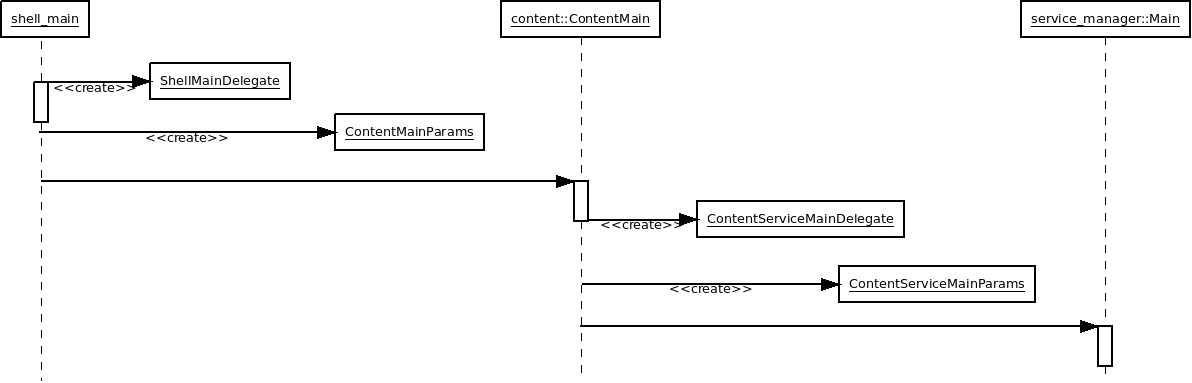
It creates two objects, ShellMainDelegate and ContentMainParams, then hands control to ContentMain() as implemented in the content module.
Chrome’s main is very similar, it also spawns a couple objects and then hands control to ContentMain(), following exactly the same code path from that point onward:
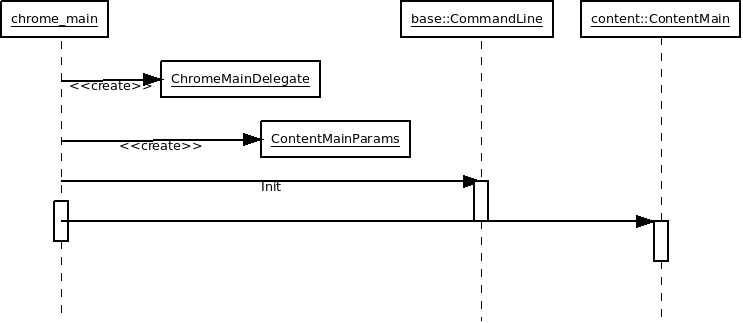
If we took a look to the app_shell, it would be very similar, and it’s probably the same for other shells, so where’s the magic? What’s the difference between the many shells in Chromium? The key is the implementation of that first object created in the main() function:
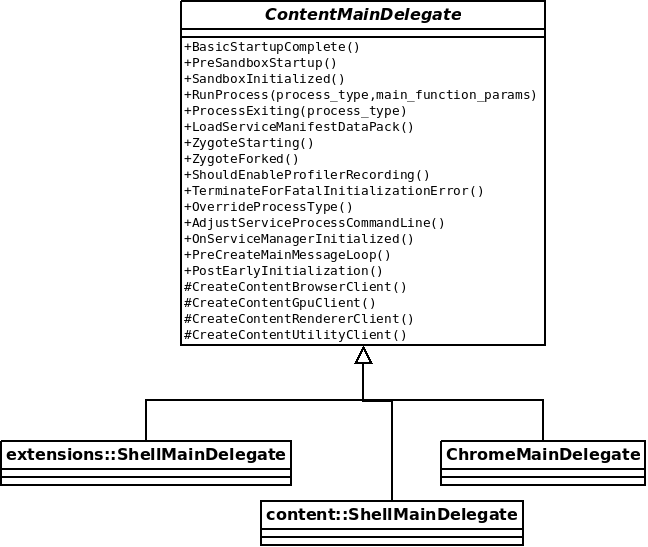
Those *MainDelegate objects created in main() are implementations of ContentMainDelegate. This delegate will get the control in key moments of the initialization process, so the shells can customize what happens. Two important events are the calls to CreateContentBrowserClient and CreateContentRendererClient, which will enable the shells to customize the behavior of the Browser and Render processes.
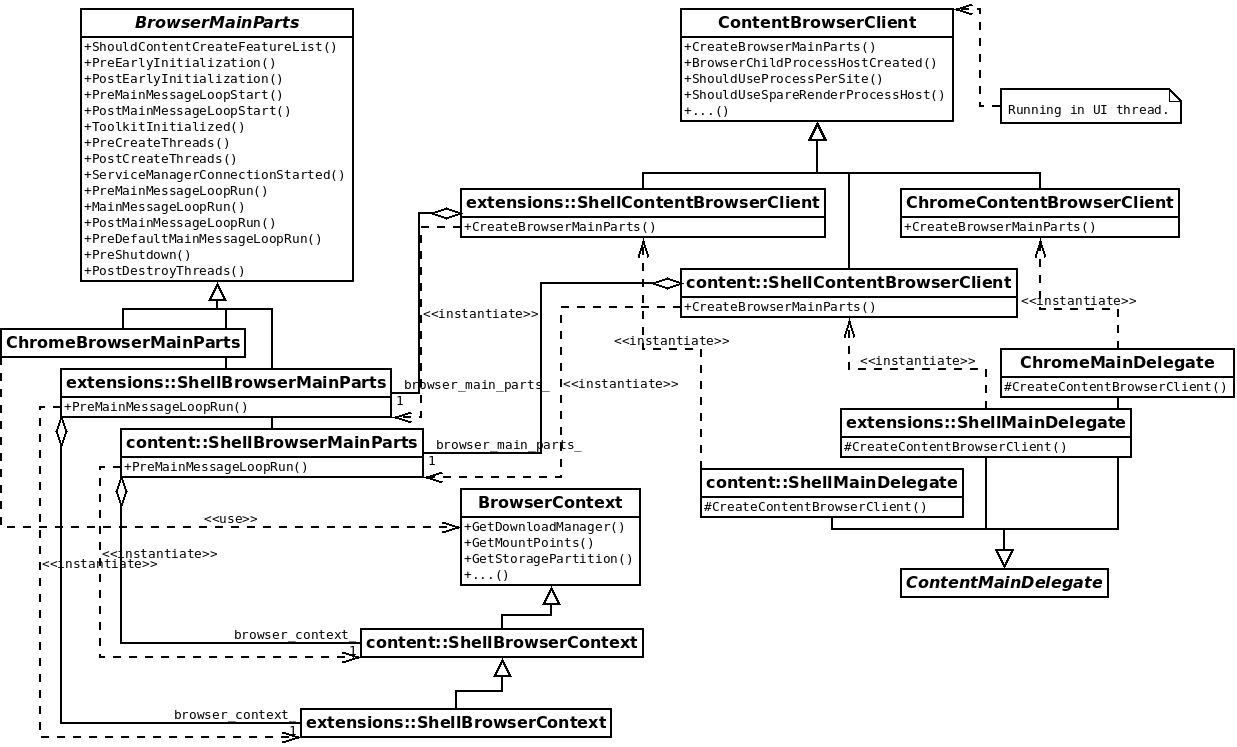
The diagram above shows how the ContentMainDelegate implementations provided by the different shells intantiate each their own implementation of ContentBrowserClient. This class runs in the UI thread and is able to customize the browser logic, its API is able to enable or disable certain parameters (e.g. AllowGpuLaunchRetryOnIOThread), provide delegates on certain objects (e.g. GetWebContentsViewDelegate), etc. A remarkable responsibility of ContentBrowserClient is providing an implementation of BrowserMainParts, which runs code in certain stages of the initialization.
There is a parallel hierarchy of ContentRendererClient classes, which works analogously to what we’ve just seen for ContentBrowserClient:

The specific case of extensions::ShellContentRendererClient is interesting because it contains the details to setup the extension API:
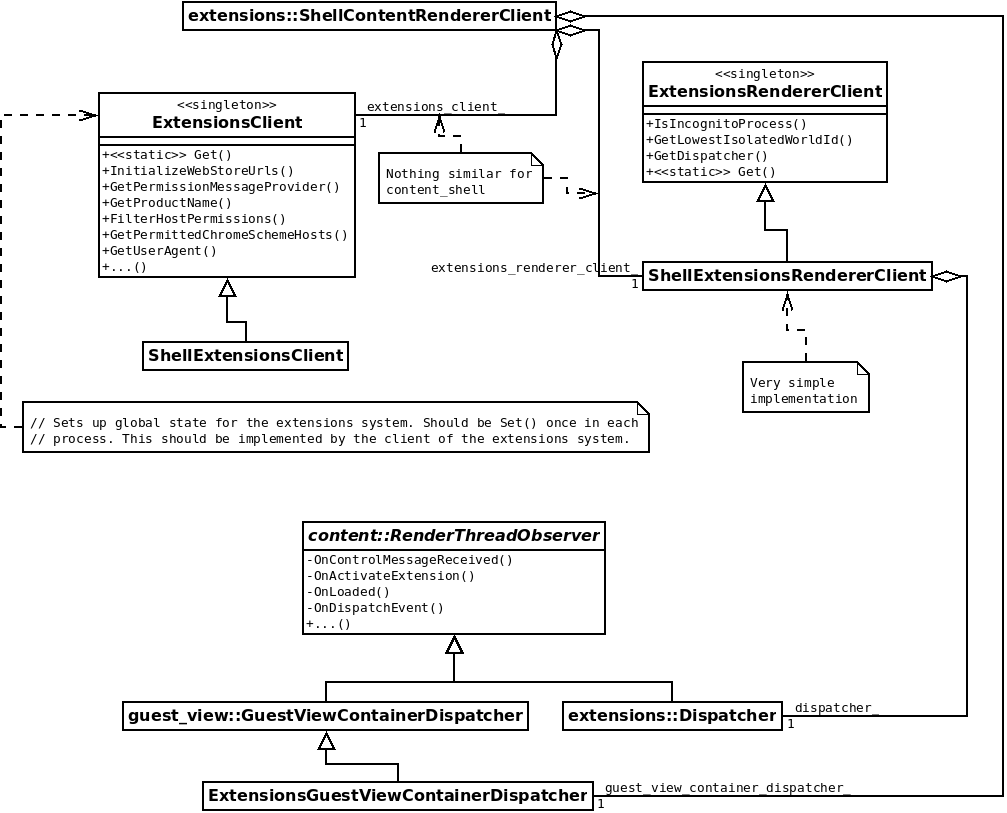
The purpose of both ExtensionsClient and ExtensionsRendererClient is to set up the extensions system. The difference lies in the knowledge of the renderer process and its concepts by ExtensionsRendererClient, only methods that make use of this knowledge should be there, otherwise they should be part of ExtensionsClient, which has a much bigger API already.
The specific implementation of ShellExtensionsRendererClient is very simple but it owns an instance of extensions::Dispatcher; this is an important class that sets up extension features on demand whenever necessary.
The investigation may continue in different directions, and I’ll try to share more report like this one. Finally, these are the source files for the diagrams and a shared document containing the same information in this report, where any comments, corrections and updates are welcome!
I’m glad to see that I’m not the only one that still uses DIA to make diagrams! Even at job, although they ask me why I’m still using it.
I love that small and useful program. By the way, a great and interesting article.
Regards!
Thanks! 🙂
Pingback: Initialization of the Chromium extension API system | Jacobo's home at Igalia