Turnips in the wild (Part 3)
This is the third part of my “Turnips in the wild” blog post series where I describe how I found and fixed graphical issues in the Mesa Turnip Vulkan driver for Adreno GPUs. If you missed the first two parts, you can find them here:
Psychonauts 2
A few months ago it was reported that “Psychonauts 2” has rendering artifacts in the main menu. Though only recently I got my hands on it.

Step 1 - Toggling driver options
Forcing direct rendering, forcing tiled rendering, disabling UBWC compression, forcing synchronizations everywhere, and so on, nothing helped or changed the outcome.
Step 2 - Finding the Draw Call and staring at it intensively
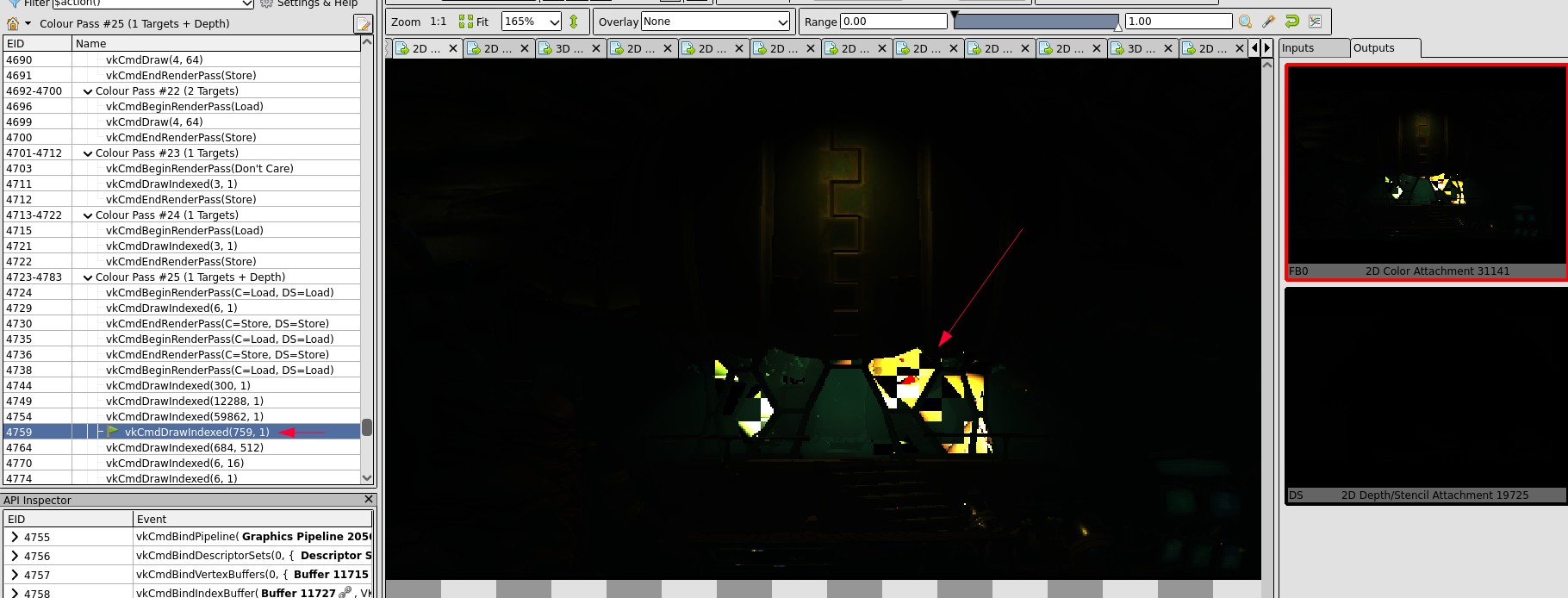
When looking around the draw call, everything looks good, but a single input image:

Ughhh, it seems like this image comes from the previous frame, that’s bad. Inter-frame issues are hard to debug since there is no tooling to inspect two frames together…
* Looks around nervously *
Ok, let’s forget about it, maybe it doesn’t matter. Then next step would be looking at the pixel values in the corrupted region:
Now, let’s see whether RenderDoc’s built-in shader debugger would give us the same value as GPU or not.
(Or not)
After looking at the similar pixel on the RADV, RenderDoc seems right. So the issue is somewhere in how driver compiled the shader.
Step 3 - Bisecting the shader until nothing is left
A good start is to print the shader values with debugPrintfEXT, much nicer than looking at color values. Adding the debugPrintfEXT aaaand, the issue goes away, great, not like I wanted to debug it or anything.
Adding a printf changes the shader which affects the compilation process, so the changed result is not unexpected, though it’s much better when it works. So now we are stuck with observing pixel colors.
Bisecting a shader isn’t hard, especially if there is a reference GPU, with the same capture opened, to compare the changes. You delete pieces of the shader until results are the same, when you get the same results you take one step back and start removing other expressions, repeat until nothing could be removed.
First iteration of the elimination, most of the shader is gone (click me)
float _258 = 1.0 / gl_FragCoord.w;
vec4 _273 = vec4(_222, _222, _222, 1.0) * _258;
vec4 _280 = View.View_SVPositionToTranslatedWorld * vec4(gl_FragCoord.xyz, 1.0);
vec3 _284 = _280.xyz / vec3(_280.w);
vec3 _287 = _284 - View.View_PreViewTranslation;
vec3 _289 = normalize(-_284);
vec2 _303 = vec2(in_var_TEXCOORD0[0].x, in_var_TEXCOORD0[0].y) * Material.Material_ScalarExpressions[0].x;
vec4 _309 = texture(sampler2D(Material_Texture2D_0, Material_Texture2D_0Sampler), _303, View.View_MaterialTextureMipBias);
vec2 _312 = (_309.xy * vec2(2.0)) - vec2(1.0);
vec3 _331 = normalize(mat3(in_var_TEXCOORD10_centroid.xyz, cross(in_var_TEXCOORD11_centroid.xyz, in_var_TEXCOORD10_centroid.xyz) * in_var_TEXCOORD11_centroid.w, in_var_TEXCOORD11_centroid.xyz) * normalize((vec4(_312, sqrt(clamp(1.0 - dot(_312, _312), 0.0, 1.0)), 1.0).xyz * View.View_NormalOverrideParameter.w) + View.View_NormalOverrideParameter.xyz)) * ((View.View_CullingSign * View_PrimitiveSceneData._m0[(in_var_PRIMITIVE_ID * 37u) + 4u].w) * float(gl_FrontFacing ? (-1) : 1));
vec2 _405 = in_var_TEXCOORD4.xy * vec2(1.0, 0.5);
vec4 _412 = texture(sampler2D(LightmapResourceCluster_LightMapTexture, LightmapResourceCluster_LightMapSampler), _405 + vec2(0.0, 0.5));
uint _418 = in_var_LIGHTMAP_ID; // <<<<<<-
float _447 = _331.y;
vec3 _531 = (((max(0.0, dot((_412 * View_LightmapSceneData_1._m0[_418 + 5u]), vec4(_447, _331.zx, 1.0))))) * View.View_IndirectLightingColorScale);
bool _1313 = TranslucentBasePass.TranslucentBasePass_Shared_Fog_ApplyVolumetricFog > 0.0;
vec4 _1364;
vec4 _1322 = View.View_WorldToClip * vec4(_287, 1.0);
float _1323 = _1322.w;
vec4 _1352;
if (_1313)
{
_1352 = textureLod(sampler3D(TranslucentBasePass_Shared_Fog_IntegratedLightScattering, View_SharedBilinearClampedSampler), vec3(((_1322.xy / vec2(_1323)).xy * vec2(0.5, -0.5)) + vec2(0.5), (log2((_1323 * View.View_VolumetricFogGridZParams.x) + View.View_VolumetricFogGridZParams.y) * View.View_VolumetricFogGridZParams.z) * View.View_VolumetricFogInvGridSize.z), 0.0);
}
else
{
_1352 = vec4(0.0, 0.0, 0.0, 1.0);
}
_1364 = vec4(_1352.xyz + (in_var_TEXCOORD7.xyz * _1352.w), _1352.w * in_var_TEXCOORD7.w);
out_var_SV_Target0 = vec4(_531.x, _1364.w, 0, 1);
After that it became harder to reduce the code.
More elimination (click me)
vec2 _303 = vec2(in_var_TEXCOORD0[0].x, in_var_TEXCOORD0[0].y);
vec4 _309 = texture(sampler2D(Material_Texture2D_0, Material_Texture2D_0Sampler), _303, View.View_MaterialTextureMipBias);
vec3 _331 = normalize(mat3(in_var_TEXCOORD10_centroid.xyz, in_var_TEXCOORD11_centroid.www, in_var_TEXCOORD11_centroid.xyz) * normalize((vec4(_309.xy, 1.0, 1.0).xyz))) * ((View_PrimitiveSceneData._m0[(in_var_PRIMITIVE_ID)].w) );
vec4 _412 = texture(sampler2D(LightmapResourceCluster_LightMapTexture, LightmapResourceCluster_LightMapSampler), in_var_TEXCOORD4.xy);
uint _418 = in_var_LIGHTMAP_ID; // <<<<<<-
vec3 _531 = (((dot((_412 * View_LightmapSceneData_1._m0[_418 + 5u]), vec4(_331.x, 1,1, 1.0)))) * View.View_IndirectLightingColorScale);
vec4 _1352 = textureLod(sampler3D(TranslucentBasePass_Shared_Fog_IntegratedLightScattering, View_SharedBilinearClampedSampler), vec3(vec2(0.5), View.View_VolumetricFogInvGridSize.z), 0.0);
out_var_SV_Target0 = vec4(_531.x, in_var_TEXCOORD7.w, 0, 1);
And finally, the end result:
vec3 a = in_var_TEXCOORD10_centroid.xyz + in_var_TEXCOORD11_centroid.xyz;
float b = a.x + a.y + a.z + in_var_TEXCOORD11_centroid.w + in_var_TEXCOORD0[0].x + in_var_TEXCOORD0[0].y + in_var_PRIMITIVE_ID.x;
float c = b + in_var_TEXCOORD4.x + in_var_TEXCOORD4.y + in_var_LIGHTMAP_ID;
out_var_SV_Target0 = vec4(c, in_var_TEXCOORD7.w, 0, 1);
Nothing left but loading of varyings and the simplest operations on them in order to prevent their elimination by the compiler.
in_var_TEXCOORD7.w values are several orders of magnitude different from the expected ones and if any varying is removed the issue goes away. Seems like an issue with loading of varyings.
I created a simple standalone reproducer in vkrunner to isolate this case and make my life easier, but the same fragment shader passed without any trouble. This should have pointed me to undefined behavior somewhere.
Step 4 - Going deeper
Anyway, one major difference is the vertex shader, changing it does “fix” the issue. Though changing it resulted in the changes in varyings layout, without changing the layout the issue is present. Thus the vertex shader is an unlikely culprit here.
Let’s take a look at the fragment shader assembly:
bary.f r0.z, 0, r0.x
bary.f r0.w, 3, r0.x
bary.f r1.x, 1, r0.x
bary.f r1.z, 4, r0.x
bary.f r1.y, 2, r0.x
bary.f r1.w, 5, r0.x
bary.f r2.x, 6, r0.x
bary.f r2.y, 7, r0.x
flat.b r2.z, 11, 16
bary.f r2.w, 8, r0.x
bary.f r3.x, 9, r0.x
flat.b r3.y, 12, 17
bary.f r3.z, 10, r0.x
bary.f (ei)r1.x, 16, r0.x
....
Loading varyings
bary.f loads interpolated varying, flat.b loads it without interpolation. bary.f (ei)r1.x, 16, r0.x is what loads the problematic varying, though it doesn’t look suspicious at all. Looking through the state which defines how varyings are passed between VS and FS also doesn’t yield anything useful.
Ok, but what does second operand of flat.b r2.z, 11, 16 means (the command format is flat.b dst, src1, src2). The first one is location from where varying is loaded, and looking through the Turnip’s code the second one should be equal to the first otherwise “some bad things may happen”. Forced the sources to be equal - nothing changed… What have I expected? Since the standalone reproducer with the same assembly works fine.
The same description which promised bad things to happen also said that using 2 immediate sources for flat.b isn’t really expected. Let’s revert the change and get something like flat.b r2.z, 11, r0.x, nothing is changed, again.
Packing varyings
What else happens with these varyings? They are being packed! To remove their unused components, so let’s stop packing them. Aha! Now it works correctly!
Looking several times through the code, nothing is wrong. Changing the order of varyings helps, aligning them helps, aligning only flat varyings also helps. But code is entirely correct.
Though one thing changes, during the shuffling of varyings order I noticed that the resulting misrendering changed, so likely it’s not the order, but the location which is cursed.
Interpolating varyings
What’s left? How varyings interpolation is specified. The code emits interpolations only for used varyings, but looking closer the “used varyings” part isn’t that obviously defined. Emitting the whole interpolation state fixes the issue!
The culprit is found, stale data is being read of varying interpolation. The resulting fix could be found in tu: Fix varyings interpolation reading stale values + cosmetic changes

Injustice 2

Another corruption in the main menu.
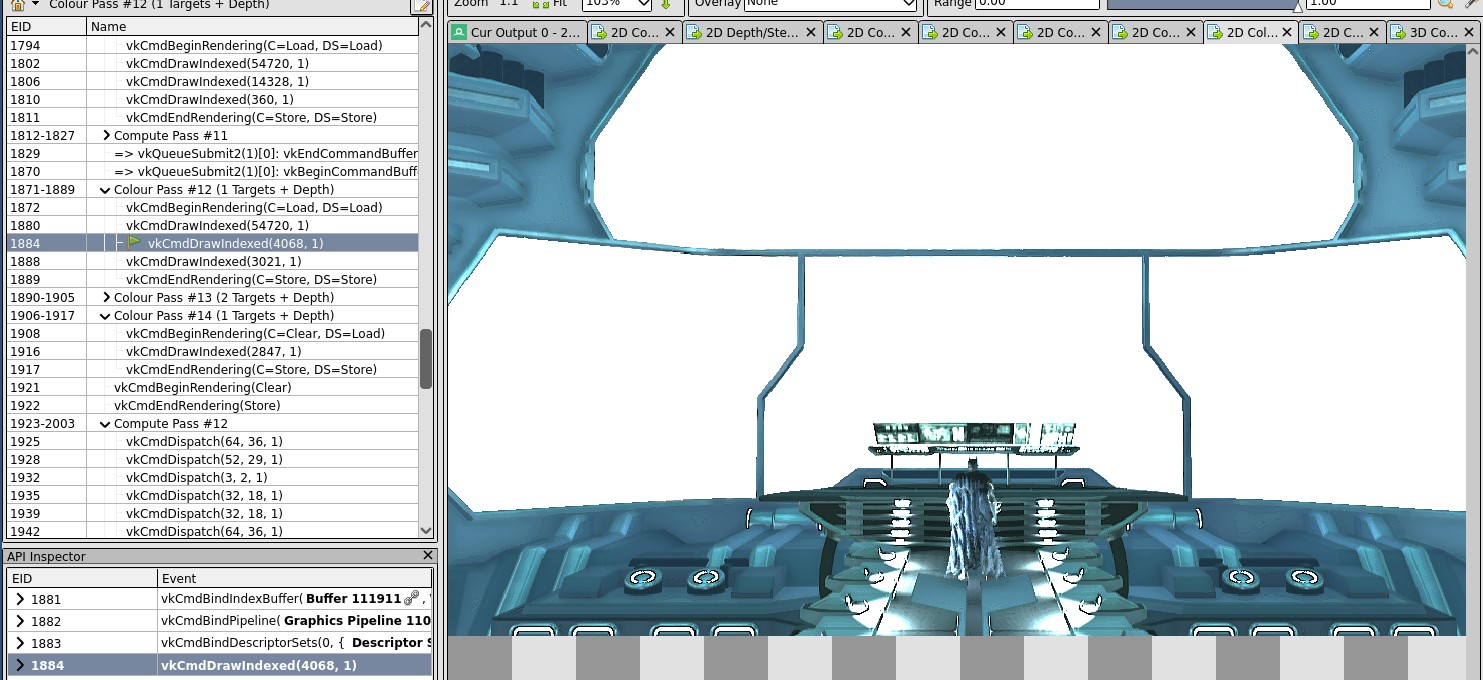
How it should look:
The draw call inputs and state look good enough. So it’s time to bisect the shader.
Here is the output of the reduced shader on Turnip:

Enabling the display of NaNs and Infs shows that there are NaNs in the output on Turnip (NaNs have green color here):

While the correct rendering on RADV is:
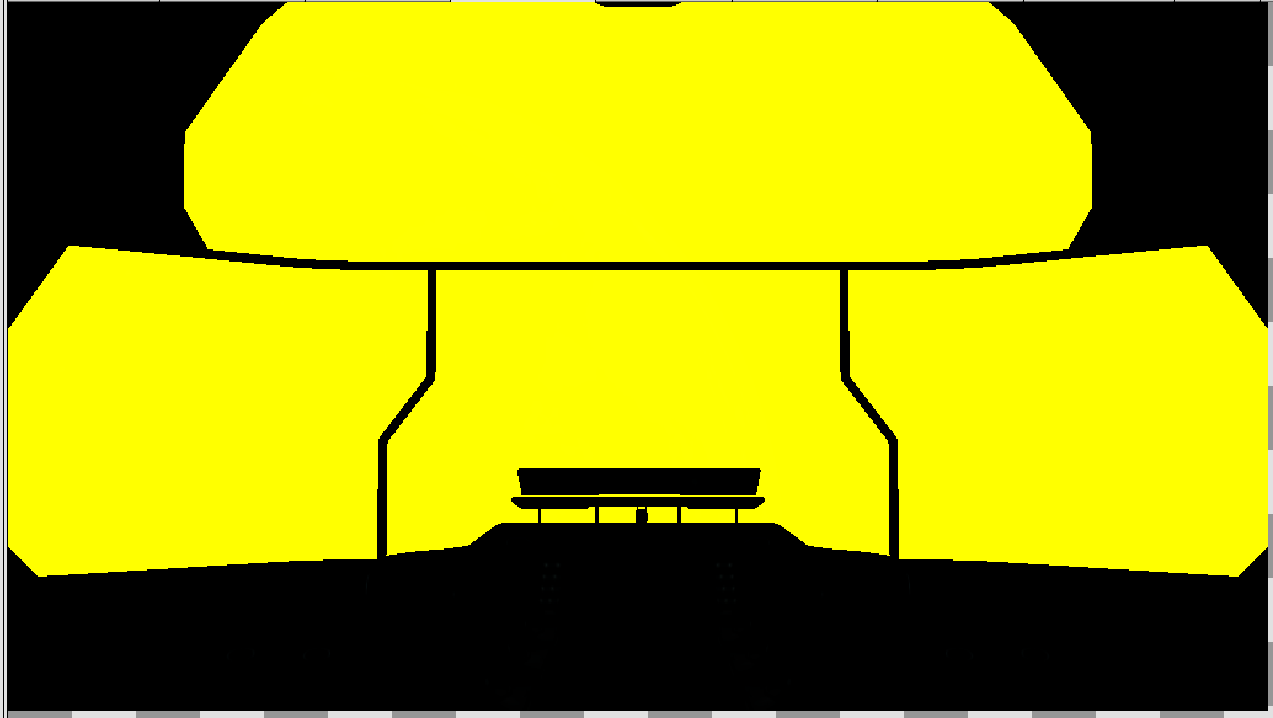
Carefully reducing the shader further resulted in the following fragment which reproduces the issue:
r12 = uintBitsToFloat(uvec4(texelFetch(t34, _1195 + 0).x, texelFetch(t34, _1195 + 1).x, texelFetch(t34, _1195 + 2).x, texelFetch(t34, _1195 + 3).x));
....
vec4 _1268 = r12;
_1268.w = uintBitsToFloat(floatBitsToUint(r12.w) & 65535u);
_1275.w = unpackHalf2x16(floatBitsToUint(r12.w)).x;
On Turnip this _1275.w is NaN, while on RADV it is a proper number. Looking at assembly, the calculation of _1275.w from the above is translated into:
isaml.base0 (u16)(x)hr2.z, r0.w, r0.y, s#0, t#12
(sy)cov.f16f32 r1.z, hr2.z
In GLSL there is a read of uint32, stripping it of the high 16 bits, then converting the lower 16 bits to a half float.
In assembly the “read and strip the high 16 bits” part is done in a single command isaml, where the stripping is done via (u16) conversion.
At this point I wrote a simple reproducer to speed up iteration on the issue:
result = uint(unpackHalf2x16(texelFetch(t34, 0).x & 65535u).x);
After testing different values I confirmed that (u16) conversion doesn’t strip higher 16 bits, but clamps the value to 16 bit unsigned integer. Running the reproducer on the proprietary driver shown that it doesn’t fold u32 -> u16 conversion into isaml.
Knowing that the fix is easy: ir3: Do 16b tex dst folding only for floats
Monster Hunter: World
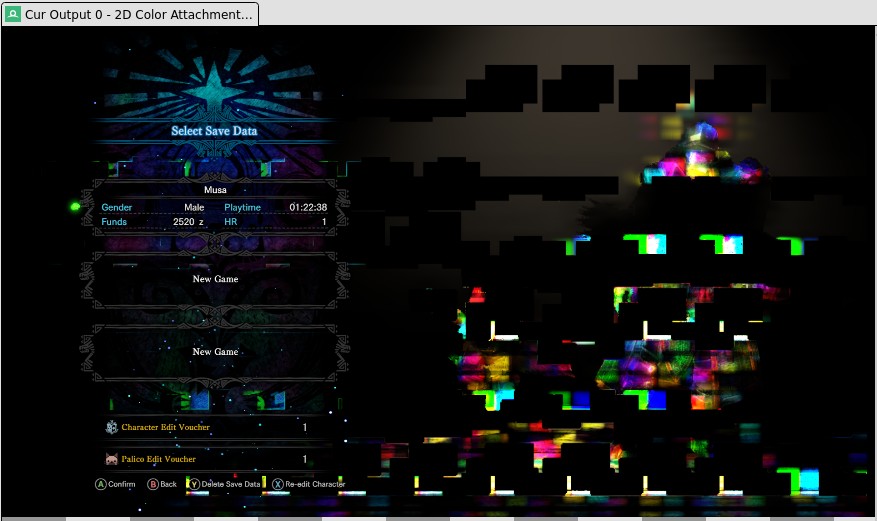
Main menu, again =) Before we even got here two other issues were fixed before, including the one which seems like an HW bug which proprietary driver is not aware of.
In this case of misrendering the culprit is a compute shader.
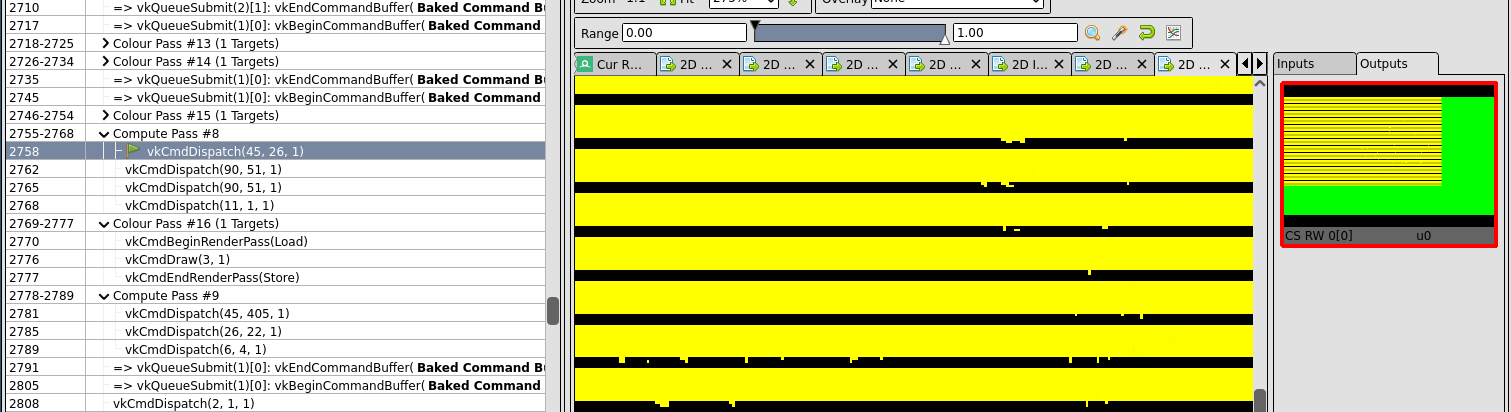
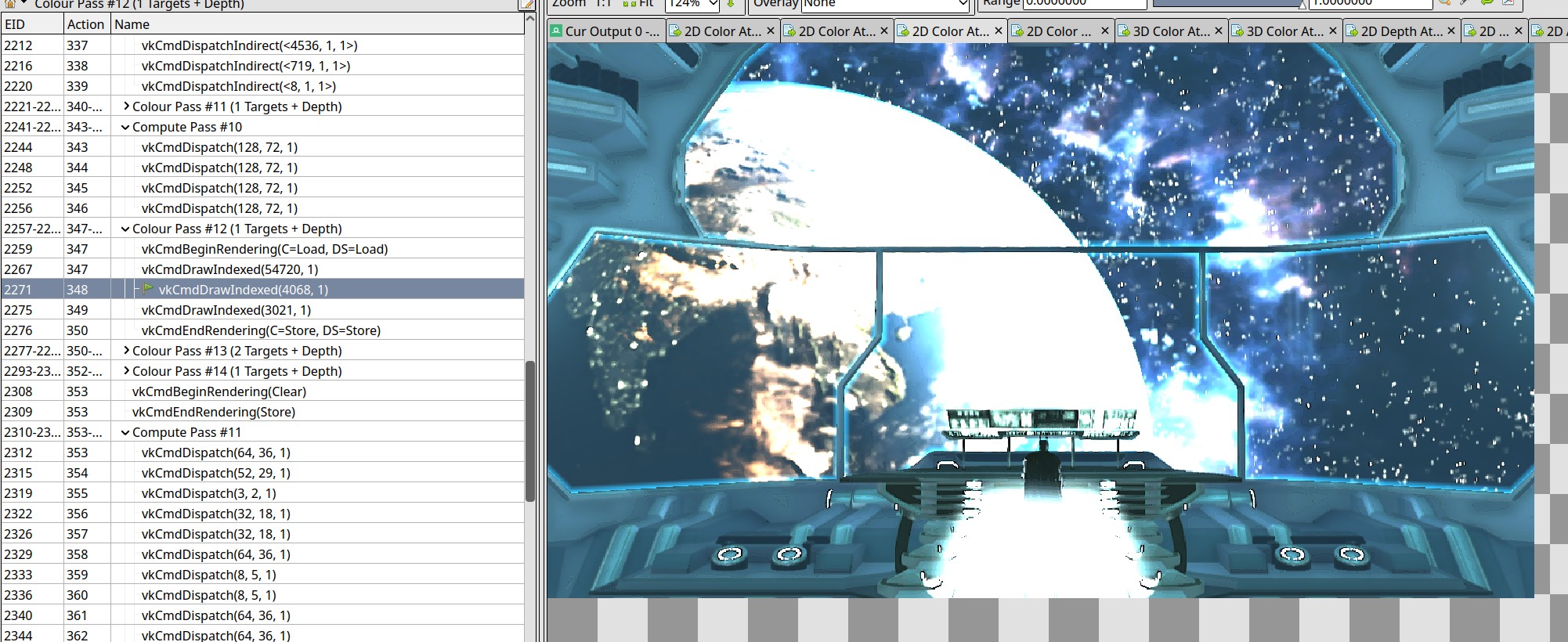
How it should look:
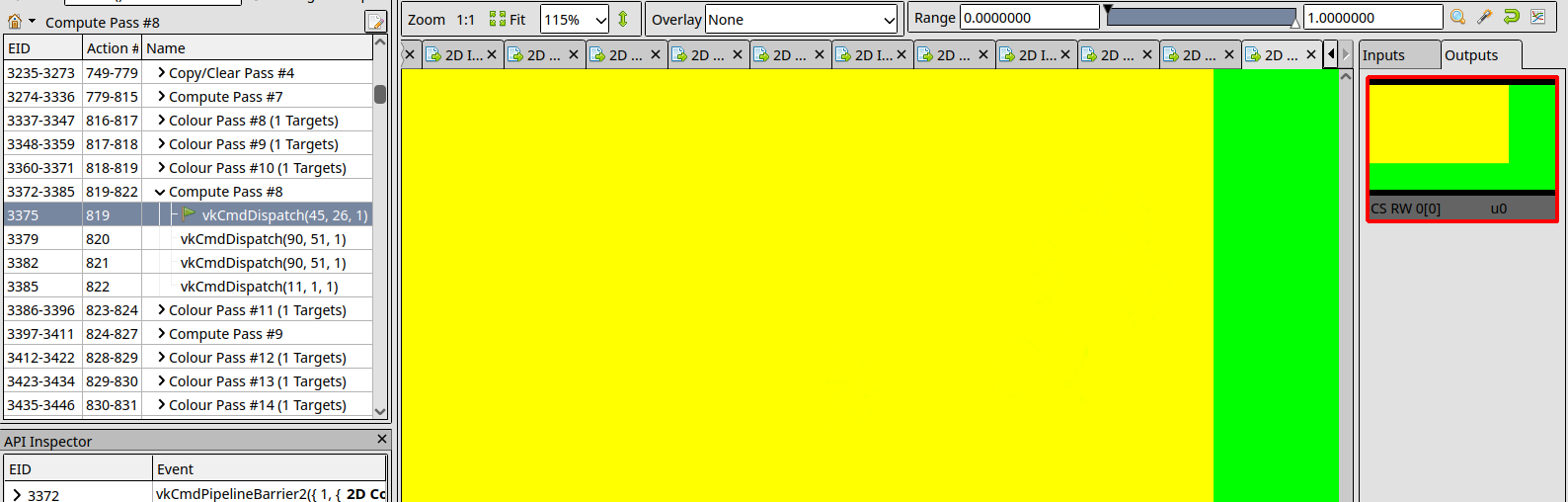
Compute shader are generally easier to deal with since much less state is involved.
None of debug options helped and shader printf didn’t work at that time for some reason. So I decided to look at the shader assembly trying to spot something funny.
ldl.u32 r6.w, l[r6.z-4016], 1
ldl.u32 r7.x, l[r6.z-4012], 1
ldl.u32 r7.y, l[r6.z-4032], 1
ldl.u32 r7.z, l[r6.z-4028], 1
ldl.u32 r0.z, l[r6.z-4024], 1
ldl.u32 r2.z, l[r6.z-4020], 1
Negative offsets into shared memory are not suspicious at all. Were they always there? How does it look right before being passed into our backend compiler?
vec1 32 ssa_206 = intrinsic load_shared (ssa_138) (base=4176, align_mul=4, align_offset=0)
vec1 32 ssa_207 = intrinsic load_shared (ssa_138) (base=4180, align_mul=4, align_offset=0)
vec1 32 ssa_208 = intrinsic load_shared (ssa_138) (base=4160, align_mul=4, align_offset=0)
vec1 32 ssa_209 = intrinsic load_shared (ssa_138) (base=4164, align_mul=4, align_offset=0)
vec1 32 ssa_210 = intrinsic load_shared (ssa_138) (base=4168, align_mul=4, align_offset=0)
vec1 32 ssa_211 = intrinsic load_shared (ssa_138) (base=4172, align_mul=4, align_offset=0)
vec1 32 ssa_212 = intrinsic load_shared (ssa_138) (base=4192, align_mul=4, align_offset=0)
Nope, no negative offsets, just a number of offsets close to 4096. Looks like offsets got wrapped around!
Looking at ldl definition it has 13 bits for the offset:
<pattern pos="0" >1</pattern>
<field low="1" high="13" name="OFF" type="offset"/> <--- This is the offset field
<field low="14" high="21" name="SRC" type="#reg-gpr"/>
<pattern pos="22" >x</pattern>
<pattern pos="23" >1</pattern>
With offset type being a signed integer (so the one bit is for the sign). Which leaves us with 12 bits, meaning the upper bound of 4095. Case closed!
I know that there is a upper bound set on offset during optimizations, but where and how it is set?
The upper bound is set via nir_opt_offsets_options::shared_max and is equal to (1 << 13) - 1, which we saw is incorrect. Who set it?
Subject: [PATCH] ir3: Limit the maximum imm offset in nir_opt_offset for
shared vars
STL/LDL have 13 bits to store imm offset.
Fixes crash in CS compilation in Monster Hunter World.
Fixes: b024102d7c2959451bfef323432beaa4dca4dd88
("freedreno/ir3: Use nir_opt_offset for removing constant adds for shared vars.")
Signed-off-by: Danylo Piliaiev
Part-of: <https://gitlab.freedesktop.org/mesa/mesa/-/merge_requests/14968>
---
src/freedreno/ir3/ir3_nir.c | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
@@ -124,7 +124,7 @@ ir3_optimize_loop(struct ir3_compiler *compiler, nir_shader *s)
*/
.uniform_max = (1 << 9) - 1,
- .shared_max = ~0,
+ .shared_max = (1 << 13) - 1,
Weeeell, totally unexpected, it was me! Fixing the same game, maybe even the same shader…
Let’s set the shared_max to a correct value . . . . . Nothing changed, not even the assembly. The same incorrect offset is still there.
After a bit of wandering around the optimization pass, it was found that in one case the upper bound is not enforced correctly. Fixing it fixed the rendering.
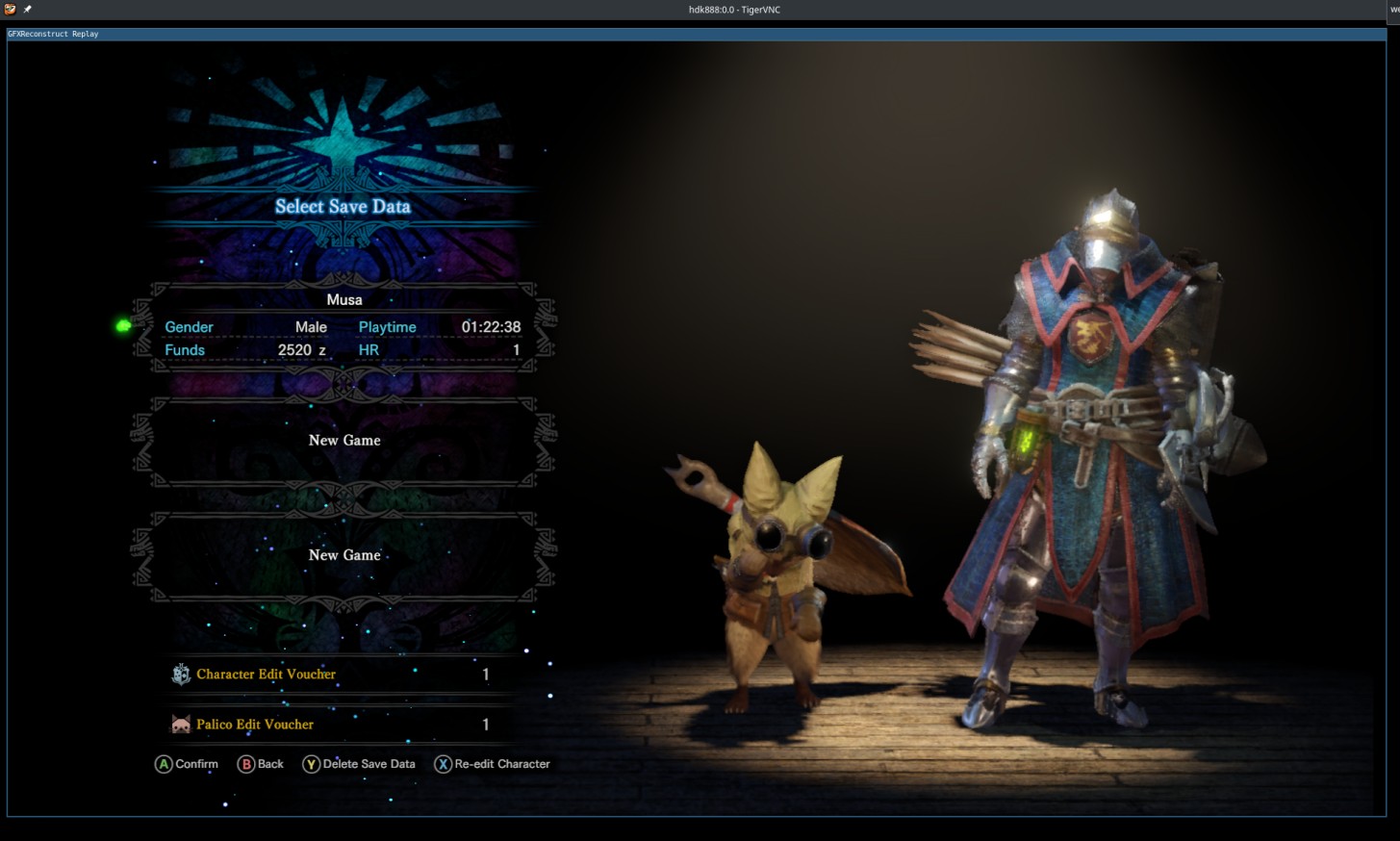
The final changes were:
Comments