Freedreno now supports OpenGL 3.3 on A6XX
I recently joined Igalia and as a way to familiarize myself with Adreno GPUs it was decided to get Freedreno up to OpenGL 3.3.
Just recently, Freedreno exposed only OpenGL 3.0. The big jump in version required only two small extensions and a few fixes to get rid of most crashes in Piglit since almost all features were already supported.
ARB_blend_func_extended
I decided to start with dual-source-blending. Fittingly, it was the cause of the first issue I investigated in Mesa two and a half years ago =)
Turnip already had it implemented so it was a good first task. Most of the time was spent getting myself familiarized with Freedreno and squashing the hangs that happened due to the lack of experience with this driver. And shortly I have a working MR
freedreno/a6xx: add support for dual-source blending (!7708)
However, Freedreno didn’t have Piglit tests running on CI and I missed the failure of arb_blend_func_extended-fbo-extended-blend-pattern_gles2 test. I did test the _gles3 version though. Thus the issue with gles2 was not found immediately.
What’s different in the gles2 test? It uses gl_SecondaryFragColorEXT for the second color of dual-source blending. gl_FragColor and gl_SecondaryFragColorEXT are different from the other ways to specify color in that they broadcast the color to all enabled draw buffers. In Mesa they both translated to slot FRAG_RESULT_COLOR, which in Freedreno didn’t expect the second source for blending. The solution was simple, if a shader has a dual-source blending - remap FRAG_RESULT_COLOR to FRAG_RESULT_DATA0 + dual_src_index.
freedreno/ir3: remap FRAG_RESULT_COLOR to _DATA* for dual-src blending (!8245)
While looking at how other drivers handle FRAG_RESULT_COLOR I saw that Zink also has a similar issue but in a NIR lowering path, so I fixed it too since it was simple enough.
nir/lower_fragcolor: handle dual source blending (!8247)
ARB_shader_stencil_export
While implementing ARB_blend_func_extended I saw in Turnip that RB_FS_OUTPUT_CNTL0 also could enable stencil export:
tu_cs_emit_pkt4(cs, REG_A6XX_RB_FS_OUTPUT_CNTL0, 2);
tu_cs_emit(cs, COND(fs->writes_pos, A6XX_RB_FS_OUTPUT_CNTL0_FRAG_WRITES_Z) |
COND(fs->writes_smask, A6XX_RB_FS_OUTPUT_CNTL0_FRAG_WRITES_SAMPMASK) |
COND(fs->writes_stencilref, A6XX_RB_FS_OUTPUT_CNTL0_FRAG_WRITES_STENCILREF) |
COND(dual_src_blend, A6XX_RB_FS_OUTPUT_CNTL0_DUAL_COLOR_IN_ENABLE));
Meanwhile, in Freedreno there was just a cryptic 0xfc000000:
OUT_PKT4(ring, REG_A6XX_SP_FS_OUTPUT_CNTL0, 1);
OUT_RING(ring, A6XX_SP_FS_OUTPUT_CNTL0_DEPTH_REGID(posz_regid) |
A6XX_SP_FS_OUTPUT_CNTL0_SAMPMASK_REGID(smask_regid) |
COND(fs_has_dual_src_color,
A6XX_SP_FS_OUTPUT_CNTL0_DUAL_COLOR_IN_ENABLE) |
0xfc000000);
Which I was quickly told to be a shifted register r63.x, which has a value of 0xfc and is used to signify an unused value.
Again, Turnip already supported stencil export and compiler had it wired up; it’s hard to have a simpler extension to implement.
freedreno/a6xx: add support for ARB_shader_stencil_export (!7810)
Running tests for GL 3.1 - 3.3
After enabling ARB_blend_func_extended and ARB_shader_stencil_export Freedreno had everything for a jump to GL 3.3. It was a time to run tests.
KHR-GL31.texture_size_promotion.functional
First observation was that the test passes with FD_MESA_DEBUG=nogmem, next I compared traces with and without nogmem and saw the difference in a texture layout (I should have just printed the layouts with FD_MESA_DEBUG=layout). It didn’t give me an answer, so I checked whether I could bisect the failure. To my delight it was bisectable
freedreno: reduce extra height alignment in a6xx layout (e4974852)
The change is only one line of code and without the context first thing which comes to mind is that maybe the alignment is wrong:
if (level == mip_levels - 1)
- nblocksy = align(nblocksy, 32);
+ height = align(nblocksy, 4);
uint32_t nblocksx =
But it’s even more trivial, nblocksy was erroneously changed to height, and height just wasn’t used afterwards which hid the issue. Thus it was fixed in
freedreno/a6xx: Fix typo in height alignment calculation in a6xx layout (!7792)
gl-3.2-layered-rendering-clear-color-all-types 2d_multisample_array single_level
It was quickly found that clearing a framebuffer in Freedreno didn’t take into account that framebuffer could have several layers, so only the first one was cleared.
Initially, I thought that we would need a number_of_layers draw calls to clear all layers, but looking at a generic blitter in gallium suggested a better answer - instanced draw where each instance draw a fullscreen quad into a distinct layer. Which could be accomplished just by:
gl_Layer = gl_InstanceID;
in the vertex shader. However, this required the support of GL_AMD_vertex_shader_layer which Freedreno didn’t have…
Implementing GL_AMD_vertex_shader_layer
Fortunately, Turnip again had it implemented. As with stencil export it was just a matter of finding a register of VARYING_SLOT_LAYER and plugging it into respective control structure.
freedreno/a6xx: add support for gl_Layer in vertex shader
Simple enough? Yes! However, it failed the only tests available for the extension:
amd_vertex_shader_layer-layered-2d-texture-render // Fails
amd_vertex_shader_layer-layered-depth-texture-render // Crashes
The crash when clearing a depth texture is a known one, but why 2d-texture-render fails? Let’s look at the output:

First layer and its mipmaps are cleared, but on other layers most mipmaps are not! Mipmaps are nowhere near gl_Layer, so it seams that the implementation is indeed correct, however the single test we expected to pass - fails. Which is bad because we don’t have other tests to test gl_Layer.
Fixing amd_vertex_shader_layer-layered-2d-texture-render
A good starting point is always to check whether one of FD_MESA_DEBUG options helps. In this case noubwc changed the result of the test to:
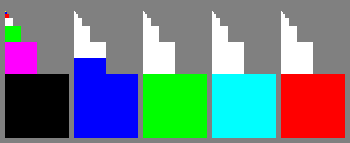
Not by a lot but still a lead. Something wrong with image layouts…
I searched for similar tests for Vulkan and found them in vktDrawShaderLayerTests.cpp, the tests passed on Turnip which told me that most likely the issue is not in the common code of layout calculations. After some hacking of the tests I made one close enough to amd_vertex_shader_layer-layered-2d-texture-render. However, directly comparing traces between GL and Vulkan isn’t productive. So I decided to see what changes with different mip levels in Freedreno and Turnip separately.
So I did make 4 tests:
- GL with clearing level 1
- GL with clearing level 2
- VK drawing to level 1
- VK drawing to level 2
With that comparing “GL level 1”” with “GL level 2” and “VK level 1”” with “VK level 2” yielded just a few differences. For GL the only difference which could had been relevant was:
Level 1:
RB_MRT[0].ARRAY_PITCH: 8192
Level 2:
RB_MRT[0].ARRAY_PITCH: 4096
However in VK this value didn’t change, there was no difference in traces barring window/scissor/blit sizes!
RB_MRT[0].ARRAY_PITCH: 45056
In VK it was just a constant 45056 regardless of mip level. Hardcoding the value in Freedreno fixed the test. After that it was a matter of comparing how the field is calculated for Turnip and Freedreno resulting in:
freedreno/a6xx: fix array pitch for layer-first layouts
The layered clear
With the above changes the layered clear was simple enough:
freedreno/a6xx: support layered framebuffers in blitter_clear
gl-3.2-minmax or bumping the maximum count of varyings
Before, Freedreno supported only 16 vec4 varyings or 64 components between shader stages. GL3.2 on the other hand mandates the minimum of 128 components. After a couple of trivial fixes - I thought it would be easy, but Marek Olšák pointed out that I didn’t cover all cases with my tests. And of course one of them, the passing of varyings between VS and TCS, hanged the GPU.
I ran a few tests only changing the varyings count and observed that GPU hanged starting from 17 vec4. By comparing the traces I didn’t find anything suspicious in shaders, so I decided to check a few states that depended on varyings count. After poking a few of them I found that setting SP_HS_UNKNOWN_A831 above 64 resulted in a guaranteed hang.
In Turnip SP_HS_UNKNOWN_A831 had a special case for A650 which made me a bit suspicious. However, using A650’s formula for A630 didn’t change anything. It was time to see what blob driver does, so I wrote a script to iterate from 1 to 32 vec4, push test on device, run it, copy trace back, extract A831 value and append to a csv. Here is the result:
| vec4 count | A831 (Hex) | A831 (Dec) | PC_HS_INPUT_SIZE |
|---|---|---|---|
| 1 | 0x10 | 16 | 0xc |
| 2 | 0x14 | 20 | 0xf |
| 3 | 0x18 | 24 | 0x12 |
| 4 | 0x1c | 28 | 0x15 |
| 5 | 0x20 | 32 | 0x18 |
| 6 | 0x24 | 36 | 0x1b |
| 7 | 0x28 | 40 | 0x1e |
| 8 | 0x2c | 44 | 0x21 |
| 9 | 0x30 | 48 | 0x24 |
| 10 | 0x34 | 52 | 0x27 |
| 11 | 0x38 | 56 | 0x2a |
| 12 | 0x3c | 60 | 0x2d |
| 13 | 0x3f | 63 | 0x30 |
| 14 | 0x40 | 64 | 0x33 |
| 15 | 0x3d | 61 | 0x36 |
| 16 | 0x3d | 61 | 0x39 |
| 17 | 0x40 | 64 | 0x3c |
| 18 | 0x3f | 63 | 0x3f |
| 19 | 0x3e | 62 | 0x42 |
| 20 | 0x3d | 61 | 0x45 |
| 21 | 0x3f | 63 | 0x48 |
| 22 | 0x3d | 61 | 0x4b |
| 23 | 0x40 | 64 | 0x4e |
| 24 | 0x3d | 61 | 0x51 |
| 25 | 0x3f | 63 | 0x54 |
| 26 | 0x3c | 60 | 0x57 |
| 27 | 0x3e | 62 | 0x5a |
| 28 | 0x40 | 64 | 0x5d |
| 29 | 0x3c | 60 | 0x60 |
| 30 | 0x3e | 62 | 0x63 |
| 31 | 0x40 | 64 | 0x66 |
So A831 is indeed capped at 64 and after the first time A831 reaches 64, the relation ceases to be linear. Ugh…
Without having any good ideas I posted the results on Gitlab asking Jonathan Marek, who added a special case for A650 some time ago, for help. The previous A650 formula was:
prims_per_wave = wavesize // tcs_vertices_out
total_size = output_size * patch_control_points * prims_per_wave
unknown_a831 = DIV_ROUND_UP(total_size, wavesize)
After looking at the table above Jonathan Marek suggested the following formula:
prims_per_wave = wavesize // tcs_vertices_out
while True:
total_size = output_size * patch_control_points * prims_per_wave
unknown_a831 = DIV_ROUND_UP(total_size, wavesize)
if unknown_a831 <= 0x40:
break
prims_per_wave -= 1
And it worked! What does the new formula mean is that there is A831 * wavesize available space per wave for varyings; the more varyings we use in a shader the less threads the wave will have. For TCS we use wave size of 64 so the total size available would be
64 (wave size) * 64 (max A831) * 4 = 16k
freedreno/a6xx: bump varyings limit (!7917)
Bumping OpenGL support to 3.3
There still was a considerable amount of Piglit failures but they were either already known or not so important to prevent the the version increase. Which was done in
freedreno: Enable GLSL 3.30, updating us to GL 3.3 contexts (!8270)
Comments