Improvements to RISC-V vector code generation in LLVM
Earlier this month, Alex presented "Improvements to RISC-V vector code generation in LLVM" at the RISC-V Summit Europe in Paris. This blog post summarises that talk.

Introduction #
So RISC-V, vectorisation, the complexities of the LLVM toolchain and just 15 minutes to cover it in front of an audience with varying specialisations. I was a little worried when first scoping this talk but the thing with compiler optimisations is that the objective is often pretty clear and easy to understand, even if the implementation can be challenging. I'm going to be exploiting that heavily in this talk by trying to focus on the high level objective and problems encountered.
RVV codegen development #

Where are we today in terms of the implementation of optimisation of RISC-V vector codegen? I'm oversimplifying the state of affairs here, but the list in the slide above isn't a bad mental model. Basic enablement is done, it's been validated to the point it's enabled by default, we've had a round of additional extension implementation, and a large portion of ongoing work is on performance analysis and tuning. I don't think I'll be surprising any of you if I say this is a huge task. We're never going to be "finished" in the sense that there's always more compiler performance tuning to be done, but there's certainly phases of catching the more obvious cases and then more of a long tail.
Improving RVV code generation #

What is the compiler trying to do here? There are multiple metrics, but typically we're focused primarily on performance of generated code. This isn't something we do at all costs -- in a general purpose compiler you can't for instance spend 10hrs optimising a particular input. So we need a lot of heuristics that help us arrive at a reasonable answer without exhaustively testing all possibilities.
The kind of considerations for the compiler during compilation includes:
- Profitability. If you're transforming your code then for sure you want the new version to perform better than the old one! Given the complexity of the transformations from scalar to vector code and costs incurred by moving values between scalar and vector registers, it can be harder than you might think to figure out at the right time whether the vector route vs the scalar route might be better. You're typically estimating the cost of either choice before you've gone and actually applied a bunch of additional optimisations and transformations that might further alter the trade-off.
- More specific to RISC-V vectors, it's been described before as effectively
being a wider than 32-bit instruction width but with the excess encoded in
control status registers. If you're too naive about it, you risk switching
the
vtypeCSR more than necessary, adding unwanted overhead. - Spilling is when we load and store values to the stack. Minimising this is a standard objective for any target, but the lack of callee saved vector registers in the standard ABI poses a challenge, and this is more subtle but the fact we don't have immediate offsets for some vector instructions can put more pressure on scalar register allocation.
- Or otherwise just ensuring that we're using the instructions available whenever we can. One of the questions I had was whether I'm going to be talking just about autovectorisation, or vector codegen where it's explicit in the input (e.g. vector datatypes, intrinsics). I'd make the point they're not fully independent, in fact all these kind of considerations are inter-related. If the compiler is doing cost modelling that's telling it vectorisation isn't profitable. Sometimes that's true, sometimes the model isn't detailed enough, or sometimes it's true for the compiler right now because it could be doing a better job of choosing instructions. If I solve the issue of suboptimal instruction selection then it benefits both autovectorisation (as it's more likely to be profitable, or will be more profitable) and potentially the more explicit path (as explicit uses of vectors benefit from the improved lowering).
Just one final point of order I'll say once to avoid repeating myself again and again. I'm giving a summary of improvements made by all LLVM contributors across many companies, rather than just those by my colleagues at Igalia.
Non-power-of-two vectorization #

The intuition behind both this improvement and the one on the next slide is actually exactly the same. Cast your minds back to 2015 or so when Krste was presenting the vector extension. Some details have changed, but if you look at the slides (or any RVV summary since then) you see code examples with simple minimal loops even for irregularly sized vectors or where the length of a vector isn't fixed at compile time. The headline is that the compiler now generates output that looks a lot more like that handwritten code that better exploits the features of RISC-V vector.
For non-power-of-two vectorisation, I'm talking about the case here where you
have a fixed known-at-compile time length. In LLVM this is handled usually by
what we call the SLP or Superword Level Parallelism
vectorizer. It needed
to be taught to handle non-power-of-two sizes like we support in RVV. Other
SIMD ISAs don't have the notion of vl and so generating non-power-of-two
vector types isn't as easy.

The example I show here has pixels with rgb values. Before it would do a very narrow two-wide vector operation then handle the one remaining item with scalar code. Now we directly operate on a 3-element vector.
We are of course using simple code examples for illustration here. If you want to brighten an image as efficiently as possible sticking the per-pixel operation in a separate function like this perhaps isn't how you'd do it!
vl tail folding #

Often when operating on a loop, you have an input of a certain length and you process it in chunks of some reasonable size. RISC-V vector gives us a lot more flexibility about doing this. If our input vector isn't an exact multiple of our vectorization factor ("chunk size") - which is the calculated vector length used per iteration - we can still process that in RVV using the same vector code path. While for other architectures, as you see with the old code has a vector loop, then may branch to a scalar version for the tail for any remainder elements. Now that's not necessary, LLVM's loop vectorizer can handle these cases properly and we get a single vectorised loop body. This results in performance improvements on benchmarks like x264 where the scalar tail is executed frequently, and improves code size even in cases where there is no direct performance impact.

libcall expansion #

This one is a little bit simpler. It's common for the compiler to synthesise
its own version of memcpy/memset when it sees it can generate a more
specialised version based on information about alignment or size of the
operands. Of course when the vector extension is available the compiler
should be able to use it to implement these operations, and now it can.

This example shows how a small number of instructions expanded inline might be used to implement memcpy and memcmp. I also note there is a RISC-V vector specific consideration in favour of inlining operations in this case - as the standard calling convention doesn't have any callee-saved vector registers, avoiding the function call may avoid spilling vector registers.
Newer RVV extensions #

Sometimes of course it's a matter of a new extension letting us do something we couldn't before. We need to teach the compiler how to select instructions in that case, and to estimate the cost. Half precision and bf16 floating point is an interesting example where you introduce a small number of instructions for the values of that type, but otherwise rely on widening to 32-bit. This is of course better than falling back to a libcall or scalarising to use Zfh instruction, but someone needs to be put in the work to convince the compiler of that!

Other improvements #

The slide above has a sampling of other improvements. If you'd like to know more about the VL optimizer, my colleague's presentation at EuroLLVM earlier this year is now up on YouTube.
Another fun highlight is llvm-exegesis, this is a tool for detecting microarchitectural implementation details via probing, e.g. latency and throughput of different operations that will help you write a scheduling model. It now supports RVV which is a bit helpful for the one piece of RVV 1.0 hardware we have readily available, but should be a lot more helpful once more hardware reaches the market.
Results #
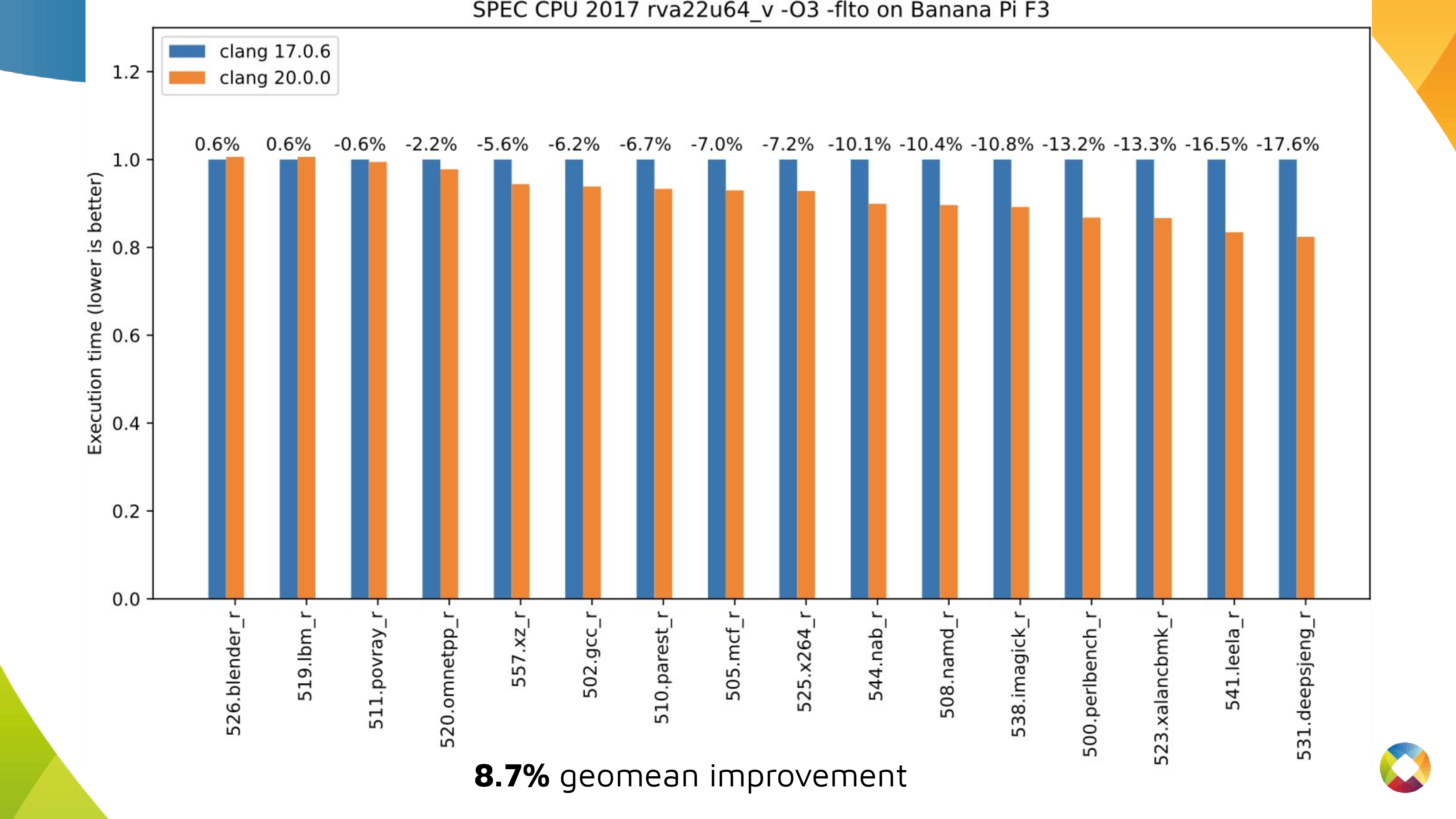
So, it's time to show the numbers. Here I'm looking at execution time for SPEC CPU 2017 benchmarks (run using LLVM's harness) on at SpacemiT X60 and compiled with the options mentioned above. As you can see, 12 out of 16 benchmarks improved by 5% or more, 7 out of 16 by 10% or more. These are meaningful improvements a bit under 9% geomean when compared to Clang as of March this year to Clang from 18 months prior.
There's more work going in as we speak, such as the optimisation work done by my colleague Mikhail and written up on the RISE blog. Benchmarking done for that work comparing Clang vs GCC showed today's LLVM is faster than GCC in 11 of the 16 tested SPEC benchmarks, slower in 3, and about equal for the other two.
Are we done? Goodness no! But we're making great progress. As I say for all of these presentations, even if you're not directly contributing compiler engineering resources I really appreciate anyone able to contribute by reporting any cases when they compiler their code of interest and don't get the optimisation expected. The more you can break it down and produce minimised examples the better, and it means us compiler engineers can spend more time writing compiler patches rather than doing workload analysis to figure out the next priority.
Testing #

Adding all these new optimisations is great, but we want to make sure the generated code works and continues to work as these new code generation features are iterated on. It's been really important to have CI coverage for some of these new features including when they're behind flags and not enabled by default. Thank you to RISE for supporting my work here, we have a nice dashboard providing an easy view of just the RISC-V builders.
Future work #

Here's some directions of potential future work or areas we're already looking. Regarding the default scheduling model, Mikhail's recent work on the Spacemit X60 scheduling model shows how having at least a basic scheduling model can have a big impact (partly as various code paths are pessimised in LLVM if you don't at least have something). Other backends like AArch64 pick a reasonable in-order core design on the basis that scheduling helps a lot for such designs, and it's not harmful for more aggressive OoO designs.
Thank you #

To underline again, I've walked through progress made by a whole community of contributors not just Igalia. That includes at least the companies mentioned above, but more as well. I really see upstream LLVM as a success story for cross-company collaboration within the RISC-V ecosystem. For sure it could be better, there are companies doing a lot with RISC-V who aren't doing much with the compiler they rely on, but a huge amount has been achieved by a contributor community that spans many RISC-V vendors. If you're working on the RISC-V backend downstream and looking to participate in the upstream community, we run biweekly contributor calls (details on the RISC-V category on LLVM's Discourse that may be a helpful way to get started.
Thank you for reading!