Thanks to eye/o’s great support, Igalia has solved several problems while prototyping :has() on the Chromium project. In this post, I would like to take a closer look at the :has() test performance, one of the two problems shared in the previous posts.
Let’s test a :has() pseudo class
The relational pseudo class :has() is one of the simple selectors. As spec describes, a simple selector represents a single condition on an element.
In many cases, the condition can be checked within the element being tested, so we don’t need any other elements to test a simple selector on an element. When we test a class selector on an element, we can get the test result by checking whether the element has a certain class value or not.
But testing a :has() pseudo class is far more complex than testing a class selector. We need to check more elements and their relationships in order to test :has().
<div id="subject">
<div id="div1">
<div id="div2" class="a"></div>
</div>
<div id="div3"></div>
</div>
<div id="div4" class="c"></div>
#subject:has(.something) matches on the #subject element only if there is an element that has the class value something, and the element is a descendant of #subject. Therefore:
#subject:has(.a)matches the#subjectelement because,- there is an element
#div2that has the class valuea, - and the
#div2is a descendant of the#subject.
- there is an element
#subject:has(.b)doesn’t match the#subjectelement because,- there is no element that has the class value
b.
- there is no element that has the class value
#subject:has(.c)doesn’t match the#subjectelement because,- there is an element
#div4that has the class valuec, - but the
#div4is not a descendant of the#subject.
- there is an element
To test the :has() pseudo class on an element, we need to check these two conditions.
- The existence of an element matching the
:has()argument selector. - The relationship between the element matching the argument and the element being tested.
Where can we find the argument matched elements?
To check the two conditions, we need to find an element that matches the argument selector. To find the argument matched element, we need to traverse the DOM tree and test the argument selector on the elements in the traversal range.
The number of elements in the traversal range directly affects the :has() performance. Therefore, it is important to reduce the traversal range.
We don’t need to check whether a :has() argument selector matches an element or not if the element doesn’t satisfy the relationship condition. To skip checking those elements, we can reduce the traversal range. In the previous example, we don’t need to check the class value of #div4 because it is not a descendant of the #subject.
:has(.c)doesn’t match the#subjectelement because,- none of the descendant elements of
#subjecthave the class valuec.
- none of the descendant elements of
The relationship condition is affected by the combinators in the :has() argument selector. To get the appropriate traversal range, we need to understand how to test the :has() argument selector on an element and how the combinators in the :has() argument selector specify which elements to test on.
How to test the :has() argument selector on an element?
The :has() pseudo class takes a relative selector list as an argument and the relative selector starts with a combinator, as shown in its grammar.
<relative-selector> = <combinator>? <complex-selector>
Based on the combinator definition in Selectors Level 4, the leftmost <combinator> in the <relative-selector> should also have a <compound-selector> on its left side to represent the relationship between two elements. But the <relative-selector> grammar doesn’t have a <compound-selector> in its left side.
To handle this inconsistency, the spec allows for the <relative-selector> to omit the <compound-selector> on the left side of the leftmost combinator by providing a concept of absolutizing a relative selector. When the compound selector on the left side of the leftmost combinator is omitted, before testing the argument selector, we need to prepend :scope as the initial compound selector to represent the element to be tested with the :has() pseudo class.
There is some ambiguity about using the :scope for absolutizing the relative selector. To prevent some confusion, instead of using :scope, :has-scope will be used for absolutizing in this post. The :has-scope indicates the element to be tested with the :has() pseudo class.
The argument selector of :has(.a) will be absolutized to :has-scope .a. The absolutized argument selector represents these two conditions.
- the argument selector matches an element with the class value
a - the argument selector matches a descendant of the element to be tested with the
:has()pseudo class.
<div id="subject">
<div id="div1">
<div id="div2" class="a"></div>
</div>
<div id="div3"></div>
</div>
<div id="div4" class="a"></div>
While testing the :has(.a) on #subject, we will test the absolutized argument selector :has-scope .a on some elements.
- When we test the argument selector on
#div2, it will match because#div2has the class valueaand it is a descendant of the#subject. - When we test the argument selector on
#div4, it will not match even if#div4has the class valueabecause the element is not a descendant of the#subject.
How the combinators in argument specify which elements to test on?
Every selector is tested from the right to the left. When we test the selector .a .b on an element, we first test the rightmost compound .b on the element, and test the next compound .a on the ancestors of the element. The descendant combinator between the two compound selectors tells us the traversal direction, so we traverse in the opposite direction of the combinator when testing a selector.
This is same for the absolutized argument selector. When we test the absolutized argument selector :has-scope .a on an element, we first test the rightmost compound .a on the element, and test the next compound :has-scope on the ancestors of the element. When the :has-scope is true on an ancestor, then the absolutized argument selector matches the element.
But we can use the combinator direction differently in a different context. Before testing the absolutized argument selector, we need to determine the traversal range from which to get the elements to be tested. At this point, we can use the direction of the combinators in the argument selector as it is, because we are at the :has-scope matched element in the :has() pseudo class testing context.
<div id="subject">
<div id="div1">
<div id="div2" class="a"></div>
</div>
<div id="div3"></div>
</div>
<div id="div4" class="a"></div>
When we test the :has(.a) on #subject, we are already at the #subject element and the element matches the :has-scope of the absolutized argument selector. From the absolutized argument selector :has-scope .a, we can expect that the subject of the argument selector will be a descendant of the #subject element because of the descendant combinator in the argument selector. So we can skip the #div4 by traversing to the descendants of the #subject for testing the argument selector.
How can we categorize the argument testing traversal?
There are 4 combinators that are distinguished by the directionality and adjacency of the relationship.
| Combinator | Directionality | Adjacency |
|---|---|---|
Descendant combinator ( ) |
descendant | non-adjacent |
Child combinator (>) |
descendant | adjacent |
Next-sibling combinator (+) |
next sibling | adjacent |
Subsequent-sibling combinator (~) |
next sibling | non-adjacent |
Due to the directionality of the combinators, the subject of the :has() argument selector is always one of these elements.
- a descendant of the subject of the
:has()pseudo class - a next sibling of the subject of the
:has()pseudo class - a descendant of a next sibling of the subject of the
:has()pseudo class
Considering the adjacency of the combinators, the argument testing traversal ranges can be classified into these 8 types.
- All descendants of the
:has-scopeelement
(e.g.:has(.a),:has(> .a .b),:has(.a ~ .b), …) - Descendants(at a certain depth) of the
:has-scopeelement
(e.g.:has(> .a),:has(> .a > .b),:has(> .a ~ .b), …) - All next siblings of the
:has-scopeelement
(e.g.:has(~ .a),:has(+ .a ~ .b), …) - One next sibling(at a certain sibling distance) of the
:has-scopeelement
(e.g.:has(+ .a),:has(+ .a + .b), …) - All descendants of a next sibling(at a certain sibling distance) of the
:has-scopeelement
(e.g.:has(+ .a .b),:has(+ .a + .b .c),:has(+ .a .b ~ .c), …) - Descendants(at a certain depth) of a next sibling(at a certain sibling distance) of the
:has-scopeelement
(e.g.:has(+ .a > .b),:has(+ .a + .b > .c),:has(+ .a > .b ~ .c), …) - All descendants of all next siblings of the
:has-scopeelement
(e.g.:has(~ .a .b),:has(+ .a ~ .b .c),:has(~ .a > .b .c), …) - Descendants(at a certain depth) of all next siblings of the
:has-scopeelement
(e.g.:has(~ .a > .b),:has(+ .a ~ .b > .c),:has(~ .a > .b ~ .c), …)
:has() can still make things slower
We can reduce many unnecessary :has() argument selector testing operations by applying those 8 types of traversal ranges. But still there are number of elements in the traversal ranges. The :has() pseudo class is a comuptationally heavier operation than testing other simple selectors that only requires one element.
subject.matches(':has(.a)')can be $O(n)$ where $n$ is the number of descendants of the#subject.
Within a single :has() pseudo class testing on an element, there can be multiple argument testing traversal caused by using multiple argument selectors. This can increase the processing time of some operations that require selector matching such as selector query, style matching and style invalidation.
subject.matches(':has(.a1, .a2, ..., .am)')can be $O(nm)$ where $n$ is the number of the descendants of#subjectand $m$ is the number of the argument selectors.
So basically, :has() has two inputs that can increase the processing time linearly.
- number of elements in the document.
- number of
:has()argument selectors.
By reducing the input size, we can improve the performance of the :has(). (There are multiple ways to do this, and those will be covered by another post.)
But even if the inputs are fixed, the :has() pseudo class can easily increase the complexity of some operations because one :has() pseudo class can be tested on multiple elements within a single operation.
document.querySelectorAll(':has(.a)')can be about $O(n \log(n))$ where $n$ is the number of elements in the document.document.querySelectorAll(':has(.a) .b')can be $O(n^2)$ where $n$ is the number of elements in the document.
These overheads are caused by repetitive argument selector testing on the same element within a single operation. So, we needed to find a way to remove the unnecessary argument selector testing operations.
How to avoid the redundancy? Caching
When we test one :has() pseudo class on multiple elements, we have the same number of argument selector testing traversal ranges, and some of those traversal ranges can be a subset of the other traversal ranges. If this happens within a single operation, it increases the number of argument selector tests.
<div id="main">
<div id="div1" class="subject">
<div id="div2"></div>
<div id="div3" class="subject">
<div id="div4"></div>
<div id="div5" class="a"></div>
<div id="div6"></div>
</div>
<div id="div7"></div>
</div>
</div>
<script>
div1.matches(':has(.a)');
// Needed to traverse #div2 ~ #div7
// for testing ':has-scope .a'.
div3.matches(':has(.a)');
// Needed to traverse #div4 ~ #div6
// for testing ':has-scope .a'.
main.querySelectorAll('.subject:has(.a)');
// Needed to traverse #div2 ~ #div7 for testing
// ':has(.a)' on #div1,
// but need to traverse #div4 ~ #div6 again for
// testing ':has(.a)' on #div3.
// Tested `:has-scope .a` twice on #div4 ~ #div6.
</script>
While processing the main.querySelectorAll('.subject:has(.a)'), we can skip the repetive argument selector testing on #div4 ~ #div6 if we don’t need to test the :has(.a) on #div3. We can simply consider to have a cache that stores the :has(.a) test result on the elements. If we can get the :has(.a) test result on #div3 from the cache, we don’t need to traverse #div4 ~ #div6 to test the argument selector on them. We can skip the :has() argument testing traversal for an element if the cache contains the :has() pseudo class testing result on the element.
But needing to do that means we have to ask this question: “How can we get the testing result of an element before testing?”
Where is the subject of :has()?
To test a :has() pseudo class on an element, we need to test its argument selector on the elements in the traversal range. If the argument selector matches at least one element in the traversal range, then the :has() pseudo class matches the element and we can call the element as a subject element of the :has() pseudo class.
Due to the directions of CSS combinators, subjects of the :has() are always one of these elements which is at the upward direction of the argument selector matched element:
- An ancestor of the argument selector matched element.
- A previous sibling of the argument selector matched element.
- A previous sibling of an ancestor of the argument selector matched element.
<div class="sibling"> <!-- '.sibling:has(~ .parent .a)' matched -->
</div>
<div class="parent"> <!-- '.parent:has(.a)' matched -->
<div class="sibling"> <!-- '.sibling:has(~ .a)' matched -->
</div>
<div class="a"> <!-- argument matched -->
</div>
</div>
In other words, when we have a :has() argument matched element, there can be a subject element of the :has() pseudo class that is an ancestor (or previous sibling or previous sibling of ancestor) of the argument matched element.
The subject element of the :has() pseudo class can be cached as having MATCHED status for later use. By using this cached status, we can skip extra traversals.
What happens while testing :has() argument?
To test a :has() pseudo class on an element, we need to test the :has() argument selector on the elements in the traversal range. The interesting point is that, while testing the :has() argument selector, we can get candidate subject elements of the :has() pseudo class.
<div id="subject">
<div id="div1">
<div id="div2">
<div id="div3" class="a"></div>
</div>
</div>
</div>
To test :has(.a) on #subject, we need to test the argument selctor :has-scope .a on the all descendants of the #subject. We test the argument selector on the #div3 by following these steps.
- Test
.aon#div3=>true- Test
:has-scopeon#div2=>false - Test
:has-scopeon#div1=>false - Test
:has-scopeon#subject=>true
- Test
While testing the argument selector on the #div3, the :has-scope is tested on the 3 elements (#div2, #div1, #subject), and the test is true only on the #subject element. But the :has-scope can be true on the other two elements when we test the :has(.a) on those elements. So, those two elements are also subjects of the :has(.a). Although we are in the context of testing :has(.a) on #subject, we can get the test result of :has(.a) on the other two elements (#div1, #div2). After testing :has(.a) on #subject, we can cache #subject, #div1 and #div2 as having MATCHED status.
We can get the candidate :has() subject even in cases where the argument selector doesn’t end up matching any of the elements in the traversal range.
<div id="nonsubject"></div>
<div id="div1"></div>
<div id="div2">
<div id="div3"></div>
<div id="div4"></div>
<div id="div5" class="a">
<div id="div6"></div>
<div id="div7">
<div id="div8" class="b"></div>
</div>
</div>
</div>
In the context of testing :has(~ .a .b) on #nonsubject, we test the argument selector :has-scope ~ .a .b on #div8 by following these steps.
- Test
.bon#div8=>true- Test
.aon#div7=>false - Test
.aon#div5=>true- Test
:has-scopeon#div4=>false - Test
:has-scopeon#div3=>false
- Test
- Test
.aon#div2=>false
- Test
Testing :has(~ .a .b) on #nonsubject fails because the argument selector :has-scope ~ .a .b doesn’t match any elements in the traversal scope. But while testing the argument on the #div8, we can get two candidate subject elements of :has(~ .a .b).
Whatever the result of :has() test, we can cache all the elements tested for :has-scope as having MATCHED status.
How to walk subtree to use the MATCHED status in the cache?
Usually browsers follow the DOM tree order that is a pre-order, depth-first traversal of a tree. The style engine walks the tree in that order for resolving and computing styles. querySelector() or querySelectorAll() also walk the descendants of an element in the order to test the selector.
DOM tree order walks the tree downward (from the top to the bottom).
<div> <!-- DOM tree order: 1 -->
<div> <!-- DOM tree order: 2 -->
<div> <!-- DOM tree order: 3 -->
<div></div> <!-- DOM tree order: 4 -->
</div>
<div></div> <!-- DOM tree order: 5 -->
<div> <!-- DOM tree order: 6 -->
<div></div> <!-- DOM tree order: 7 -->
</div>
</div>
<div> <!-- DOM tree order: 8 -->
<div> <!-- DOM tree order: 9 -->
<div></div> <!-- DOM tree order: 10 -->
</div>
</div>
</div>
But in terms of using the MATCHED elements in the cache, walking the DOM tree order in reverse (from the bottom to the top) is better than the usual DOM tree order.
Using the DOM tree order cannot take the full advantage of caching the MATCHED status because the argument testing traversal will stop when it finds the first element that matches the argument selector.
Any element cached as MATCHED will be always at the upward of the argument matched element. So, the more elements are at the upward of the first argument matched element, the more candidates we can have.
<div id="main">
<div id="div1">
<div id="div2">
<div id="div3" class="a">
<div id="div4">
<div id="div5" class="a">
<div id="div6"></div>
</div>
</div>
</div>
</div>
</div>
</div>
We can see this in the context of testing :has(.a) on #div1. When we follow the DOM tree order, we can cache 2 elements.
- test
.aon#div2=>false - test
.aon#div3=>true- cache
#div2asMATCHED
and test:has-scopeon#div2=>false - cache
#div1asMATCHED
and test:has-scopeon#div1=>true
- cache
But when we follow the reversed DOM tree order, we can cache 4 elements.
- test
.aon#div6=>false - test
.aon#div5=>true- cache
#div4asMATCHED
and test:has-scopeon#div4=>false - cache
#div3asMATCHED
and test:has-scopeon#div3=>false - cache
#div2asMATCHED
and test:has-scopeon#div2=>false - cache
#div1asMATCHED
and test:has-scopeon#div1=>true
- cache
This can make a big difference when we test :has(.a) on multiple elements in a single operation.
<script>
main.querySelectorAll(':has(.a)')
</script>
In the above case, the querySelectorAll() tries to test :has(.a) on #div1 ~ #div6. While testing :has(.a) on #div1, we can cache two more elements (#div3 and #div4 in addition to #div1 and #div2) when we follow the reversed DOM tree order. After #div1 is tested, we can skip the traversal of following argument test on the elements previously cached as MATCHED.
- test
:has(.a)on#div1- test
:has-scope .aon [#div6,#div5,#div4,#div3,#div2 - cache as
MATCHED: [#div4,#div3,#div2,#div1]
- test
- test
:has(.a)on#div2testget result from cache:has-scope .aon [#div6,#div5,#div4,#div3]
- test
:has(.a)on#div3testget result from cache:has-scope .aon [#div6,#div5,#div4]
- test
:has(.a)on#div4testget result from cache:has-scope .aon [#div6,#div5]
- test
:has(.a)on#div5- test
:has-scope .aon [#div6]
- test
- test
:has(.a)on#div6- test
:has-scope .aon []
- test
However, we will only get this benefit if we have the MATCHED candidates within the traversal range. In practice, the candidates will be rare. Most elements in the traversal range will not be matched, and those not-matched elements will increase complexity by creating its own traversal ranges.
To get the same benefit for NOT_MATCHED status, we need to cache the NOT_MATCHED element before testing the :has() on the element.
So, we have to ask essentially the same question again: “How can we know whether an element is not matched before testing?”
How to cache NOT_MATCHED status?
We can determine whether a :has() pseudo class didn’t match to an element only when these two conditions are satisfied:
- Finished to test the
:has()argument selector on the all elements in the traversal range. - The argument selector didn’t match any of the elements in the traversal range.
In case of testing a :has() pseudo class on two different elements #a, #b and the argument testing traversal range for #a is a superset of the argument testing traversal range for #b, we can get the :has() pseudo class test result for #b while testing :has() pseudo class on #a.
If #b is a subject element of the :has() pseudo class, we can cache the element as MATCHED by following the approach already described previously. But even if #b is not a subject element of the :has() pseudo class, there still can be other ways to get the test result while testing #a, because the traversal range for #a is a superset of the traversal range for #b.
If following conditions are satisfied, we can determine whether the :has() pseudo class didn’t matched to #b while testing the :has() argument on the traversal range for #a. So, if these are satisfied, #b can be cached as having NOT_MATCHED status:
- Finished testing the
:has()argument selector on all the elements in the traversal range for#b. - The argument selector didn’t match any of the elements in the traversal range for
#b.
How to get NOT_MATCHED candidates while matching argument?
For the following 4 of the 8 traversal types, we can get the NOT_MATCHED candidates in a traversal range while matching :has() argument on the elements in the range.
- All descendants of
:has-scope - All next siblings of
:has-scope - All descendants of a next sibling of
:has-scope - All descendants of all next siblings of
:has-scope
These 4 types guarantee that an argument testing traversal range for an element #a is always a subset of the other argument testing traversal range if the other traversal range contains the element #a. And due to the direction of the combinators, the argument testing traversal range for #a is always at a downward position of #a (descendant of #a, next sibling of #a, descendant of next sibling of #a)
<div id="div1">
<div id="div11">
<div id="div111" class="a"></div>
<div id="div112"></div>
</div>
</div>
<div id="div2" class="b">
<div id="div21"></div>
<div id="div22" class="b">
<div id="div221" class="c"></div>
<div id="div222"></div>
</div>
</div>
<div id="div3" class="d">
<div id="div31"></div>
<div id="div32"></div>
<div id="div33" class="d">
<div id="div331"></div>
<div id="div332" class="e"></div>
</div>
</div>
<div id="div4"></div>
- test
:has(.a)- on
#div1: test the argument on [#div11,#div111,#div112] - on
#div11: test the argument on [#div111,#div112]
- on
- test
:has(~ .b)- on
#div1: test the argument on [#div2,#div3,#div4] - on
#div2: test the argument on [#div3,#div4]
- on
- test
:has(+ .b .c)- on
#div1: test the argument on [#div21,#div22,#div221,#div222] - on
#div21: test the argument on [#div221,#div222]
- on
- test
':has(~ .d .e)- on
#div1: test the argument on [#div21,#div22,#div221,#div222,#div31,#div32,#div33,#div331,#div332] - on
#div31: test the argument on [#div331,#div332]
- on
And following two approaches helps to determine whether an element in a traversal range satisfies the two condition for NOT_MATCHED status:
- Caching all
MATCHEDcandidate elements while testing argument selector. - Following reversed DOM tree order (from bottom to top) to test argument selector.
When we are at an element in the middle of a reversed DOM tree order traversal, it guarantees that the argument testing traversal range of the element was already tested with the argument selector. If the element is a MATCHED candidate, it must be already cached because all the MATCHED candidate elements will be cached while testing the argument on its traversal range.
So, if it is not cached as MATCHED, we can cache it as a NOT_MATCHED candidate.
<div id="main">
<div id="div1">
<div id="div2">
<div id="div3" class="a">
<div id="div4">
<div id="div5" class="a">
<div id="div6"></div>
</div>
</div>
</div>
</div>
</div>
</div>
Now we can cache the missing two elements (#div5 and #div6) as NOT_MATCHED in the previous example of testing :has(.a) on #div1,
- cache
#div6asNOT_MATCHED
and test.ato#div6=>false - cache
#div5asNOT_MATCHED
and test.ato#div5=>true- cache
#div4asMATCHED
and test:has-scopeto#div4=>false - cache
#div3asMATCHED
and test:has-scopeto#div3=>false - cache
#div2asMATCHED
and test:has-scopeto#div2=>false - cache
#div1asMATCHED
and test:has-scopeto#div1=>true
- cache
and the main.querySelectorAll(':has(.a)') can be close to $O(n)$ because it doesn’t have any repetitive argument selector testing.
- test
:has(.a)on#div1- test
:has-scope .aon [#div6,#div5,#div4,#div3,#div2 - cache as
NOT_MATCHED: [#div6,#div5] - cache as
MATCHED: [#div4,#div3,#div2,#div1]
- test
- test
:has(.a)on#div2testget result from cache:has-scope .aon [#div6,#div5,#div4,#div3]
- test
:has(.a)on#div3testget result from cache:has-scope .aon [#div6,#div5,#div4]
- test
:has(.a)on#div4testget result from cache:has-scope .aon [#div6,#div5]
- test
:has(.a)on#div5testget result from cache:has-scope .aon [#div6]
- test
:has(.a)on#div6testget result from cache:has-scope .aon []
This works well with more complex trees.
<div id=main>
<div id="div1">
<div id="div11">
<div id="div111"></div>
</div>
<div id="div12">
<div id="div121"></div>
<div id="div122" class="a">
<div id="div1221"></div>
</div>
</div>
<div id="div13">
<div id="div131"></div>
</div>
</div>
<div id="div2">
<div id="div21" class="a">
<div id="div211"></div>
</div>
<div id="div22"></div>
</div>
</div>
<script>
main.querySelectorAll(':has(.a)');
</script>
- test
:has(.a)on#div1- test
:has-scope .aon [#div131,#div13,#div1221,#div122,#div121,#div12,#div111,#div11 - cache as
NOT_MATCHED: [#div131,#div13,#div1221,#div122] - cache as
MATCHED: [#div12,#div1]
- test
- test
:has(.a)on#div11- test
:has-scope .aon [#div111] - cache as
NOT_MATCHED: [#div111,#div11]
- test
- test
:has(.a)on#div111testget result from cache:has-scope .aon []
- test
:has(.a)on#div12testget result from cache:has-scope .aon [#div1221,#div122,#div121]
- test
:has(.a)on#div121- test
:has-scope .aon [] - cache as
NOT_MATCHED: [#div121]
- test
- test
:has(.a)on#div122testget result from cache:has-scope .aon [#div1221]
- test
:has(.a)on#div1221testget result from cache:has-scope .aon []
- test
:has(.a)on#div13testget result from cache:has-scope .aon [#div131]
- test
:has(.a)on#div131testget result from cache:has-scope .aon []
- test
:has(.a)on#div2- test
:has-scope .aon [#div22,#div211,#div21] - cache as
NOT_MATCHED: [#div22,#div211,#div21] - cache as
MATCHED: [#div2]
- test
- test
:has(.a)on#div21testget result from cache:has-scope .aon [#div211]
- test
:has(.a)on#div211testget result from cache:has-scope .aon []
- test
:has(.a)on#div22testget result from cache:has-scope .aon []
Too many NOT_MATCHED elements in cache!
The above approaches were already considered and merged with the initial :has() CL many months ago, but from the start, there was a serious concern about cache memory consumption because it caches the :has() test result of every element in the traversal range. The problem was recently addressed by another CL.
Usually most elements in the subtree will be NOT_MATCHED status. If a :has() pseudo class has no matches, then all the elements in the argument testing traversal range will be cached as NOT_MATCHED.
<!-- :has(.a) :has(.b) -->
<div id="subject"> <!-- MATCHED NOT_MATCHED -->
<div id="div1"> <!-- - NOT_MATCHED -->
<div id="div11"></div> <!-- - NOT_MATCHED -->
</div>
<div id="div2"> <!-- MATCHED NOT_MATCHED -->
<div id="div21"></div> <!-- - NOT_MATCHED -->
<div id="div22" class="a"><!-- NOT_MATCHED NOT_MATCHED -->
<div id="div221"></div> <!-- NOT_MATCHED NOT_MATCHED -->
</div>
<div id="div23"> <!-- NOT_MATCHED NOT_MATCHED -->
<div id="div231"></div> <!-- NOT_MATCHED NOT_MATCHED -->
</div>
</div>
<div id="div3"> <!-- NOT_MATCHED NOT_MATCHED -->
<div id="div31"></div> <!-- NOT_MATCHED NOT_MATCHED -->
</div>
<div id="div4"> <!-- NOT_MATCHED NOT_MATCHED -->
<div id="div41"></div> <!-- NOT_MATCHED NOT_MATCHED -->
</div>
</div>
<script>
subject.match(':has(.a, .b)');
</script>
The problem is that, while testing the argument selector, whenever we meet an element that is not cached as MATCHED, we cache the element as NOT_MATCHED to indicate that the element is a NOT_MATCHED candidate.
Instead of marking each traversed element as a NOT_MATCHED candidate, we can mark the traversed element range as CHECKED with a relatively small number of cache entries.
For the above case, instead of marking every traversed element as NOT_MATCHED, we can mark some of the traversed elements with these 3 flags:
CHECKED: the element was already traversed to be checked.ALL_DOWNWARD_CHECKED: all descendants, all next siblings, and all next sibling subtrees of the element were already traversed to be checked.SOME_CHILDREN_CHECKED: some of the children of the element were already traversed to be checked.
We can mark the last traversed element and its ancestor’s next sibling element as either CHECKED or ALL_DOWNWARD_CHECKED so that we can skip caching the descendants of those elements. And we can mark the parent of the last traversed element’s ancestors as SOME_CHILDREN_CHECKED so that we can skip caching all next siblings and all next sibling subtrees of the elements marked as ALL_DOWNWARD_CHECKED.
By following this approach, we can reduce many cache entries for NOT_MATCHED status.
<div id="subject"> <!--MATCHED | SOME_CHILDREN_CHECKED-->
<div id="div1"> <!-- - -->
<div id="div11"></div> <!-- - -->
</div>
<div id="div2"> <!--MATCHED | SOME_CHILDREN_CHECKED-->
<div id="div21"></div> <!-- - -->
<div id="div22" class="a"><!--CHECKED | ALL_DOWNWARD_CHECKED -->
<div id="div221"></div> <!-- - -->
</div>
<div id="div23"> <!-- - -->
<div id="div231"></div> <!-- - -->
</div>
</div>
<div id="div3"> <!--CHECKED | ALL_DOWNWARD_CHECKED -->
<div id="div31"></div> <!-- - -->
</div>
<div id="div4"> <!-- - -->
<div id="div41"></div> <!-- - -->
</div>
</div>
<script>
subject.match(':has(.a)');
</script>
We can reduce even more cache entries when the :has() doesn’t match.
<div id="subject"> <!--CHECKED | SOME_CHILDREN_CHECKED-->
<div id="div1"> <!--CHECKED | ALL_DOWNWARD_CHECKED -->
<div id="div11"></div> <!-- - -->
</div>
<div id="div2"> <!-- - -->
<div id="div21"></div> <!-- - -->
<div id="div22" class="a"><!-- - -->
<div id="div221"></div> <!-- - -->
</div>
<div id="div23"> <!-- - -->
<div id="div231"></div> <!-- - -->
</div>
</div>
<div id="div3"> <!-- - -->
<div id="div31"></div> <!-- - -->
</div>
<div id="div4"> <!-- - -->
<div id="div41"></div> <!-- - -->
</div>
</div>
<script>
document.querySelectorAll(':has(.b)');
</script>
When we meet an element that is not cached, we can determine whether the element is already checked by checking ancestors or its previous siblings with the ALL_DOWNWARD_CHECKED flag set. If there is an element with the flag set, the not-cached element is actually not-matched because it was already checked in the previous traversal and not cached as MATCHED.
So, we can skip the repetitive argument selector tests with the reduced cache entries.
The space complexity of the cache for a single :has() pseudo class can be $O(m\log(n))$ where $m$ is the number of the subject elements of :has() pseudo class and $n$ is the number of elements in the document (because we can store 2 cache entries for every depth of the subtree of the :has subject elements). But the memory consumption is much lower in practice (close to $O(\log(n))$) because there are small number of :has() subject elements.
(You can get more details and test cases in the CL)
Is it OK with the additional cache lookup?
This approach produces additional cache entry lookup overhead for each element being tested for :has() pseudo class. The overhead can be close to $O(n \log(n))$ because we need to check ancestors and ancestors’ previous siblings of each element. But it is not the dominant overhead because the tree is usually not that deep and the cache lookup is usually very fast.
This test page shows it : selector-testing-performance.html (results)
The following test results are the processing time of matches(.a:has(.b)) and querySelectorAll(.a:has(.b)) on an element with n number of descendants. The performance of both JavaScript API call scales similar to $O(n)$.
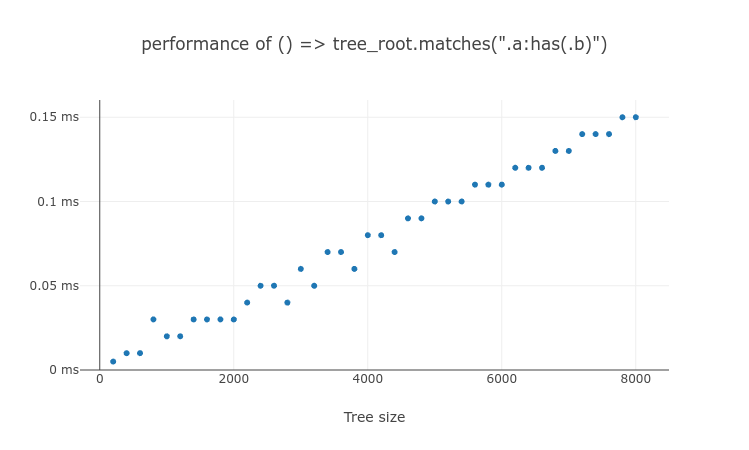
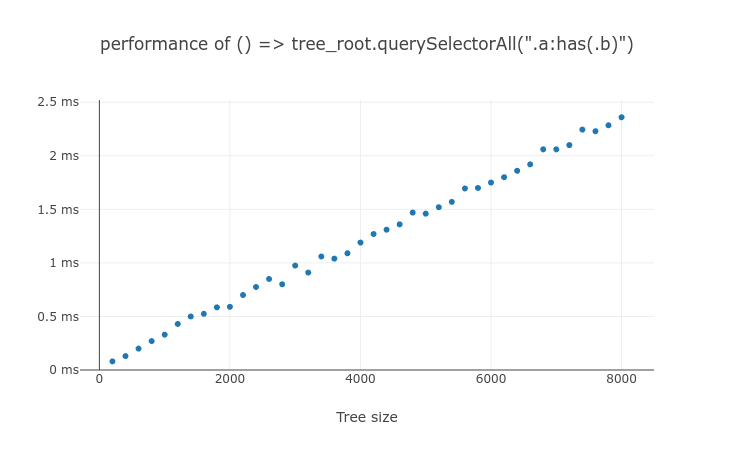
How does the cache perform for non-subject :has()?
The caching approach doesn’t work well for non-subject :has(). If a :has() pseudo class is in a non-subject compound position of a selector, the :has() argument selector can be tested multiple times on a given element because the :has() pseudo class can be tested multiple times from the bottom to the top (from descendant to ancestor or from next sibling to previous sibling).
<div id="div1">
<div id="div2" class="b"></div>
<div id="div3">
<div id="div4"></div>
<div id="div5">
<div id="div6"></div>
<div id=subject class="a"></div>
</div>
</div>
</div>
Testing :has(.b) .a on #subject produces repetitive argument testing operations.
- Test
.aon#subject=>true- Test
:has(.a)on#div5=>false
Argument testing traversal : [#subject,#div6]
Cache asNOT_MATCHED: [#subject,#div6,#div5] - Test
:has(.a)on#div3=>false
Argument testing traversal : [#subject,#div6,#div5,#div4]
Cache asNOT_MATCHED: [#subject,#div6,#div5,#div4,#div3] - Test
:has(.a)on#div1=>true
Argument testing traversal : [#subject,#div6,#div5,#div4,#div3,#div2]
Cache asNOT_MATCHED: [#subject,#div6,#div5,#div4,#div3,#div2]
Cache asMATCHED: [#div1]
- Test
:has() need to be tested on the every ancestors of #subject, so testing :has(.b) .a takes more time than testing .a:has(.b). But the tree height grows usually slower than tree size, so the performance of :has(.b) .a scales similar to $O(n)$. In practice, we can limit the number of non-subject :has() tests within a single selector test by adding compound condition. (e.g. .c:has(.b) .a)
We can check this in these 3 results from the same test page previously shared.
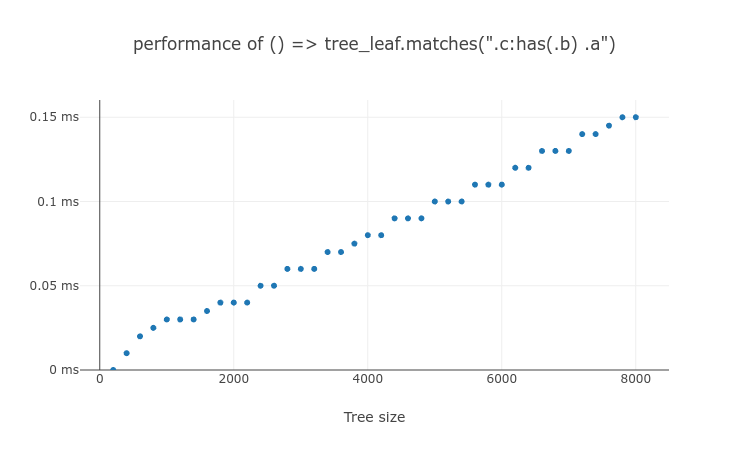
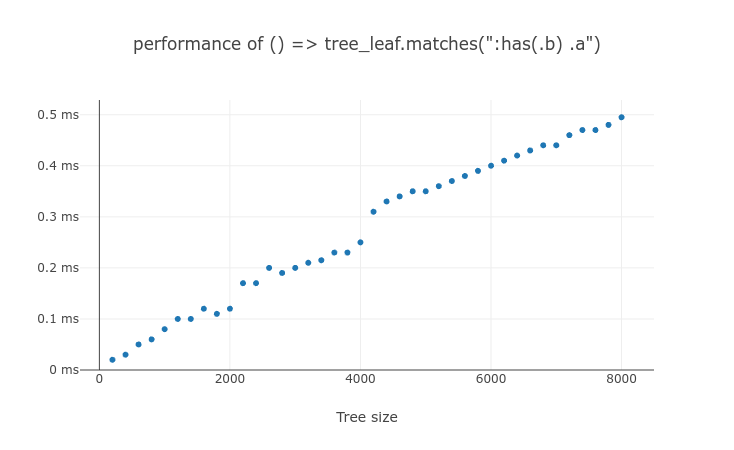
Even if in the extreme case of testing the non-subject :has() on every ancestor, querySelectorAll() processing time scales close to $O(n)$. There will not be any more repetitive argument selector tests after the non-subject :has() was tested on the top-most element. But due to the cache lookup overhead for every ancestor of each element, it will be slightly slower than $O(n)$. And still, we can make it better by adding compound condition.
These 2 test results from the same test page show it.
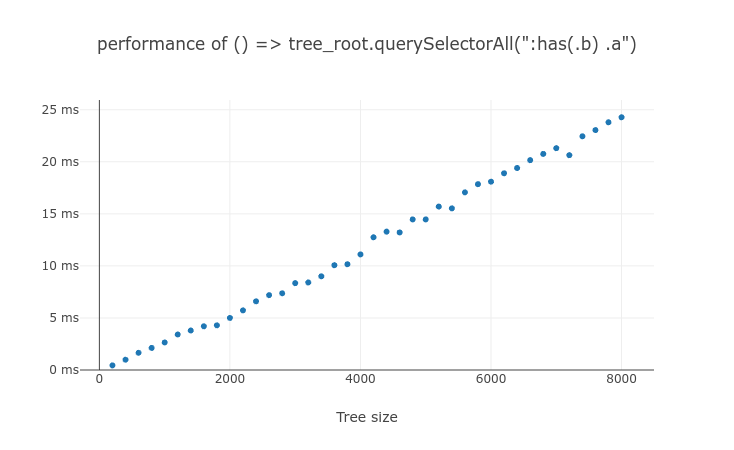
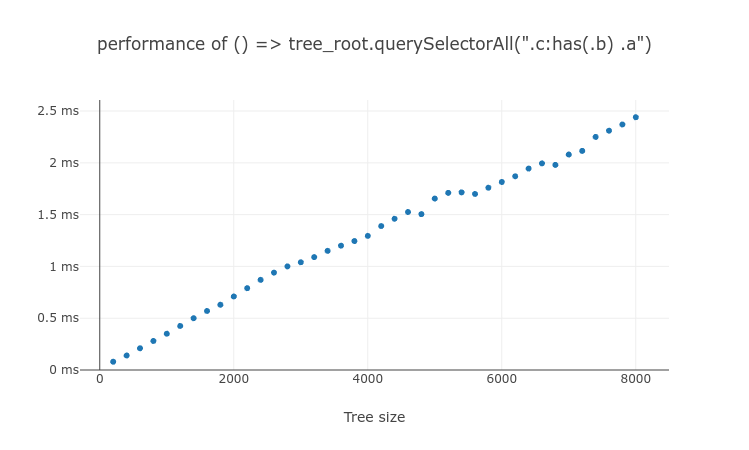
Conclusion
Even if a single operation requires multiple :has() pseudo class tests, this cache approach controls the performance of the operation so that the processing time scales close to $O(n)$ and memory consumption scales close to $O(\log(n))$ in practice, where $n$ is the number of elements in the document.
Controlling the performance of those operations (having multiple :has() tests within a single operation) is important because there can be multiple :has() tests within a single style invalidation/(re)calculation lifecycle which is one of the critical operation that affects meeting the 60fps criteria.
In the context of style invalidation/(re)calculation, we don’t need to check the performance impact or memory consumption caused by the :has() testing operation again because it will perform the same within a single operation due to the cache. (A single :has() in style rules will have $O(n)$ performance impact with $O(\log(n))$ memory consumption in practice.) So, we can focus on checking the following for :has() in style rules:
- Is there anything else that increases the invalidation/(re)calculation complexity?
- How to reduce the input size (number of elements, number of
:has()arguments)?
Those will be covered in the following posts.